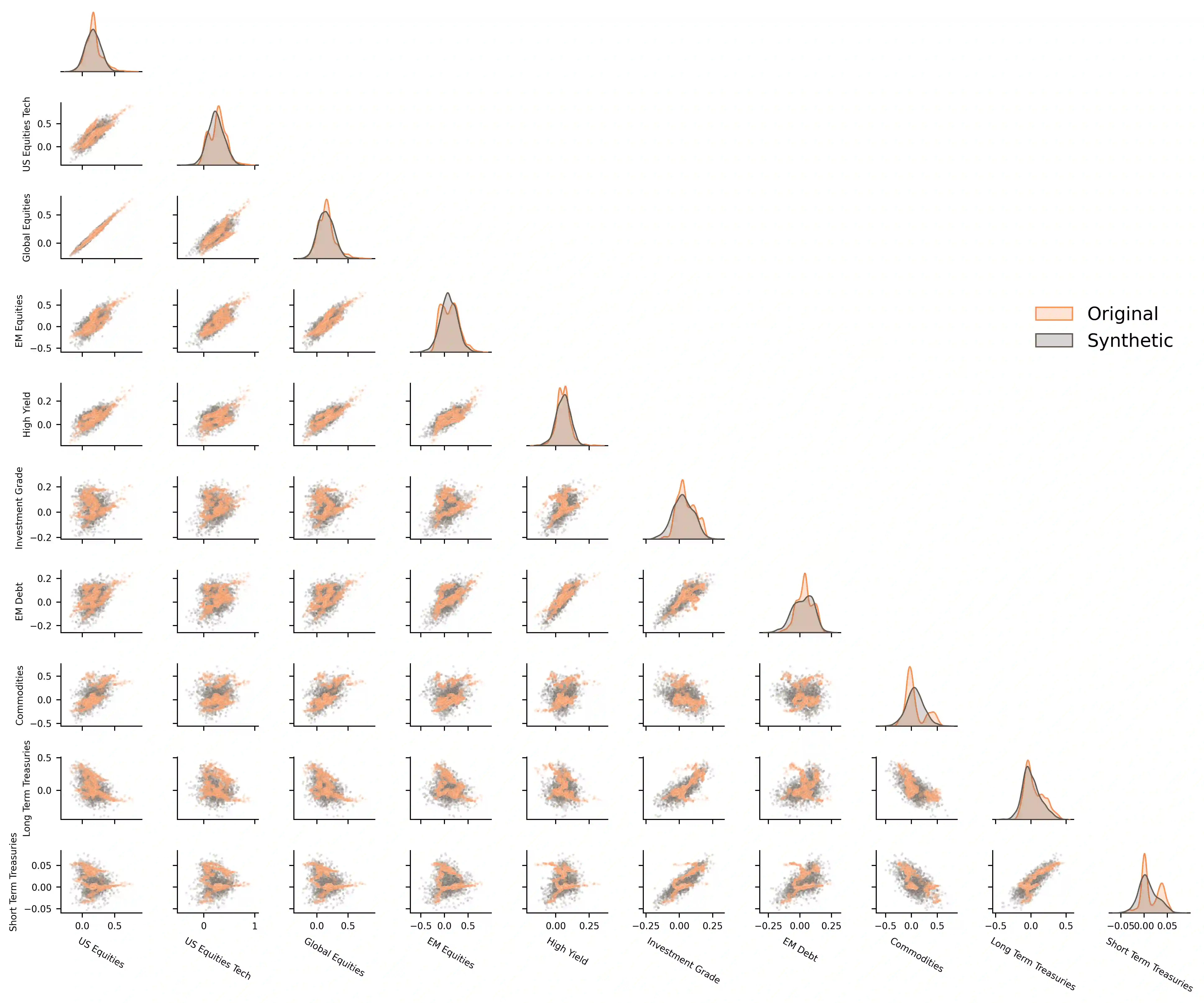
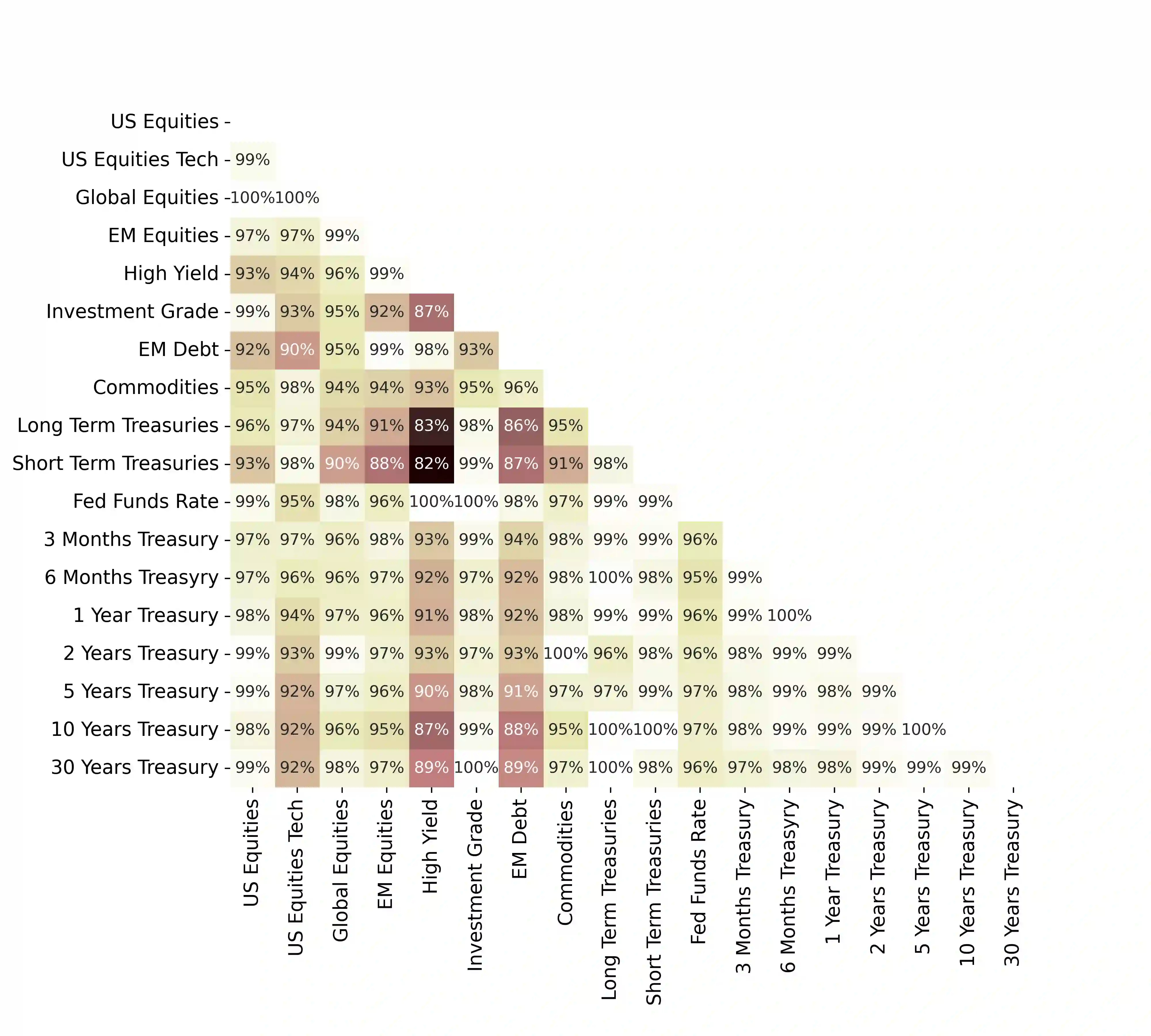
We propose a new approach to portfolio optimization that utilizes a unique combination of synthetic data generation and a CVaR-constraint. We formulate the portfolio optimization problem as an asset allocation problem in which each asset class is accessed through a passive (index) fund. The asset-class weights are determined by solving an optimization problem which includes a CVaR-constraint. The optimization is carried out by means of a Modified CTGAN algorithm which incorporates features (contextual information) and is used to generate synthetic return scenarios, which, in turn, are fed into the optimization engine. For contextual information we rely on several points along the U.S. Treasury yield curve. The merits of this approach are demonstrated with an example based on ten asset classes (covering stocks, bonds, and commodities) over a fourteen-and-half year period (January 2008-June 2022). We also show that the synthetic generation process is able to capture well the key characteristics of the original data, and the optimization scheme results in portfolios that exhibit satisfactory out-of-sample performance. We also show that this approach outperforms the conventional equal-weights (1/N) asset allocation strategy and other optimization formulations based on historical data only.
翻译:我们提出了一种新的投资组合优化方法,该方法利用合成数据生成与CVaR约束的独特组合。我们将投资组合优化问题表述为资产配置问题,其中每类资产通过被动(指数)基金进行投资。资产类别权重通过求解包含CVaR约束的优化问题来确定。优化过程采用改进型CTGAN算法实现,该算法融合了特征(上下文信息)用于生成合成回报情景,这些情景随后输入优化引擎。在上下文信息方面,我们依赖于美国国债收益率曲线上的多个点位。通过一个涵盖十类资产(包括股票、债券和大宗商品)、跨越十四年半(2008年1月至2022年6月)的案例,验证了该方法的优势。我们还表明,合成生成过程能够很好地捕捉原始数据的关键特征,且优化方案生成的组合展现出令人满意的样本外表现。此外,该方法优于传统的等权重(1/N)资产配置策略以及仅基于历史数据的其他优化方案。