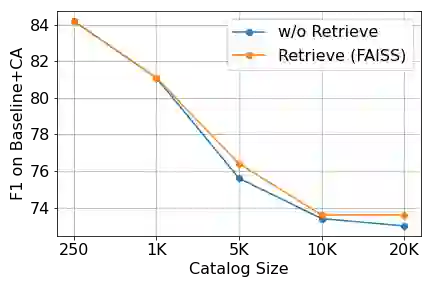
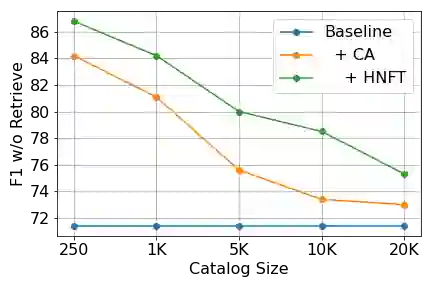
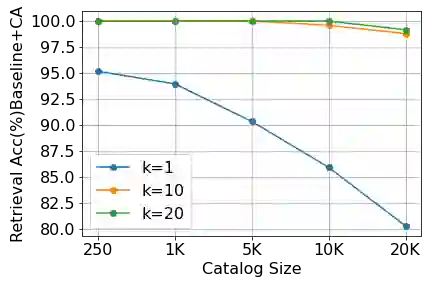
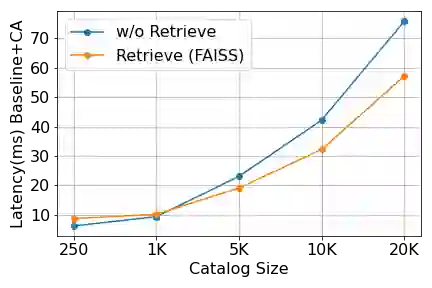
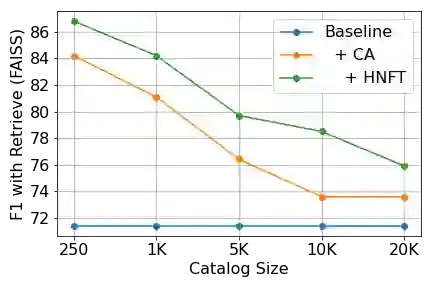
Personalization of automatic speech recognition (ASR) models is a widely studied topic because of its many practical applications. Most recently, attention-based contextual biasing techniques are used to improve the recognition of rare words and domain specific entities. However, due to performance constraints, the biasing is often limited to a few thousand entities, restricting real-world usability. To address this, we first propose a "Retrieve and Copy" mechanism to improve latency while retaining the accuracy even when scaled to a large catalog. We also propose a training strategy to overcome the degradation in recall at such scale due to an increased number of confusing entities. Overall, our approach achieves up to 6% more Word Error Rate reduction (WERR) and 3.6% absolute improvement in F1 when compared to a strong baseline. Our method also allows for large catalog sizes of up to 20K without significantly affecting WER and F1-scores, while achieving at least 20% inference speedup per acoustic frame.
翻译:自动语音识别(ASR)模型的个性化由于其实用性而成为广泛研究的话题。近期,基于注意力的上下文偏置技术被用于改进罕见词和特定领域实体的识别。然而,由于性能限制,偏置通常局限于数千个实体,限制了实际应用的可操作性。为解决此问题,我们首先提出一种"检索与复制"机制,在扩展至大规模目录时保持准确性的同时降低延迟。我们还提出一种训练策略,以克服因混淆实体数量增加而导致的召回率下降问题。总体而言,与强基线相比,我们的方法实现了最高6%的词错误率降低(WERR)和3.6%的绝对F1提升。该方法在显著影响词错误率和F1分值的前提下,支持高达2万的大规模目录规模,且每声学帧推理速度提升至少20%。