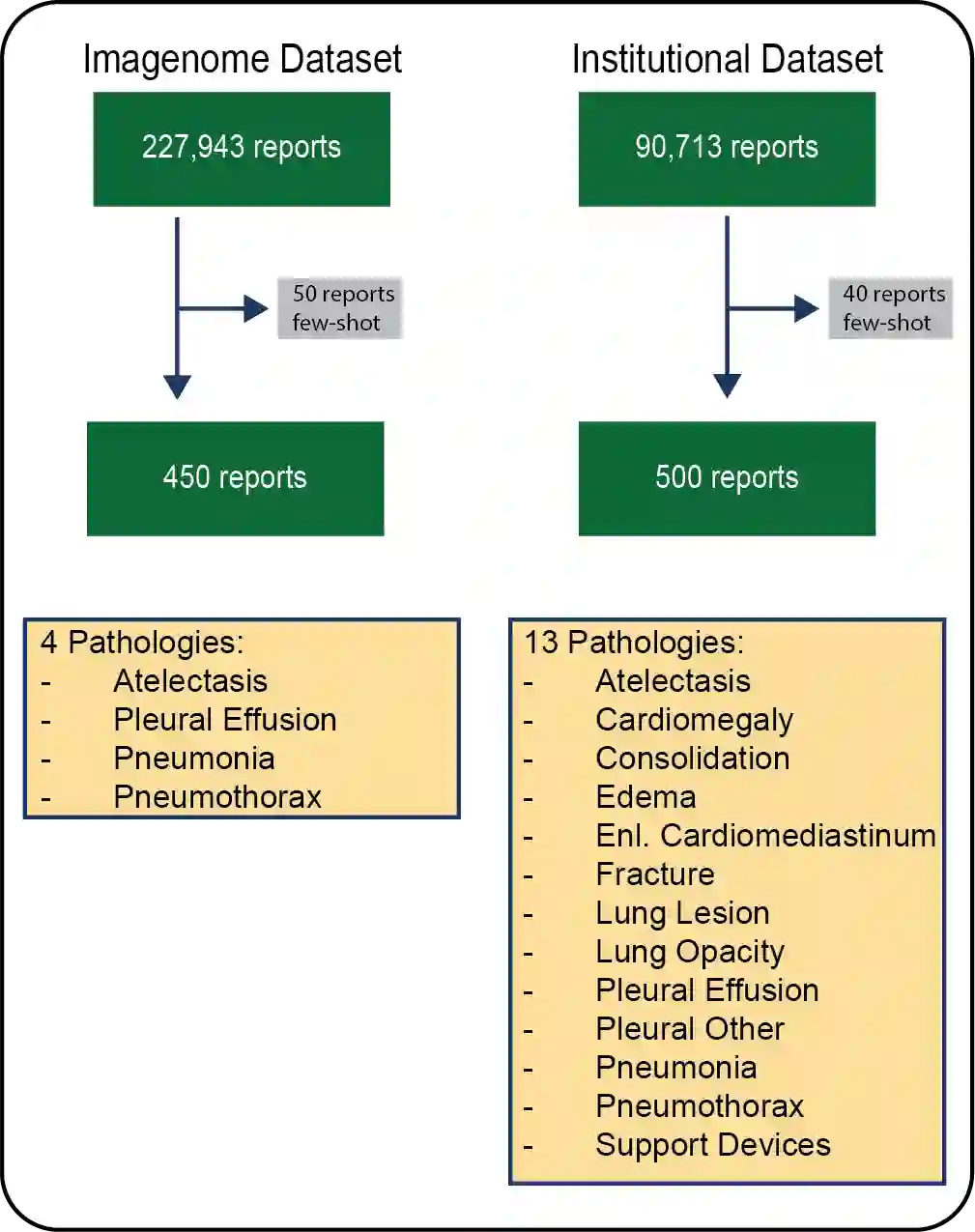
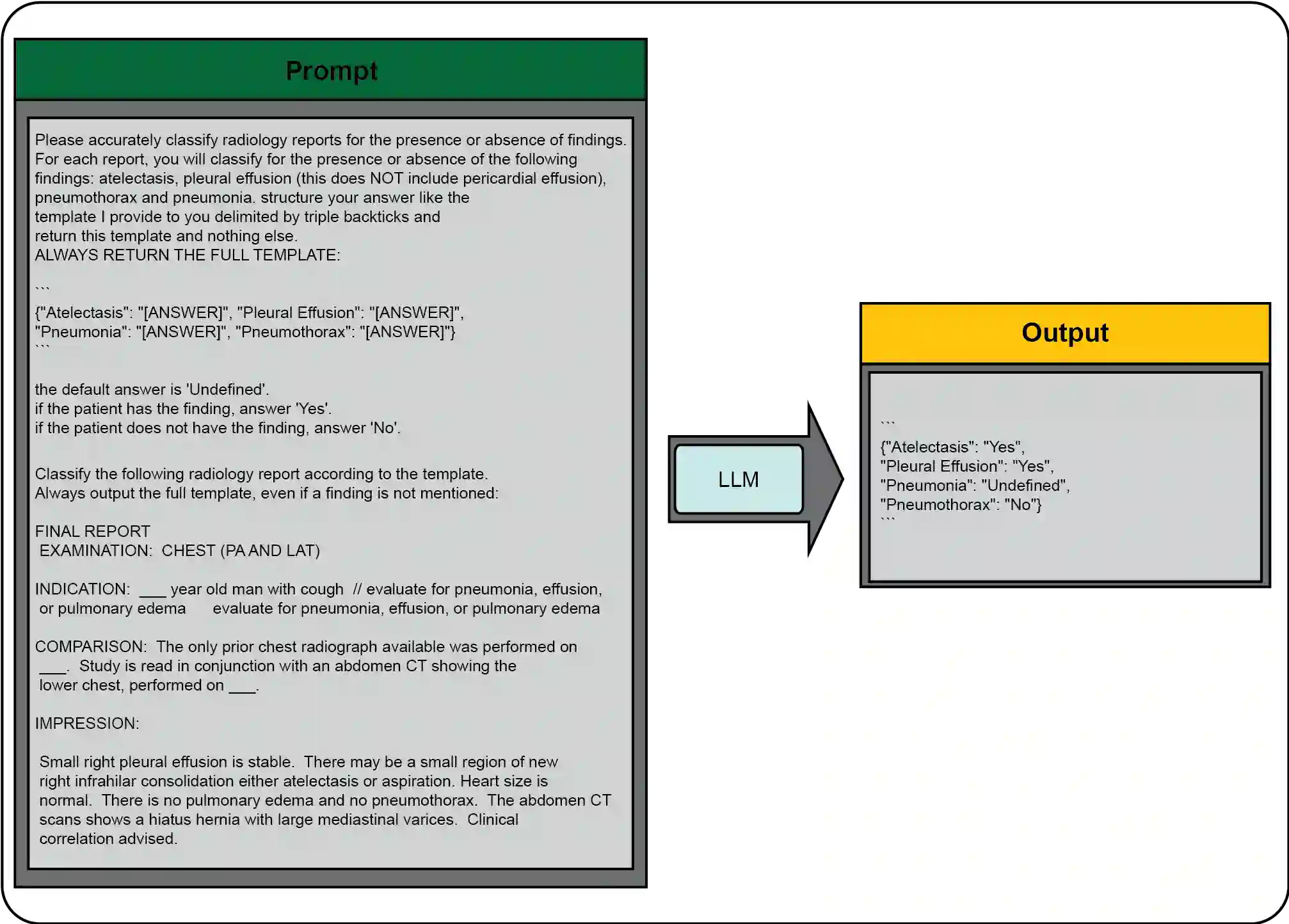
Introduction: With the rapid advances in large language models (LLMs), there have been numerous new open source as well as commercial models. While recent publications have explored GPT-4 in its application to extracting information of interest from radiology reports, there has not been a real-world comparison of GPT-4 to different leading open-source models. Materials and Methods: Two different and independent datasets were used. The first dataset consists of 540 chest x-ray reports that were created at the Massachusetts General Hospital between July 2019 and July 2021. The second dataset consists of 500 chest x-ray reports from the ImaGenome dataset. We then compared the commercial models GPT-3.5 Turbo and GPT-4 from OpenAI to the open-source models Mistral-7B, Mixtral-8x7B, Llama2-13B, Llama2-70B, QWEN1.5-72B and CheXbert and CheXpert-labeler in their ability to accurately label the presence of multiple findings in x-ray text reports using different prompting techniques. Results: On the ImaGenome dataset, the best performing open-source model was Llama2-70B with micro F1-scores of 0.972 and 0.970 for zero- and few-shot prompts, respectively. GPT-4 achieved micro F1-scores of 0.975 and 0.984, respectively. On the institutional dataset, the best performing open-source model was QWEN1.5-72B with micro F1-scores of 0.952 and 0.965 for zero- and few-shot prompting, respectively. GPT-4 achieved micro F1-scores of 0.975 and 0.973, respectively. Conclusion: In this paper, we show that while GPT-4 is superior to open-source models in zero-shot report labeling, the implementation of few-shot prompting can bring open-source models on par with GPT-4. This shows that open-source models could be a performant and privacy preserving alternative to GPT-4 for the task of radiology report classification.
翻译:引言:随着大语言模型的快速发展,众多新型开源及商业模型不断涌现。近期研究虽已探索GPT-4在放射学报告中提取目标信息的应用,但尚未有研究将GPT-4与主流开源模型进行真实场景对比。材料与方法:本研究采用两个独立数据集。第一个数据集包含540份于2019年7月至2021年7月间在马萨诸塞州总医院生成的胸部X光报告,第二个数据集包含来自ImaGenome数据集的500份胸部X光报告。我们通过不同提示策略,对比了OpenAI商业模型GPT-3.5 Turbo与GPT-4、开源模型Mistral-7B、Mixtral-8x7B、Llama2-13B、Llama2-70B、QWEN1.5-72B以及CheXbert和CheXpert-labeler在X光文本报告中对多种发现进行准确标注的能力。结果:在ImaGenome数据集上,性能最优的开源模型为Llama2-70B,其零样本和少样本提示的微平均F1分数分别为0.972和0.970;GPT-4对应分数为0.975和0.984。在机构数据集上,性能最优的开源模型为QWEN1.5-72B,其零样本和少样本提示的微平均F1分数分别为0.952和0.965;GPT-4对应分数为0.975和0.973。结论:本研究表明,尽管GPT-4在零样本报告标注中优于开源模型,但采用少样本提示策略可使开源模型达到与GPT-4相当的性能。这表明在放射学报告分类任务中,开源模型可以作为兼具高性能与隐私保护特性的GPT-4替代方案。