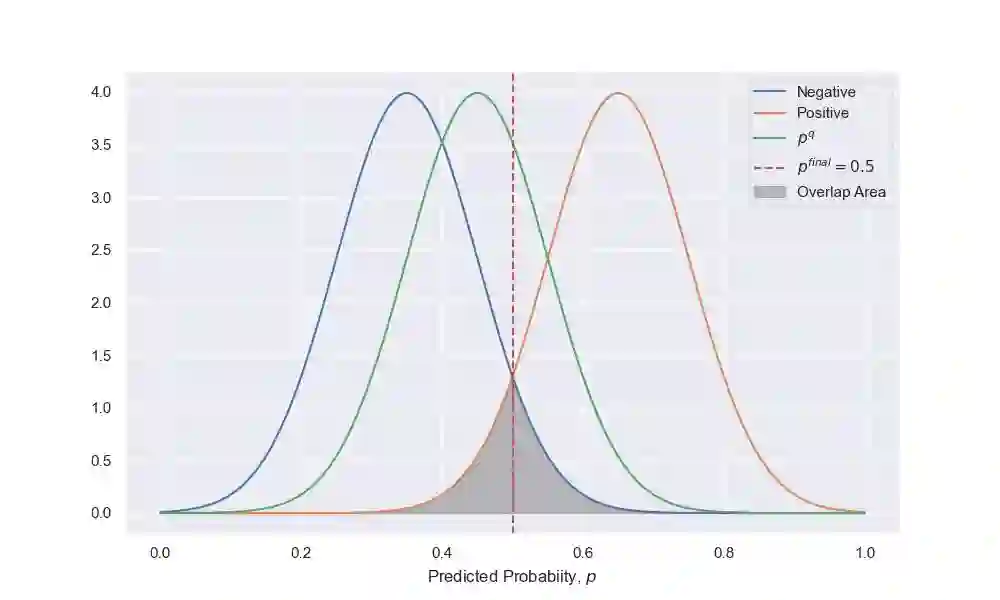
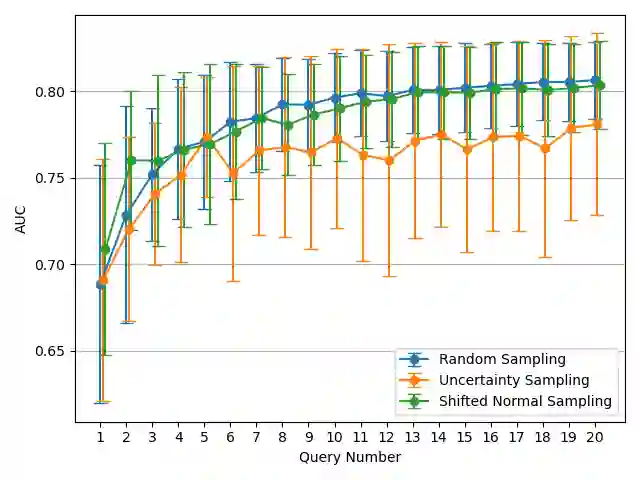
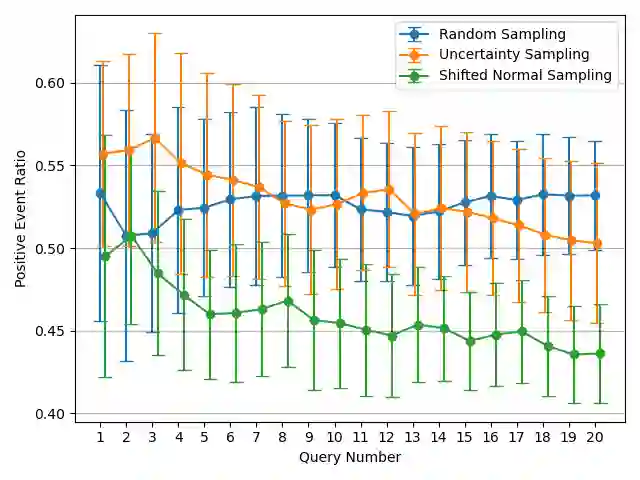
Active learning is a learning strategy whereby the machine learning algorithm actively identifies and labels data points to optimize its learning. This strategy is particularly effective in domains where an abundance of unlabeled data exists, but the cost of labeling these data points is prohibitively expensive. In this paper, we consider cases of binary classification, where acquiring a positive instance incurs a significantly higher cost compared to that of negative instances. For example, in the financial industry, such as in money-lending businesses, a defaulted loan constitutes a positive event leading to substantial financial loss. To address this issue, we propose a shifted normal distribution sampling function that samples from a wider range than typical uncertainty sampling. Our simulation underscores that our proposed sampling function limits both noisy and positive label selection, delivering between 20% and 32% improved cost efficiency over different test datasets.
翻译:主动学习是一种学习策略,其中机器学习算法主动识别并标注数据点以优化其学习过程。该策略在存在大量未标注数据但标注成本过高的领域中尤为有效。本文考虑二元分类场景,其中获取正例样本的成本显著高于负例样本。例如,在金融行业(如放贷业务)中,违约贷款构成正例事件,会导致重大财务损失。为解决这一问题,我们提出一种偏移正态分布采样函数,该函数比传统的不确定性采样覆盖更广的采样范围。模拟实验表明,所提出的采样函数能够限制噪声样本和正例样本的选择,在不同测试数据集上实现20%至32%的成本效率提升。