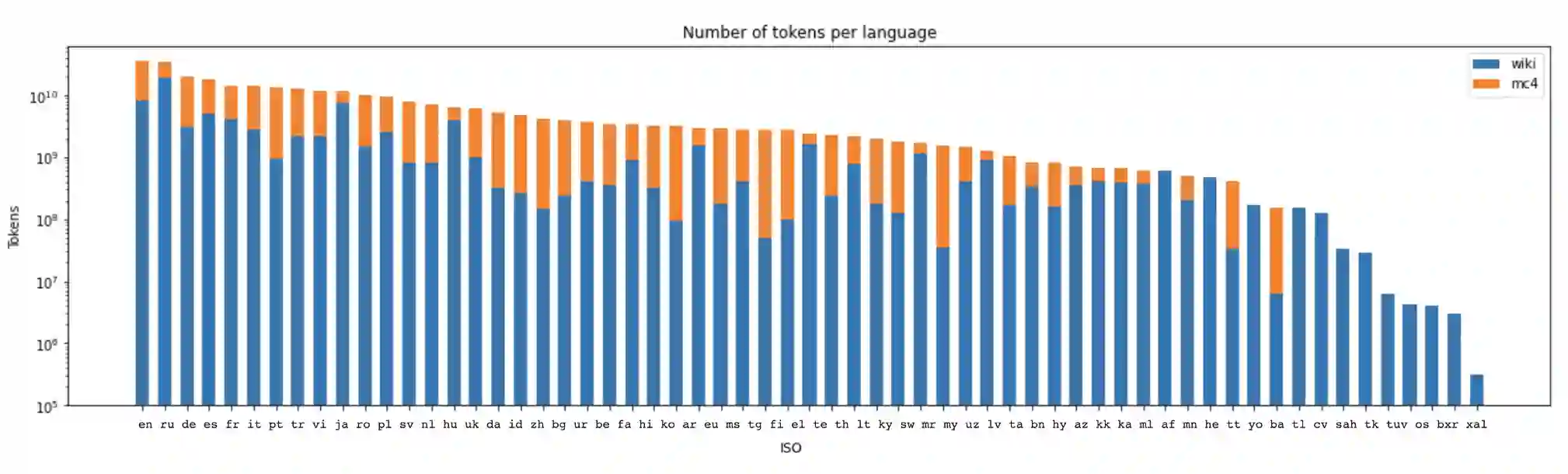
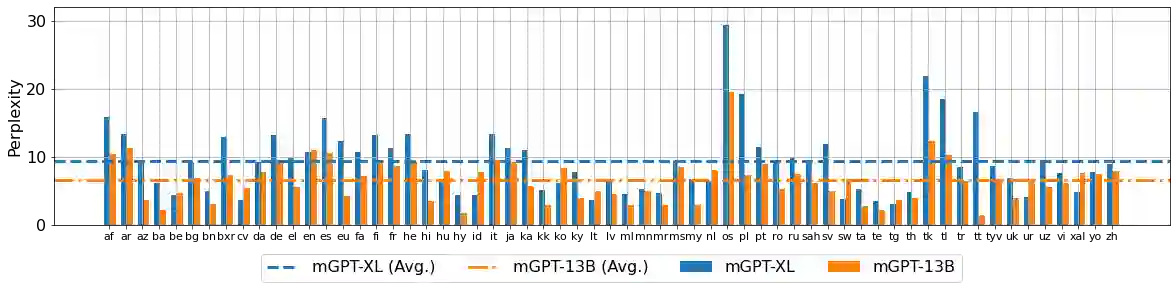
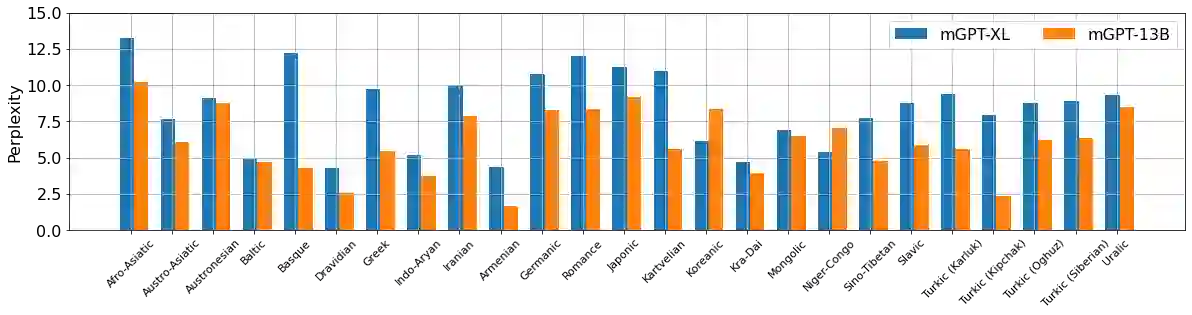
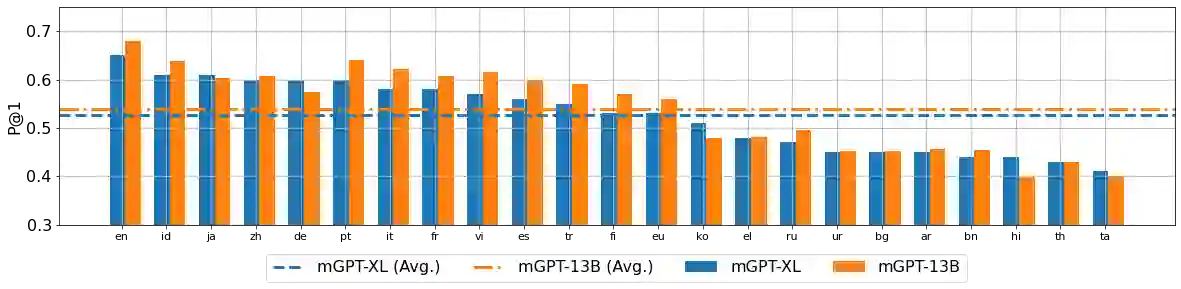
Recent studies report that autoregressive language models can successfully solve many NLP tasks via zero- and few-shot learning paradigms, which opens up new possibilities for using the pre-trained language models. This paper introduces two autoregressive GPT-like models with 1.3 billion and 13 billion parameters trained on 60 languages from 25 language families using Wikipedia and Colossal Clean Crawled Corpus. We reproduce the GPT-3 architecture using GPT-2 sources and the sparse attention mechanism; Deepspeed and Megatron frameworks allow us to parallelize the training and inference steps effectively. The resulting models show performance on par with the recently released XGLM models by Facebook, covering more languages and enhancing NLP possibilities for low resource languages of CIS countries and Russian small nations. We detail the motivation for the choices of the architecture design, thoroughly describe the data preparation pipeline, and train five small versions of the model to choose the most optimal multilingual tokenization strategy. We measure the model perplexity in all covered languages and evaluate it on the wide spectre of multilingual tasks, including classification, generative, sequence labeling and knowledge probing. The models were evaluated with the zero-shot and few-shot methods. Furthermore, we compared the classification tasks with the state-of-the-art multilingual model XGLM. source code and the mGPT XL model are publicly released.
翻译:近期研究表明,自回归语言模型可通过零样本与小样本学习范式成功解决诸多自然语言处理任务,这为预训练语言模型的应用开辟了新可能。本文介绍了两个基于GPT架构的自回归模型,参数量分别为13亿和130亿,采用维基百科与Colossal Clean Crawled语料库在涵盖25个语系的60种语言上完成训练。我们利用GPT-2源码与稀疏注意力机制复现GPT-3架构,借助Deepspeed与Megatron框架实现高效的训练与推理并行化。最终模型性能与Facebook近期发布的XGLM模型相当,覆盖更多语言的同时增强了对独联体国家及俄罗斯少数民族语言等低资源语言的自然语言处理能力。本文详述架构设计选择的动机,系统描述数据预处理流程,并训练五个小型模型以确定最优的多语言分词策略。我们测量模型在所有覆盖语言上的困惑度,并在包含分类、生成、序列标注与知识探测的多语言任务谱系上进行评估,采用零样本与小样本方法完成模型评价。此外,我们将分类任务结果与当前最优的多语言模型XGLM进行了对比。相关源码与mGPT XL模型已公开发布。