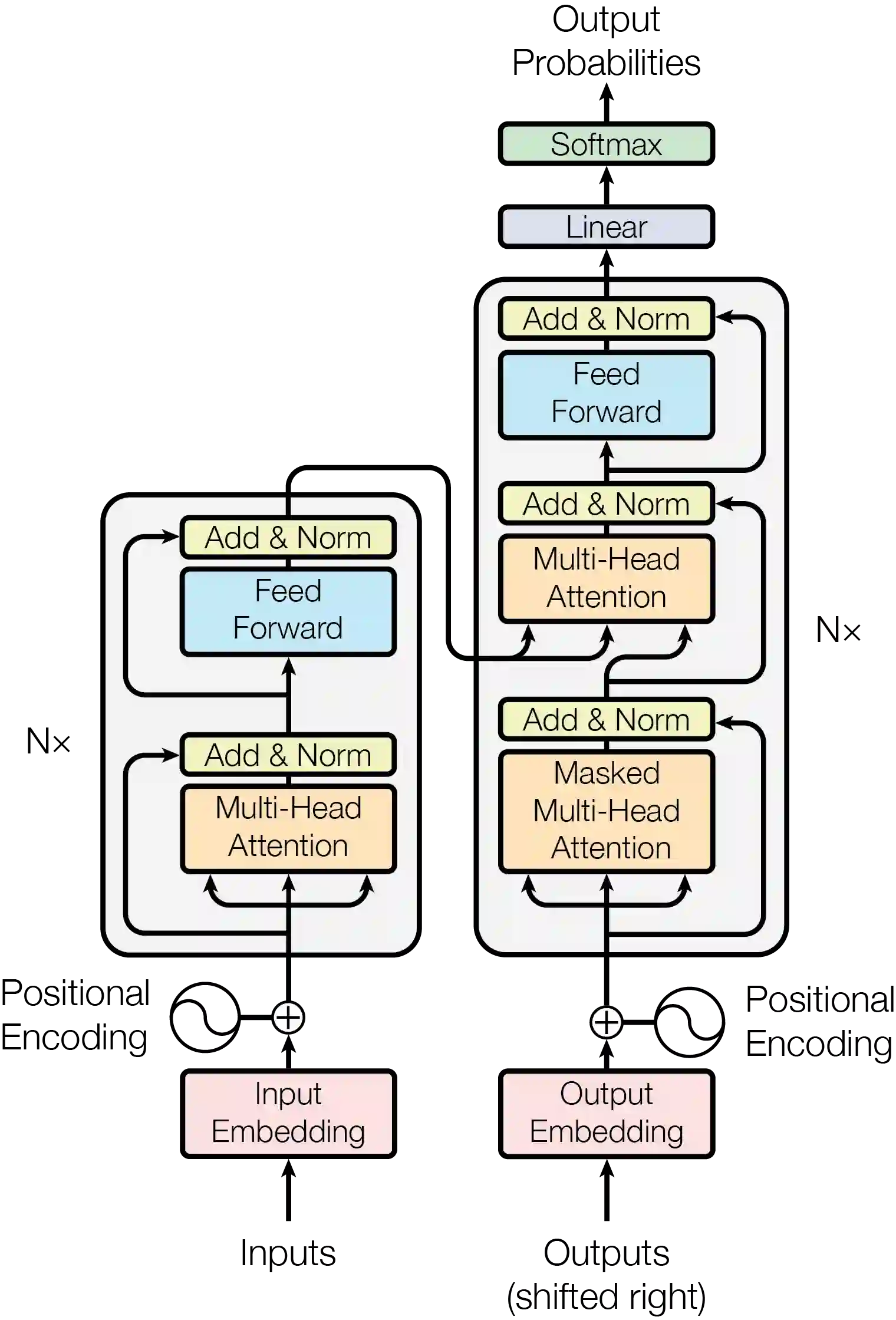
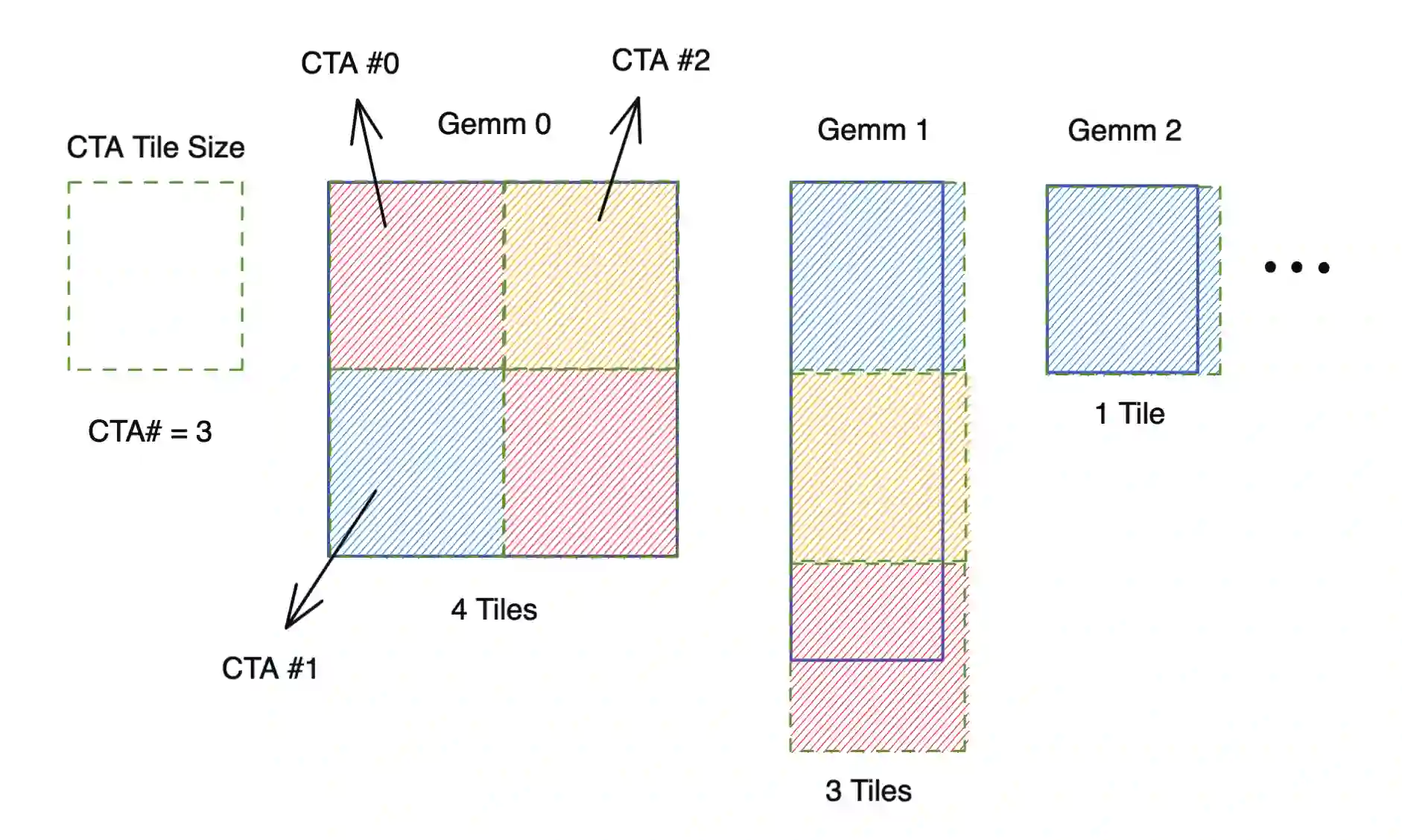
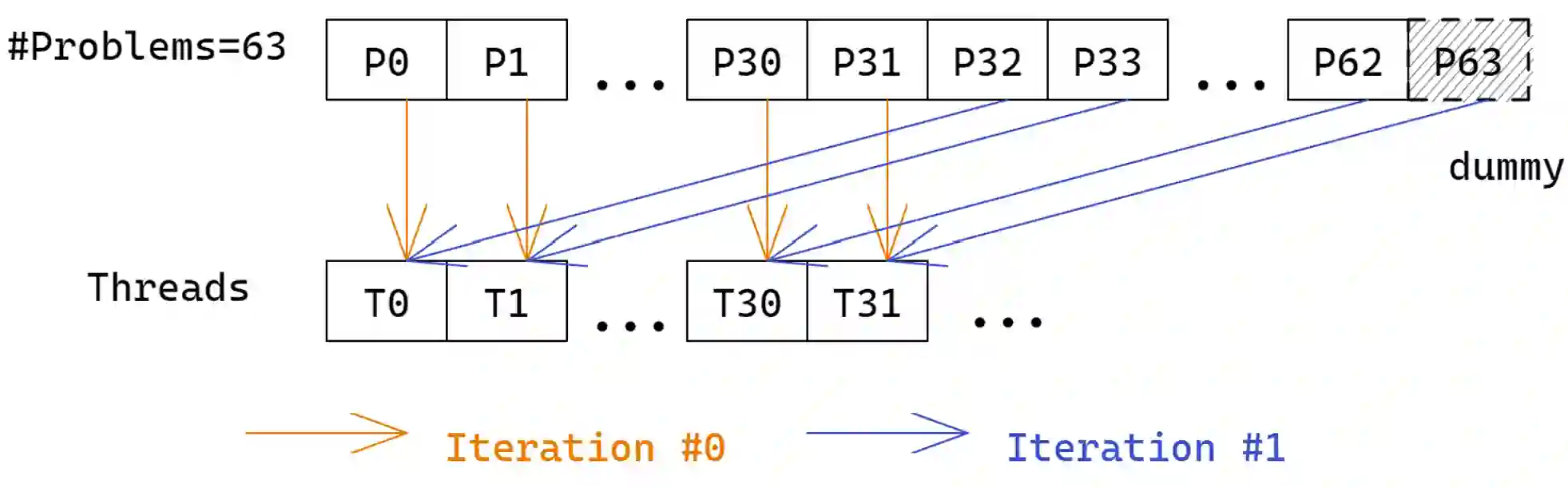
Transformer is the cornerstone model of Natural Language Processing (NLP) over the past decade. Despite its great success in Deep Learning (DL) applications, the increasingly growing parameter space required by transformer models boosts the demand on accelerating the performance of transformer models. In addition, NLP problems can commonly be faced with variable-length sequences since their word numbers can vary among sentences. Existing DL frameworks need to pad variable-length sequences to the maximal length, which, however, leads to significant memory and computational overhead. In this paper, we present ByteTransformer, a high-performance transformer boosted for variable-length inputs. We propose a zero padding algorithm that enables the whole transformer to be free from redundant computations on useless padded tokens. Besides the algorithmic level optimization, we provide architectural-aware optimizations for transformer functioning modules, especially the performance-critical algorithm, multi-head attention (MHA). Experimental results on an NVIDIA A100 GPU with variable-length sequence inputs validate that our fused MHA (FMHA) outperforms the standard PyTorch MHA by 6.13X. The end-to-end performance of ByteTransformer for a standard BERT transformer model surpasses the state-of-the-art Transformer frameworks, such as PyTorch JIT, TensorFlow XLA, Tencent TurboTransformer and NVIDIA FasterTransformer, by 87\%, 131\%, 138\% and 46\%, respectively.
翻译:变异器是过去十年里自然语言处理(NLP)的基石模型。 尽管变异器模型在深学习(DL)应用中取得了巨大成功, 但变异器模型所需的日益扩大的参数空间却提高了加速变异器模型性能的需求。 此外, 变异序列通常会遇到变长序列问题, 因为其单数在句子上各有差异。 现有的DL框架需要将变异长序列粘贴在最大长度上, 但是这会导致重要的记忆和计算管理管理。 在本文中, 我们展示了“ 变异变异式变异器”, 一个高性能变异器加速了变异器投入。 我们提出一个零拼换算法, 使整个变异器能够摆脱无用的加价符号上的重复计算。 除了算法层面的优化之外, 我们还为变异器功能模块提供建筑认知优化, 特别是性能临界算法, 多头关注(MAHA) 。 NVIDIA A100 GPU 和变异序列输入的实验结果证实, 我们的MHA(FA) 混编装的比标准的JyTotar-TAR TRAT- Transl- TRA- TRATI- TRA- TRA- TRA- TRA- TRADRVER-T 和6-T-T-T-T- TRA- TRA-T-T-T-T-T- TRA- TRA- TRA-T-T-T- TRAVAR 6-T-T-T-T-T-T-TIR-T-T- TRA- TRATIW 和6-T-T-T-T-TIR-T-T-TRVR-T-T-T-T-T-T-T-T-T-T-T-T-T-T-TR-T-T-T-T-TRVDRVL-SIR 和6-T-T-T-SAR-T-T-T-6-T-T-T-T-T-T-T-T-T-T-T-S-T-T-T-T-T-T-S-S-S-S-T-T-T-T-T