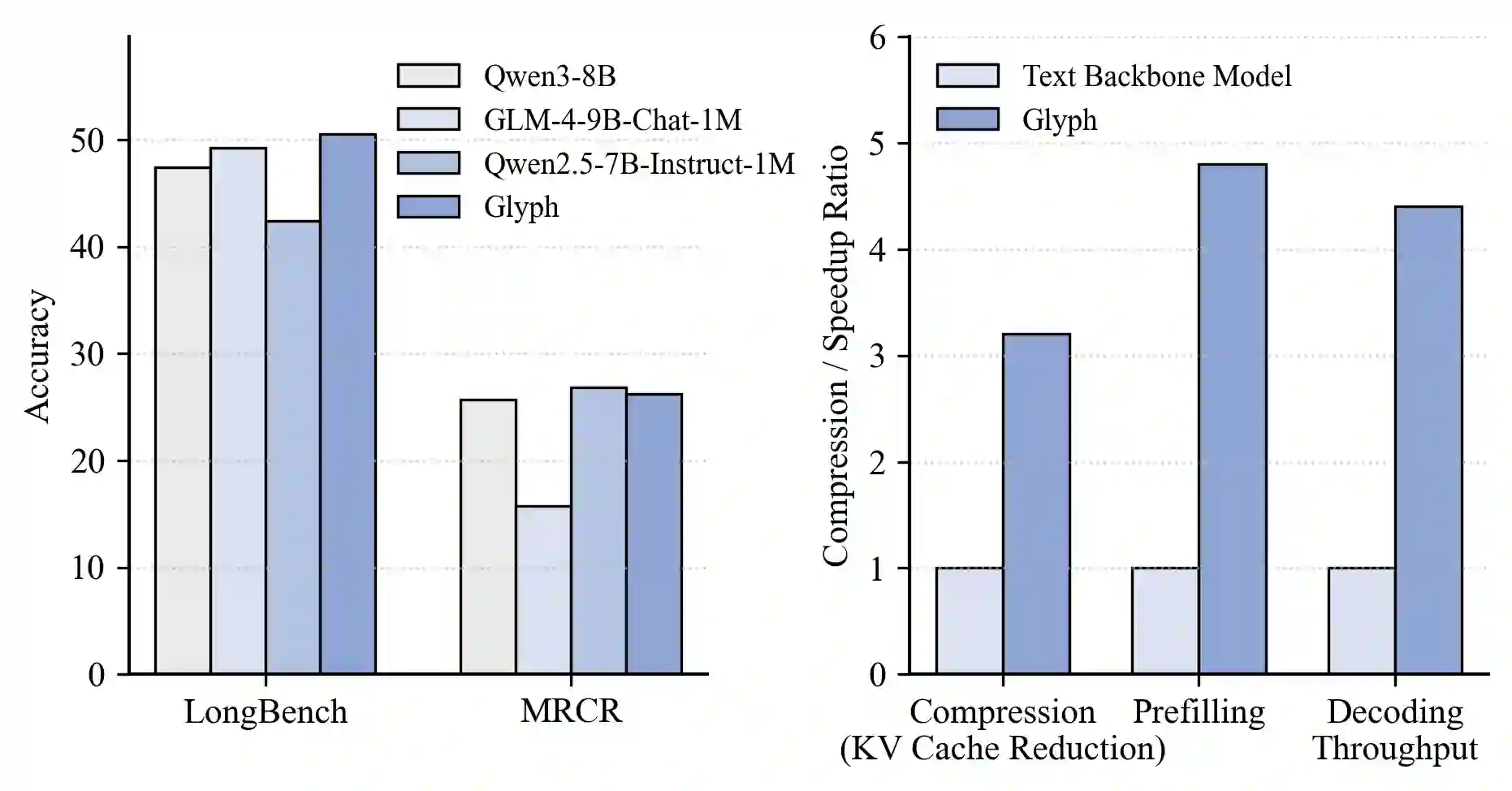
Large language models (LLMs) increasingly rely on long-context modeling for tasks such as document understanding, code analysis, and multi-step reasoning. However, scaling context windows to the million-token level brings prohibitive computational and memory costs, limiting the practicality of long-context LLMs. In this work, we take a different perspective-visual context scaling-to tackle this challenge. Instead of extending token-based sequences, we propose Glyph, a framework that renders long texts into images and processes them with vision-language models (VLMs). This approach substantially compresses textual input while preserving semantic information, and we further design an LLM-driven genetic search to identify optimal visual rendering configurations for balancing accuracy and compression. Through extensive experiments, we demonstrate that our method achieves 3-4x token compression while maintaining accuracy comparable to leading LLMs such as Qwen3-8B on various long-context benchmarks. This compression also leads to around 4x faster prefilling and decoding, and approximately 2x faster SFT training. Furthermore, under extreme compression, a 128K-context VLM could scale to handle 1M-token-level text tasks. In addition, the rendered text data benefits real-world multimodal tasks, such as document understanding. Our code and model are released at https://github.com/thu-coai/Glyph.
翻译:大型语言模型(LLMs)在处理文档理解、代码分析和多步推理等任务时,日益依赖长上下文建模。然而,将上下文窗口扩展至百万标记级别会带来极高的计算和内存成本,限制了长上下文LLMs的实际应用。在本研究中,我们从一个不同的视角——视觉上下文扩展——来应对这一挑战。我们提出了Glyph框架,该框架并非扩展基于标记的序列,而是将长文本渲染为图像,并利用视觉语言模型(VLMs)进行处理。这种方法在保留语义信息的同时,显著压缩了文本输入;我们还进一步设计了一种由LLM驱动的遗传搜索,以识别最佳的视觉渲染配置,从而在准确性和压缩率之间取得平衡。通过大量实验,我们证明该方法在各种长上下文基准测试(如Qwen3-8B)上实现了3-4倍的标记压缩,同时保持了与主流LLMs相当的准确性。这种压缩还带来了约4倍的预填充和解码加速,以及约2倍的监督微调(SFT)训练加速。此外,在极端压缩下,一个128K上下文的VLM能够扩展以处理百万标记级别的文本任务。同时,渲染后的文本数据也有益于现实世界的多模态任务,例如文档理解。我们的代码和模型已在https://github.com/thu-coai/Glyph发布。