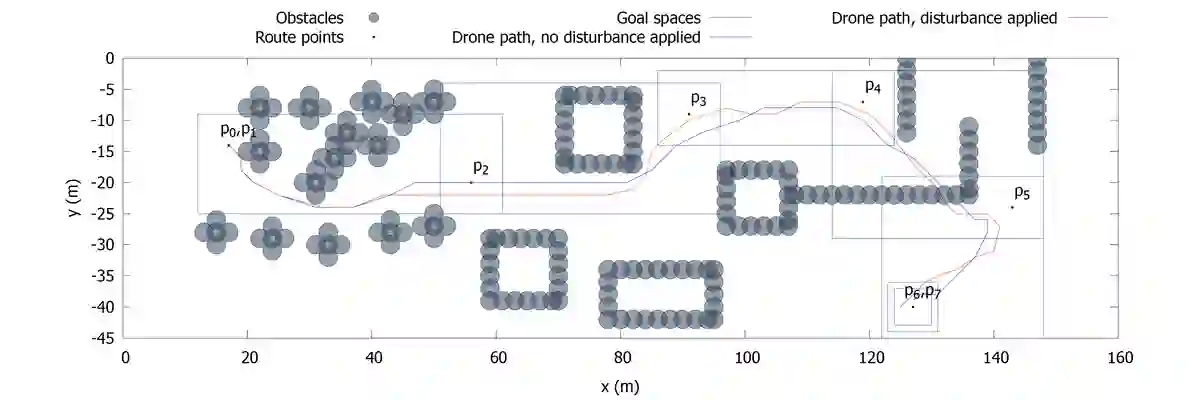
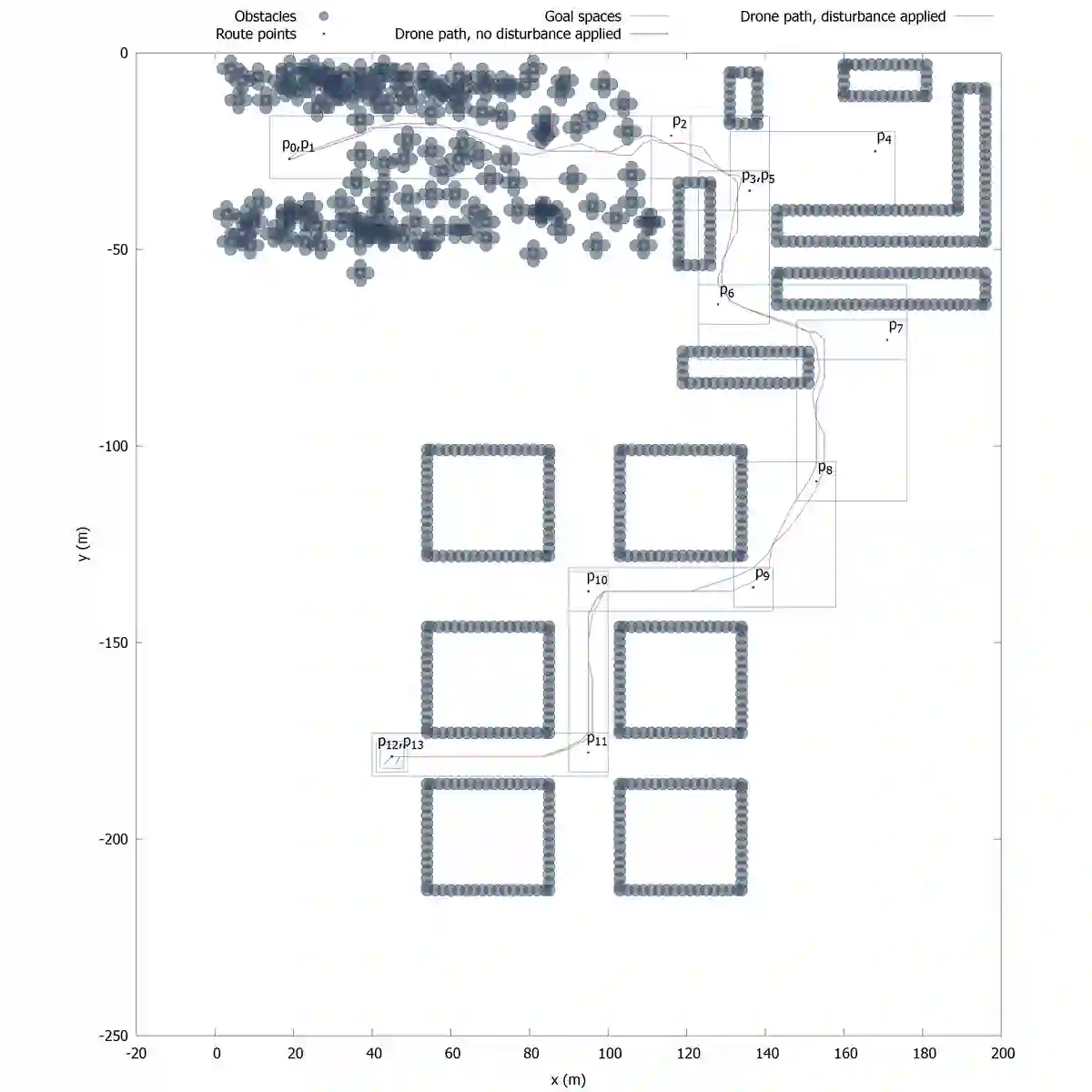
Objective: To obtain explainable guarantees in the online synthesis of optimal controllers for high-integrity cyber-physical systems, we re-investigate the use of exhaustive search as an alternative to reinforcement learning. Approach: We model an application scenario as a hybrid game automaton, enabling the synthesis of robustly correct and near-optimal controllers online without prior training. For modal synthesis, we employ discretised games solved via scope-adaptive and step-pre-shielded discrete dynamic programming. Evaluation: In a simulation-based experiment, we apply our approach to an autonomous aerial vehicle scenario. Contribution: We propose a parametric system model and a parametric online synthesis.
翻译:目标:为高完整性信息物理系统在线综合最优控制器时获得可解释的保证,我们重新研究将穷举搜索作为强化学习的替代方案。方法:我们将应用场景建模为混合博弈自动机,从而能够在无需预先训练的情况下在线综合具有鲁棒正确性且接近最优的控制器。对于模态综合,我们采用通过范围自适应和步进预屏蔽离散动态规划求解的离散化博弈。评估:在基于仿真的实验中,我们将所提方法应用于自主飞行器场景。贡献:我们提出了参数化系统模型与参数化在线综合方法。