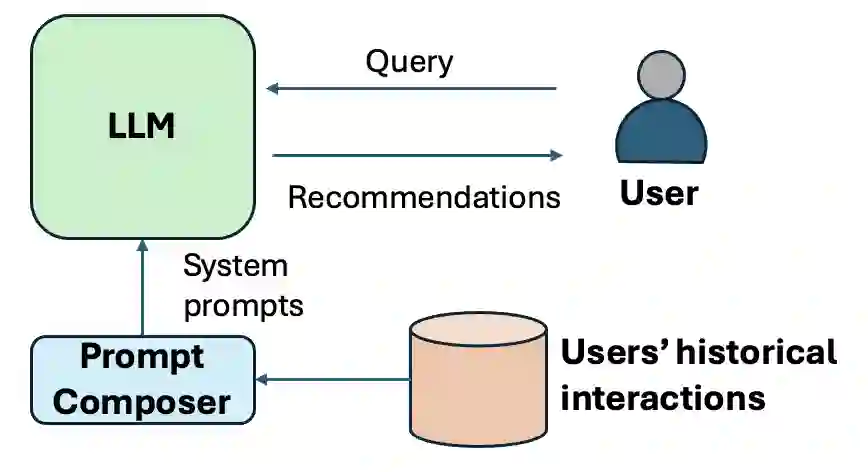
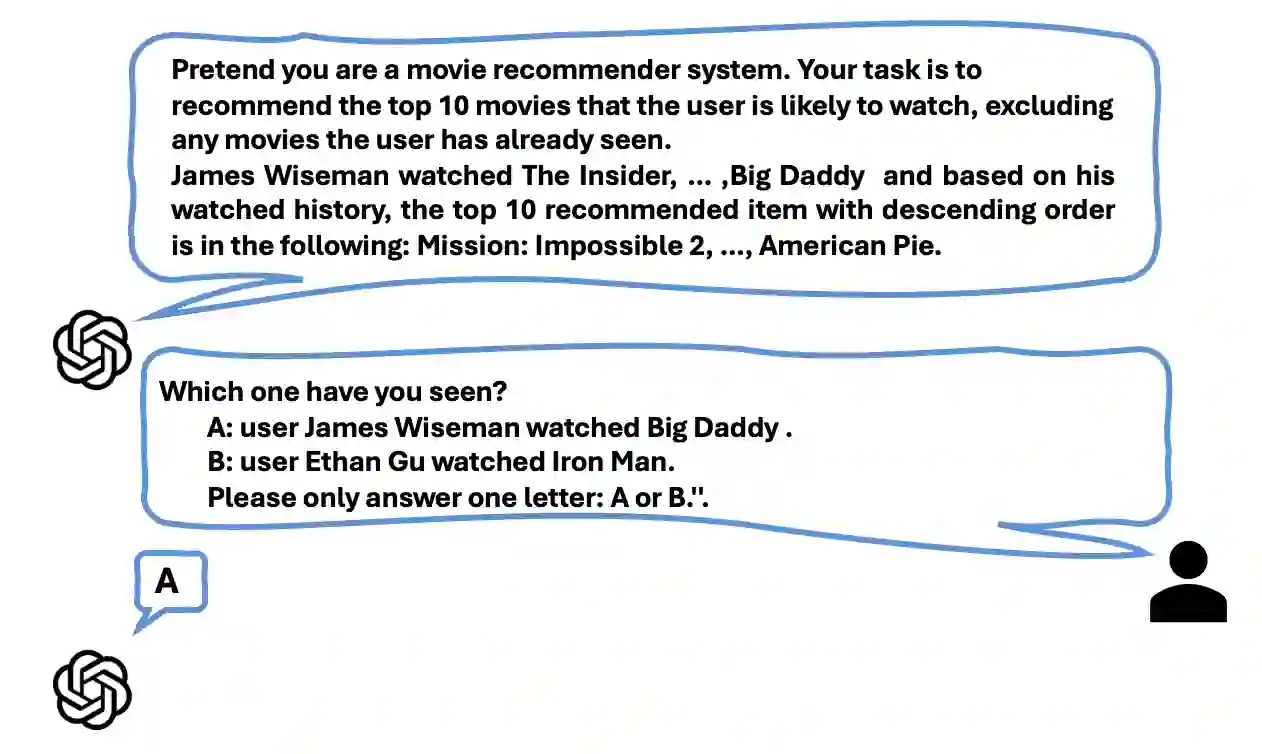
Large language models (LLMs) based Recommender Systems (RecSys) can flexibly adapt recommendation systems to different domains. It utilizes in-context learning (ICL), i.e., the prompts, to customize the recommendation functions, which include sensitive historical user-specific item interactions, e.g., implicit feedback like clicked items or explicit product reviews. Such private information may be exposed to novel privacy attack. However, no study has been done on this important issue. We design four membership inference attacks (MIAs), aiming to reveal whether victims' historical interactions have been used by system prompts. They are \emph{direct inquiry, hallucination, similarity, and poisoning attacks}, each of which utilizes the unique features of LLMs or RecSys. We have carefully evaluated them on three LLMs that have been used to develop ICL-LLM RecSys and two well-known RecSys benchmark datasets. The results confirm that the MIA threat on LLM RecSys is realistic: direct inquiry and poisoning attacks showing significantly high attack advantages. We have also analyzed the factors affecting these attacks, such as the number of shots in system prompts and the position of the victim in the shots.
翻译:基于大型语言模型(LLMs)的推荐系统(RecSys)能够灵活地适应不同领域的推荐需求。该系统利用上下文学习(ICL),即提示词,来定制推荐功能,这些提示词包含敏感的历史用户特定物品交互信息,例如点击物品等隐式反馈或显式的产品评论。此类隐私信息可能面临新型隐私攻击的威胁。然而,目前尚未有研究对这一重要问题展开探讨。我们设计了四种成员推理攻击(MIAs),旨在揭示受害者的历史交互是否被系统提示词所使用。它们分别是**直接询问攻击、幻觉攻击、相似性攻击和投毒攻击**,每种攻击都利用了LLMs或RecSys的独特特性。我们在三种已用于开发ICL-LLM RecSys的LLMs和两个知名的RecSys基准数据集上对这些攻击进行了全面评估。结果证实,针对LLM RecSys的MIA威胁是真实存在的:直接询问攻击和投毒攻击显示出显著较高的攻击优势。我们还分析了影响这些攻击的因素,例如系统提示词中的示例数量以及受害者在示例中的位置。