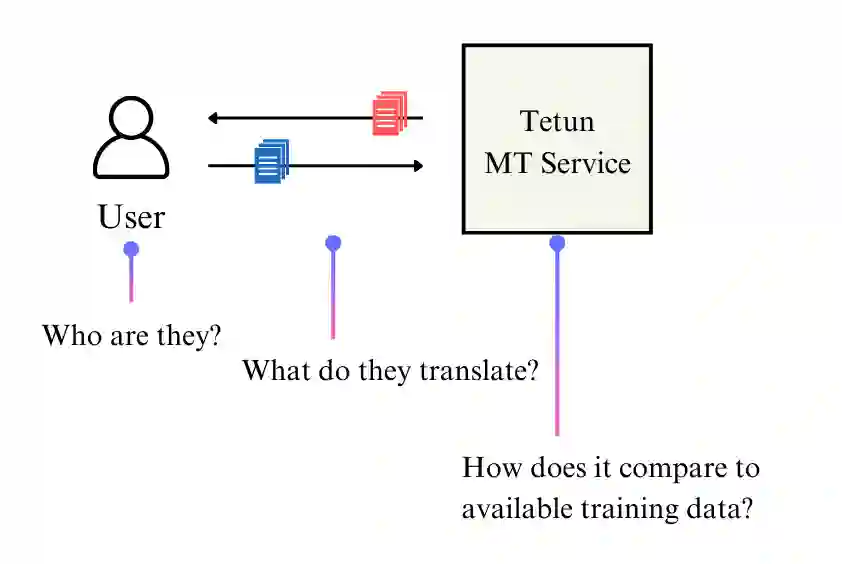
Low-resource machine translation (MT) presents a diversity of community needs and application challenges that remain poorly understood. To complement surveys and focus groups, which tend to rely on small samples of respondents, we propose an observational study on actual usage patterns of tetun$.$org, a specialized MT service for the Tetun language, which is the lingua franca in Timor-Leste. Our analysis of 100,000 translation requests reveals patterns that challenge assumptions based on existing corpora. We find that users, many of them students on mobile devices, typically translate text from a high-resource language into Tetun across diverse domains including science, healthcare, and daily life. This contrasts sharply with available Tetun corpora, which are dominated by news articles covering government and social issues. Our results suggest that MT systems for institutionalized minority languages like Tetun should prioritize accuracy on domains relevant to educational contexts, in the high-resource to low-resource direction. More broadly, this study demonstrates how observational analysis can inform low-resource language technology development, by grounding research in practical community needs.
翻译:低资源机器翻译(MT)呈现出多样化的社区需求与应用挑战,而目前对此理解仍显不足。为补充通常依赖小样本受访者的调查和焦点小组研究,我们针对tetun.org(一个为东帝汶通用语——德顿语提供的专业机器翻译服务)的实际使用模式开展了一项观察性研究。通过对10万条翻译请求的分析,我们发现了挑战基于现有语料库假设的使用模式。研究发现,用户(其中许多是使用移动设备的学生)通常将高资源语言(如英语)的文本翻译成德顿语,涉及领域广泛,包括科学、医疗保健和日常生活。这与现有德顿语料库形成鲜明对比,后者以涵盖政府和社会议题的新闻报道为主。我们的结果表明,针对如德顿语这类制度化少数语言的机器翻译系统,应优先保证高资源语言到低资源语言方向在教育相关领域翻译的准确性。更广泛而言,本研究通过将研究立足于实际社区需求,展示了观察性分析如何能为低资源语言技术发展提供信息依据。