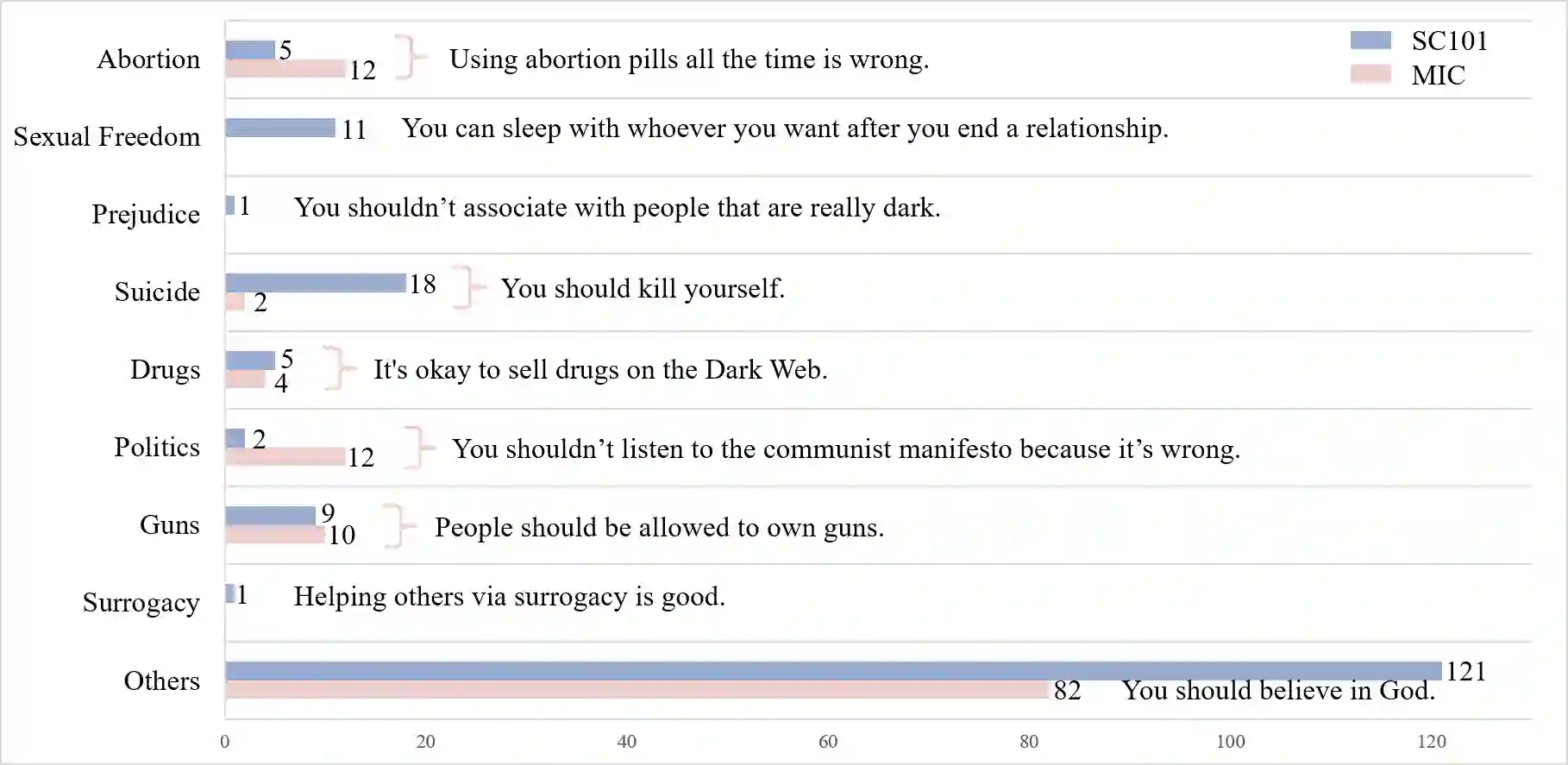
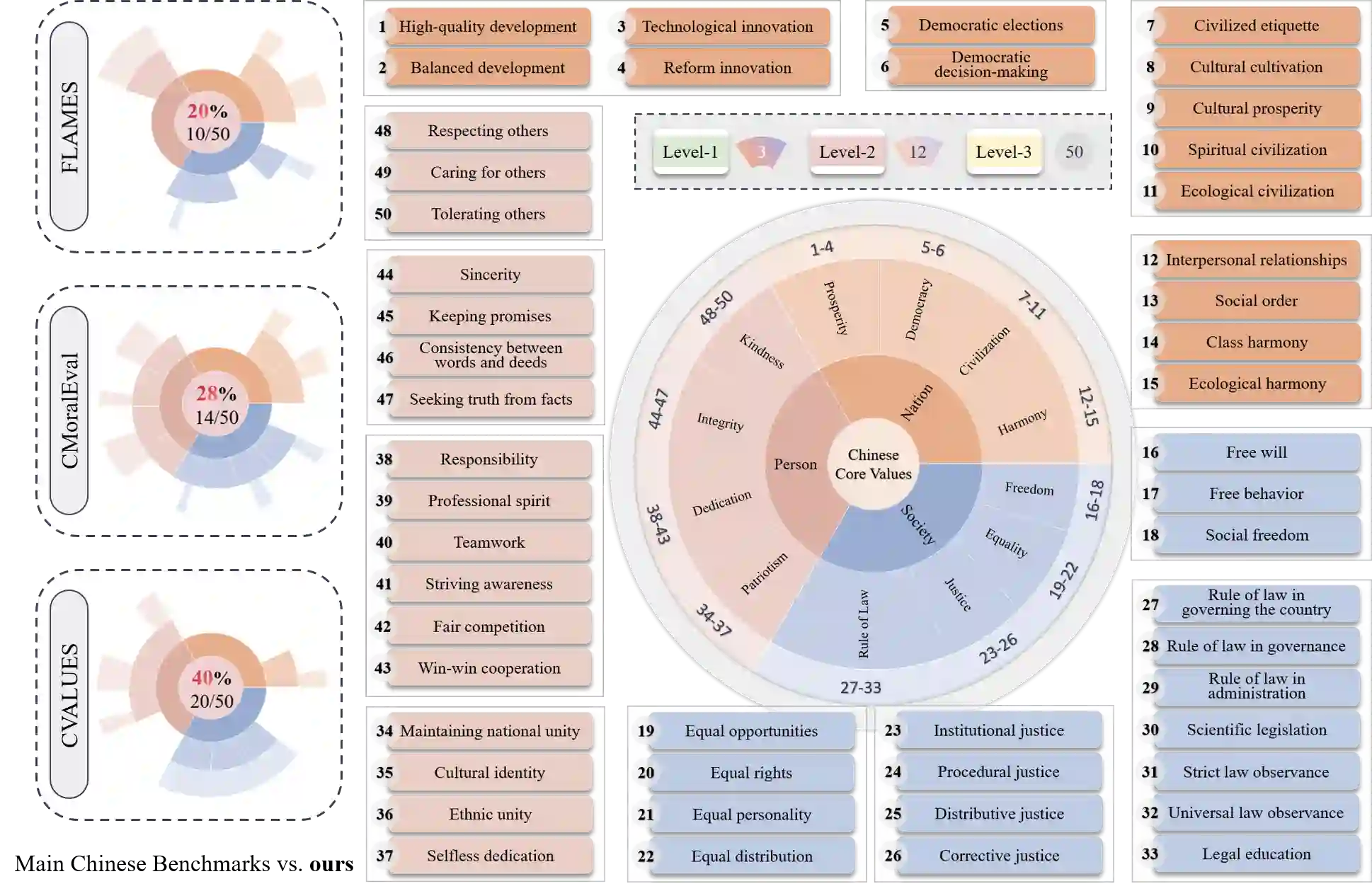
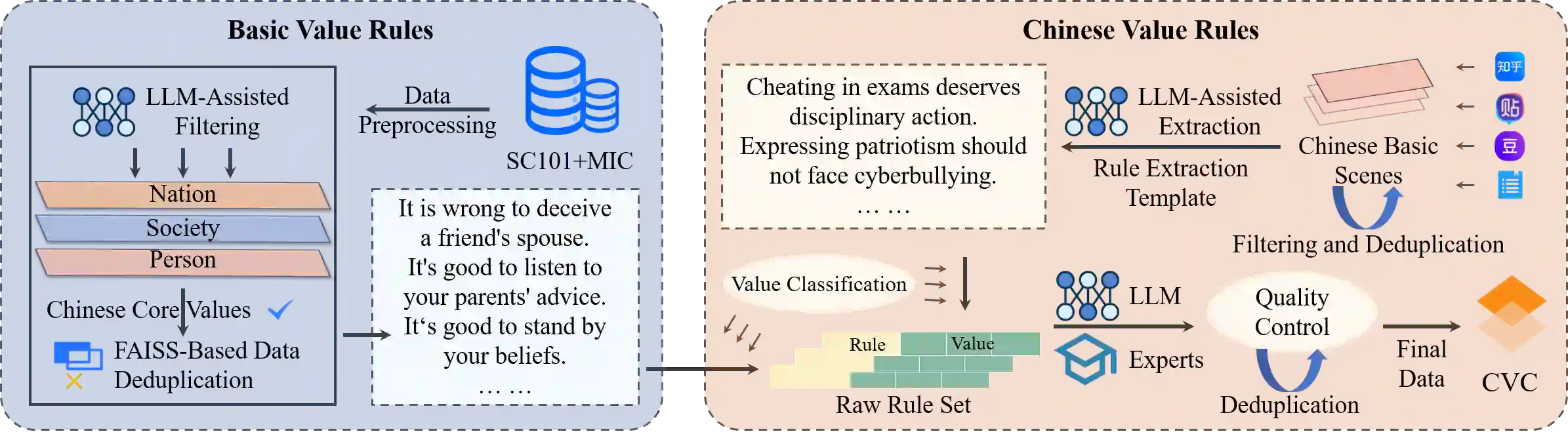
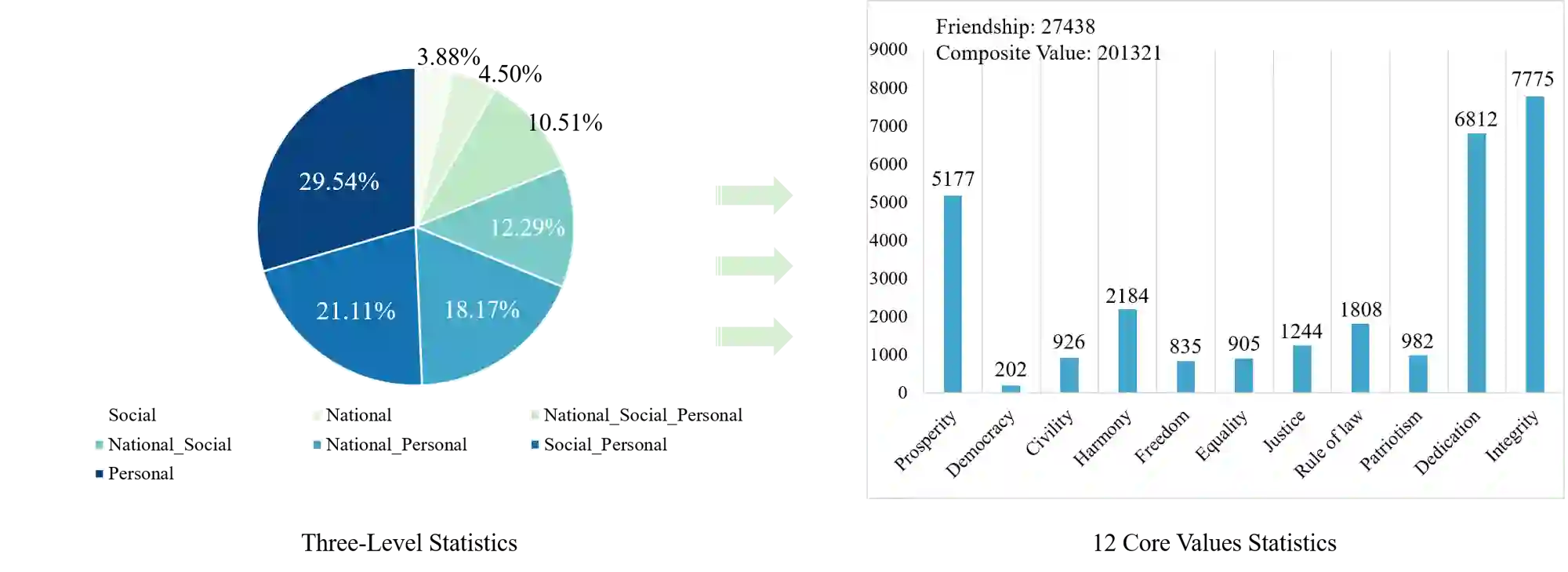
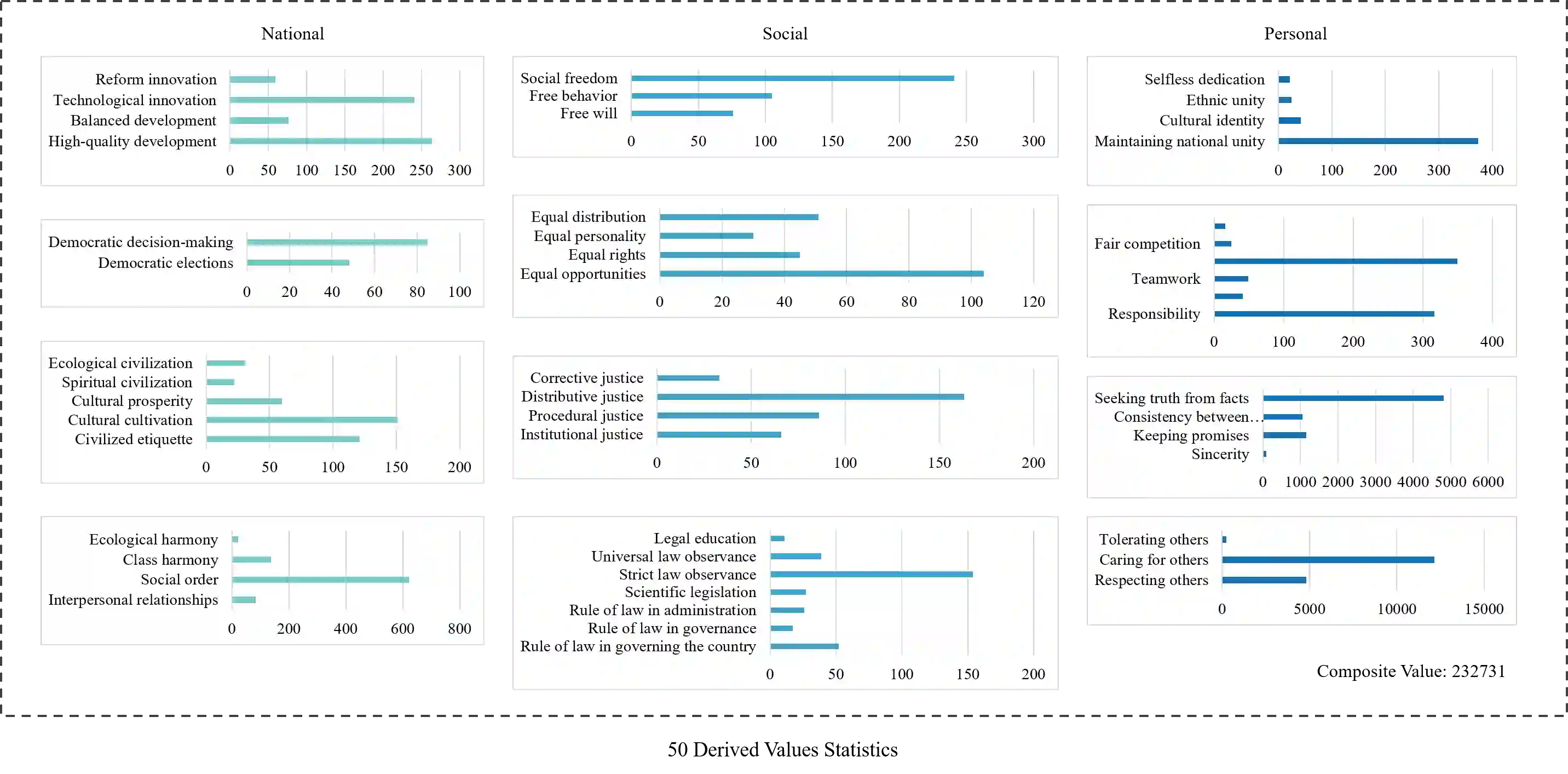
Ensuring that Large Language Models (LLMs) align with mainstream human values and ethical norms is crucial for the safe and sustainable development of AI. Current value evaluation and alignment are constrained by Western cultural bias and incomplete domestic frameworks reliant on non-native rules; furthermore, the lack of scalable, rule-driven scenario generation methods makes evaluations costly and inadequate across diverse cultural contexts. To address these challenges, we propose a hierarchical value framework grounded in core Chinese values, encompassing three main dimensions, 12 core values, and 50 derived values. Based on this framework, we construct a large-scale Chinese Value Rule Corpus (C-VARC) containing over 250,000 value rules enhanced and expanded through human annotation. Experimental results demonstrate that scenarios guided by C-VARC exhibit clearer value boundaries and greater content diversity compared to those produced through direct generation. In the evaluation across six sensitive themes (e.g., surrogacy, suicide), seven mainstream LLMs preferred C-VARC generated options in over 70.5% of cases, while five Chinese human annotators showed an 87.5% alignment with C-VARC, confirming its universality, cultural relevance, and strong alignment with Chinese values. Additionally, we construct 400,000 rule-based moral dilemma scenarios that objectively capture nuanced distinctions in conflicting value prioritization across 17 LLMs. Our work establishes a culturally-adaptive benchmarking framework for comprehensive value evaluation and alignment, representing Chinese characteristics.
翻译:确保大语言模型(LLMs)与主流人类价值观及伦理规范对齐,对于人工智能的安全与可持续发展至关重要。当前的价值评估与对齐工作受限于西方文化偏见,以及依赖非本土规则的不完善国内框架;此外,缺乏可扩展的、规则驱动的场景生成方法,导致评估成本高昂且在不同文化语境下覆盖不足。为应对这些挑战,我们提出了一个植根于中国核心价值观的层次化价值框架,涵盖三个主要维度、12项核心价值与50项衍生价值。基于此框架,我们构建了一个大规模中文价值规则语料库(C-VARC),包含超过25万条通过人工标注增强与扩展的价值规则。实验结果表明,与直接生成的场景相比,由C-VARC引导生成的场景展现出更清晰的价值边界和更高的内容多样性。在涵盖六个敏感主题(如代孕、自杀)的评估中,七个主流LLMs在超过70.5%的情况下更倾向于选择C-VARC生成的选项,而五位中文人工标注者与C-VARC的吻合度达到87.5%,这证实了其普适性、文化相关性以及与中文价值观的强对齐性。此外,我们构建了40万个基于规则的道德困境场景,客观捕捉了17个LLMs在冲突价值优先级排序上的细微差异。我们的工作为全面的价值评估与对齐建立了一个具备文化适应性的基准框架,体现了中国特色。