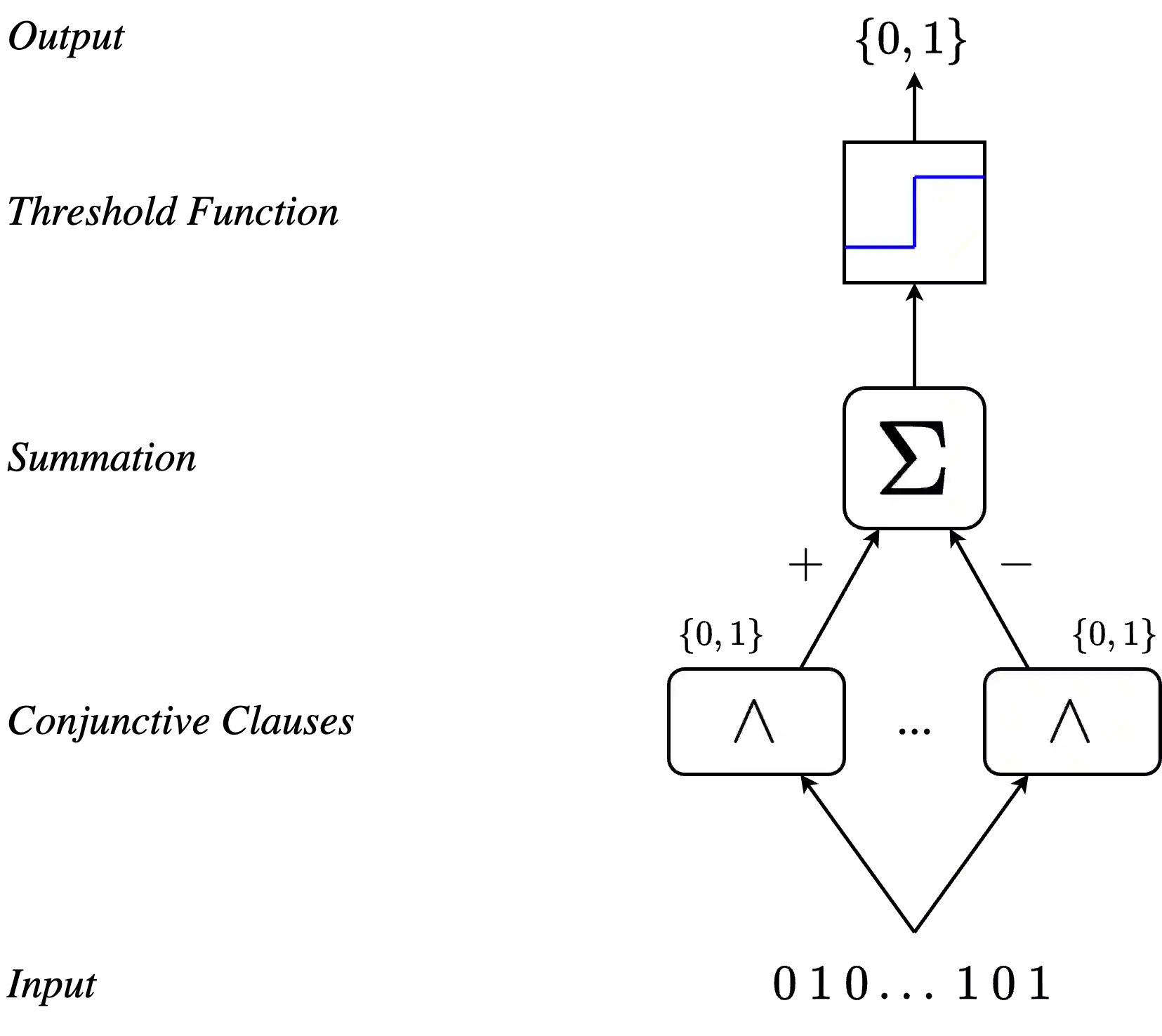
The Tsetlin Machine (TM) is a propositional logic based model that uses conjunctive clauses to learn patterns from data. As with typical neural networks, the performance of a Tsetlin Machine is largely dependent on its parameter count, with a larger number of parameters producing higher accuracy but slower execution. Knowledge distillation in neural networks transfers information from an already-trained teacher model to a smaller student model to increase accuracy in the student without increasing execution time. We propose a novel approach to implementing knowledge distillation in Tsetlin Machines by utilizing the probability distributions of each output sample in the teacher to provide additional context to the student. Additionally, we propose a novel clause-transfer algorithm that weighs the importance of each clause in the teacher and initializes the student with only the most essential data. We find that our algorithm can significantly improve performance in the student model without negatively impacting latency in the tested domains of image recognition and text classification.
翻译:Tsetlin机(TM)是一种基于命题逻辑的模型,它使用合取子句从数据中学习模式。与典型的神经网络类似,Tsetlin机的性能在很大程度上取决于其参数数量,参数越多,精度越高,但执行速度越慢。神经网络中的知识蒸馏将已训练好的教师模型的信息传递给较小的学生模型,以提高学生模型的精度,同时不增加执行时间。我们提出了一种在Tsetlin机中实现知识蒸馏的新方法,该方法利用教师模型中每个输出样本的概率分布为学生模型提供额外上下文。此外,我们提出了一种新颖的子句迁移算法,该算法权衡教师模型中每个子句的重要性,并仅用最本质的数据初始化学生模型。我们发现,在图像识别和文本分类的测试领域中,我们的算法能够显著提升学生模型的性能,且不会对延迟产生负面影响。