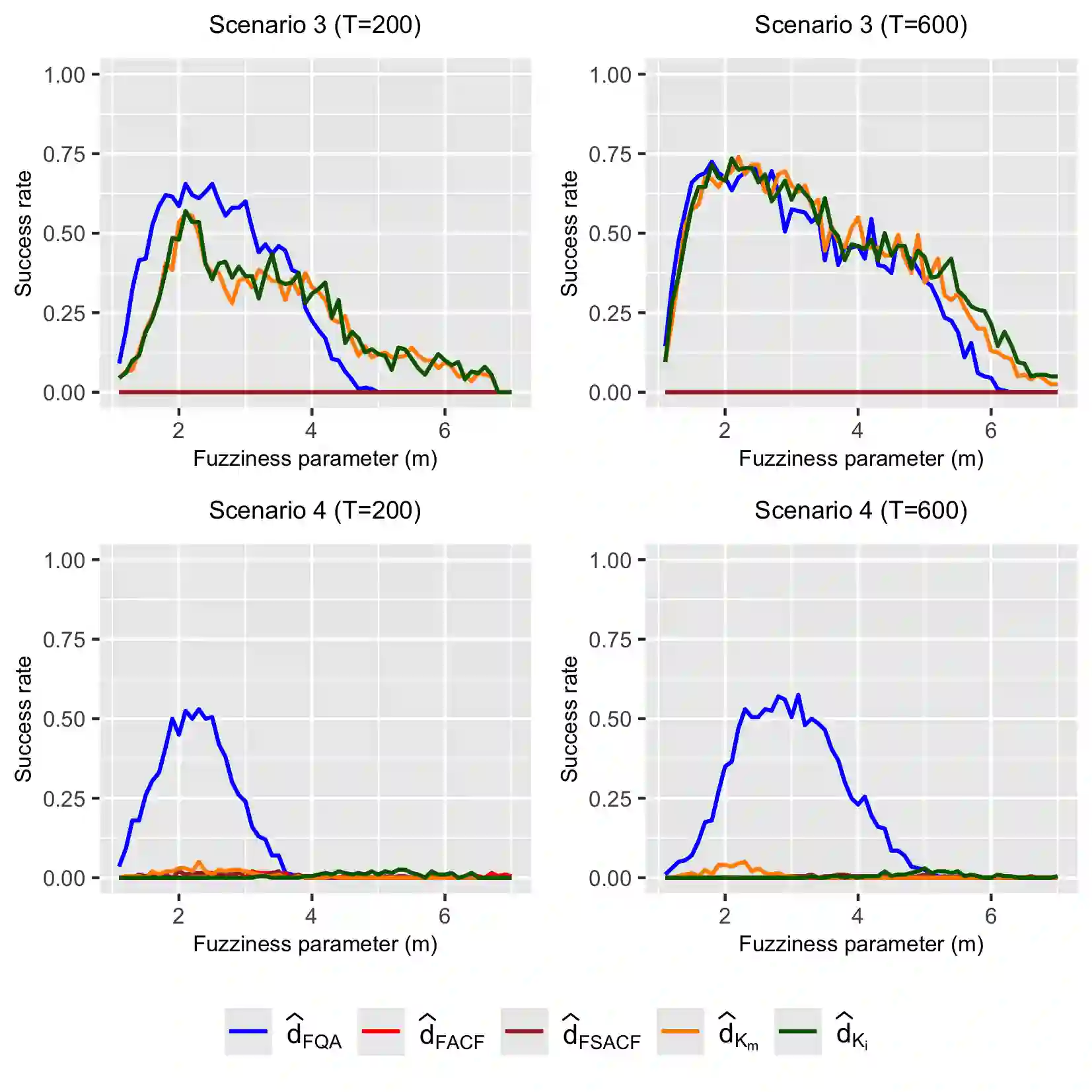
Time series clustering is essential in scientific applications, yet methods for functional time series, collections of infinite-dimensional curves treated as random elements in a Hilbert space, remain underdeveloped. This work presents clustering approaches for functional time series that combine the fuzzy $C$-medoids and fuzzy $C$-means procedures with a novel dissimilarity measure tailored for functional data. This dissimilarity is based on an extension of the quantile autocorrelation to the functional context. Our methods effectively groups time series with similar dependence structures, achieving high accuracy and computational efficiency in simulations. The practical utility of the approach is demonstrated through case studies on high-frequency financial stock data and multi-country age-specific mortality improvements.
翻译:时间序列聚类在科学应用中至关重要,然而针对函数时间序列(即被视为希尔伯特空间中随机元素的无限维曲线集合)的方法仍不完善。本研究提出了结合模糊C中心点与模糊C均值算法的函数时间序列聚类方法,并引入一种专为函数数据设计的新型相异性度量。该度量基于分位数自相关在函数语境下的扩展。我们的方法能有效聚类具有相似依赖结构的时间序列,在仿真实验中实现了高精度与计算效率。通过对高频金融股票数据及多国年龄别死亡率改进率的案例研究,验证了该方法的实际应用价值。