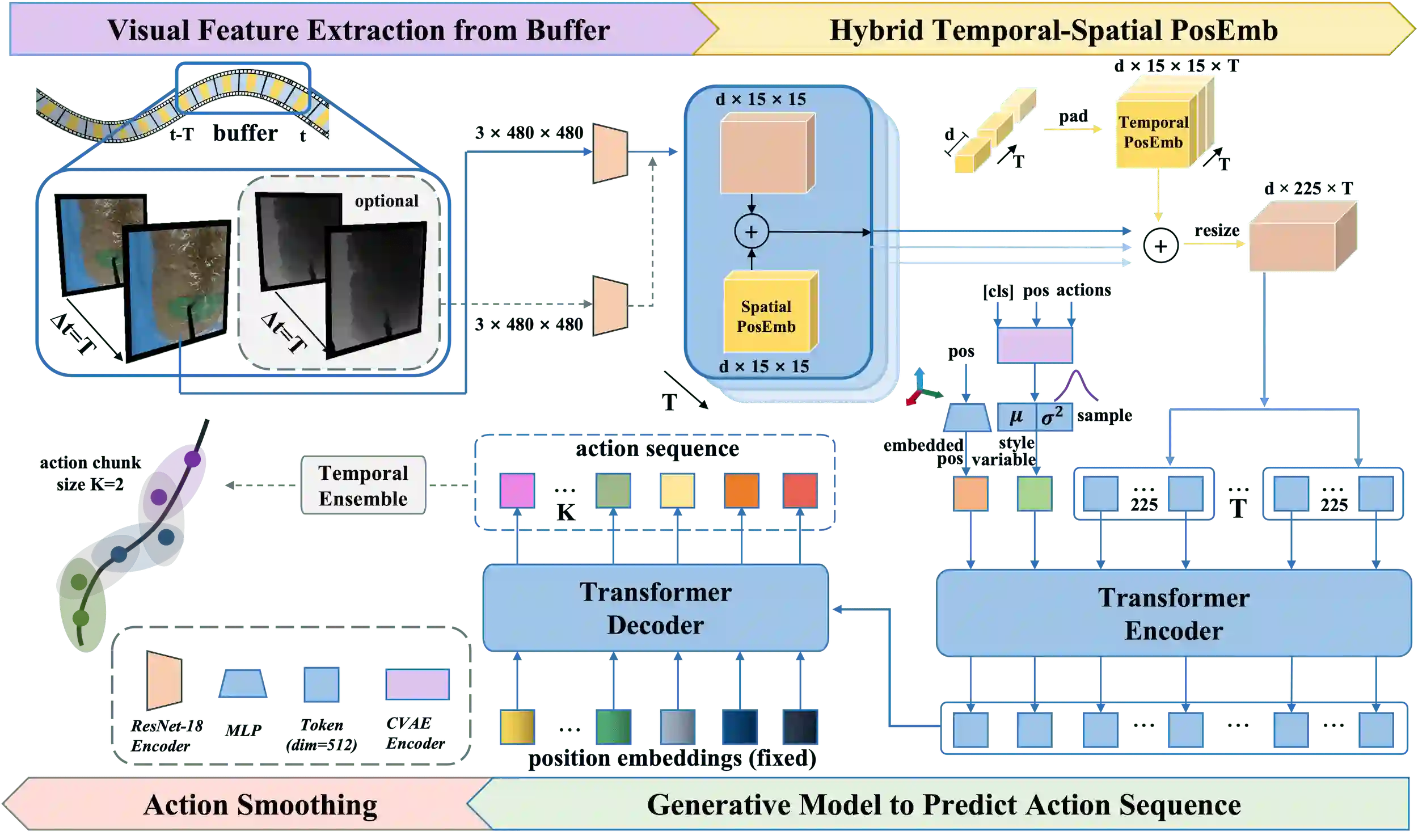
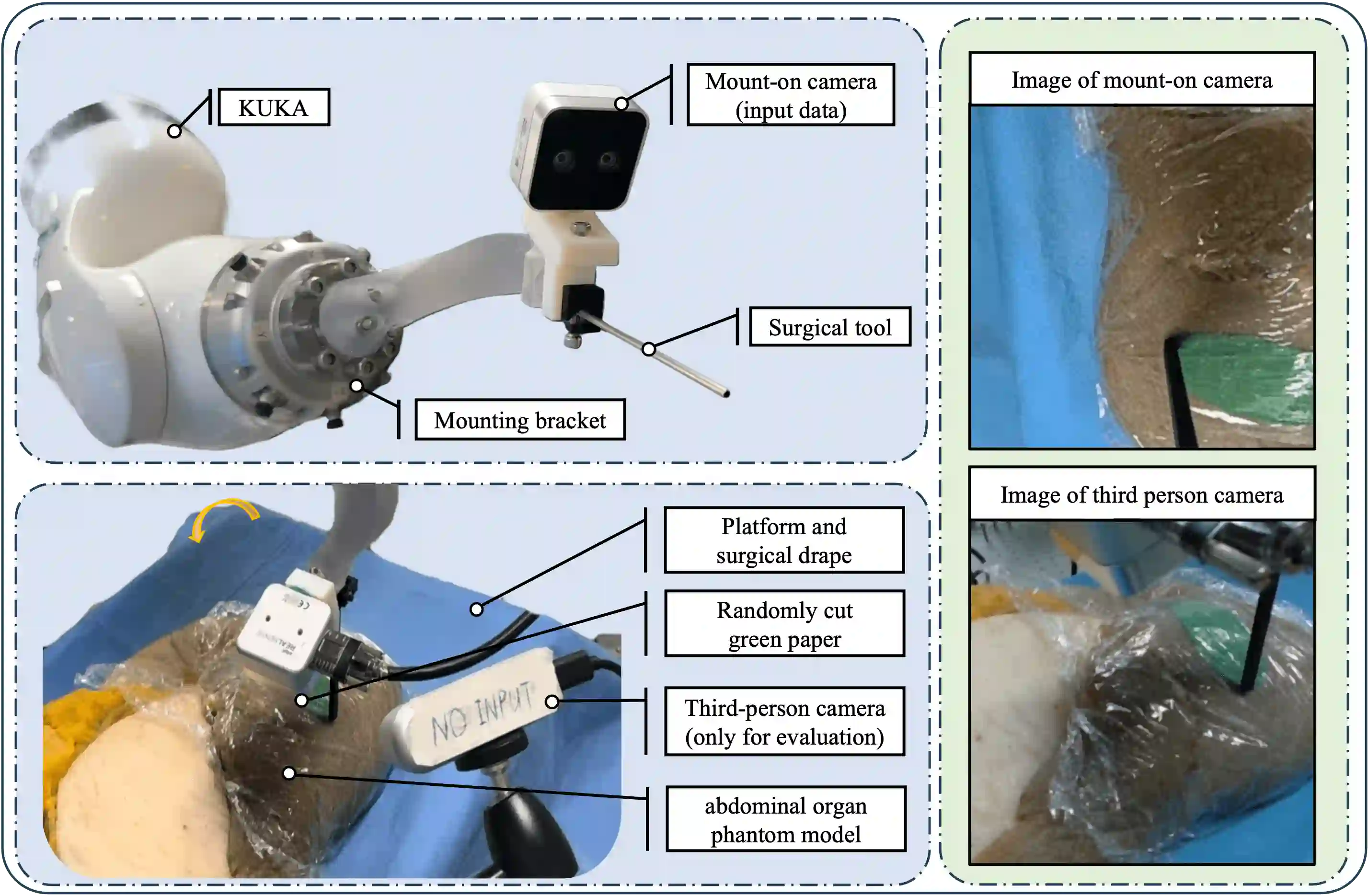
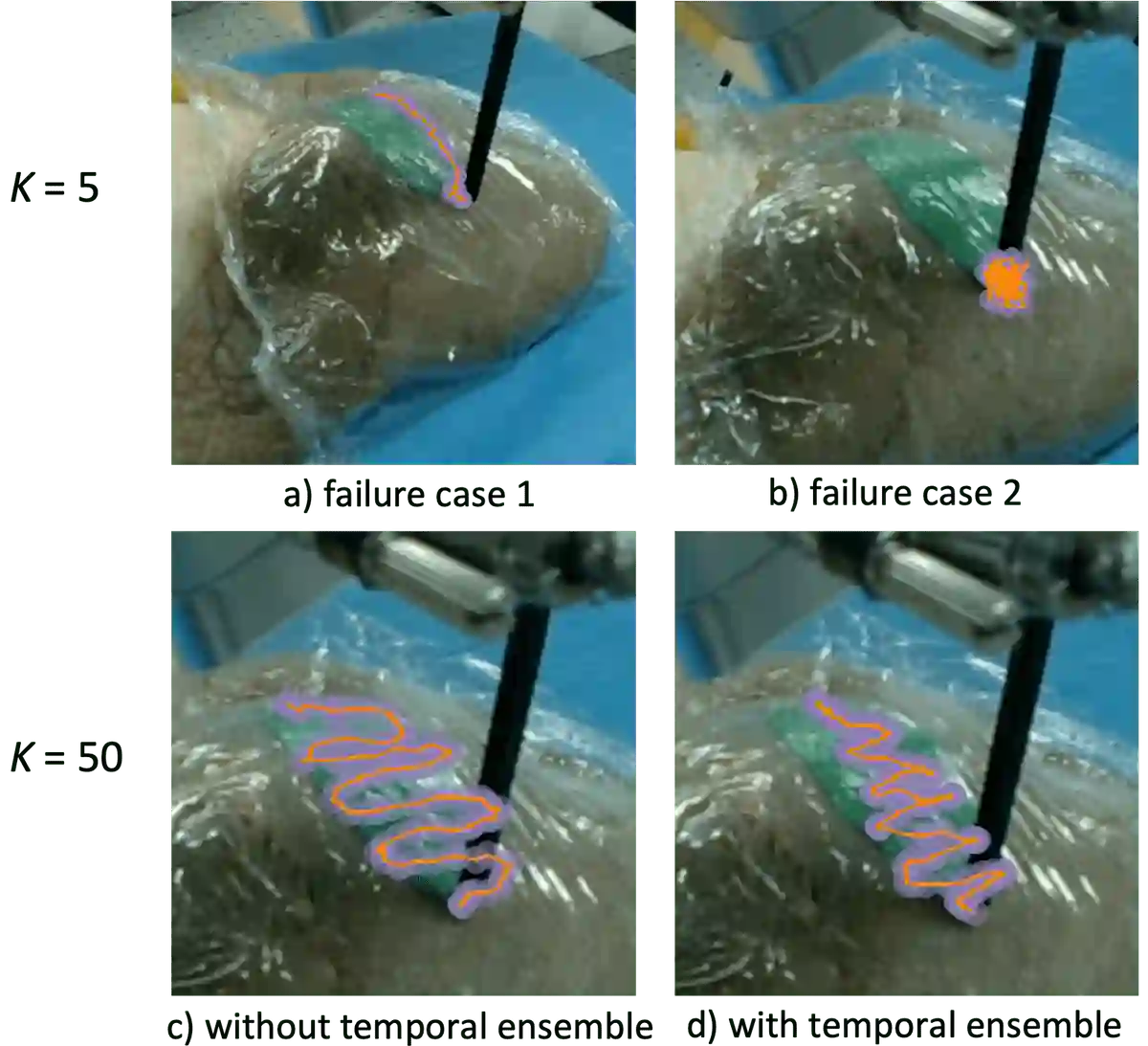
Optical sensing technologies are emerging technologies used in cancer surgeries to ensure the complete removal of cancerous tissue. While point-wise assessment has many potential applications, incorporating automated large area scanning would enable holistic tissue sampling. However, such scanning tasks are challenging due to their long-horizon dependency and the requirement for fine-grained motion. To address these issues, we introduce Memorized Action Chunking with Transformers (MACT), an intuitive yet efficient imitation learning method for tissue surface scanning tasks. It utilizes a sequence of past images as historical information to predict near-future action sequences. In addition, hybrid temporal-spatial positional embeddings were employed to facilitate learning. In various simulation settings, MACT demonstrated significant improvements in contour scanning and area scanning over the baseline model. In real-world testing, with only 50 demonstration trajectories, MACT surpassed the baseline model by achieving a 60-80% success rate on all scanning tasks. Our findings suggest that MACT is a promising model for adaptive scanning in surgical settings.
翻译:光学传感技术是癌症手术中确保癌变组织完全切除的新兴技术。虽然逐点评估具有多种潜在应用,但引入自动化大范围扫描将实现整体组织采样。然而,此类扫描任务因其长时程依赖性和精细运动要求而具有挑战性。为解决这些问题,我们提出了基于Transformer的记忆动作分块方法——一种直观高效的面向组织表面扫描任务的模仿学习方法。该方法利用连续历史图像序列作为时序信息来预测近期动作序列。此外,通过引入混合时空位置编码以促进学习。在多种仿真环境中,MACT在轮廓扫描与区域扫描任务上均展现出相较于基线模型的显著改进。在真实世界测试中,仅使用50条示范轨迹,MACT在所有扫描任务中实现了60-80%的成功率,全面超越基线模型。我们的研究表明,MACT是手术场景中自适应扫描的潜力模型。