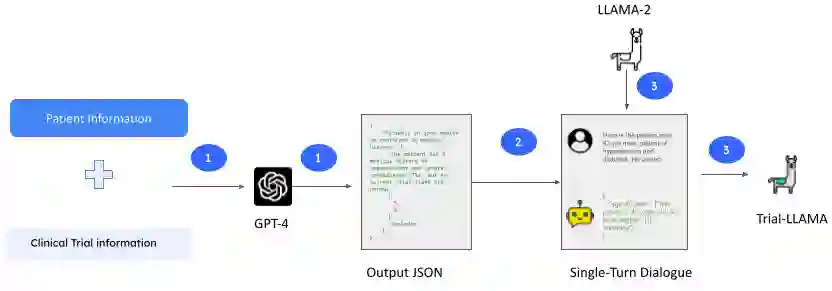
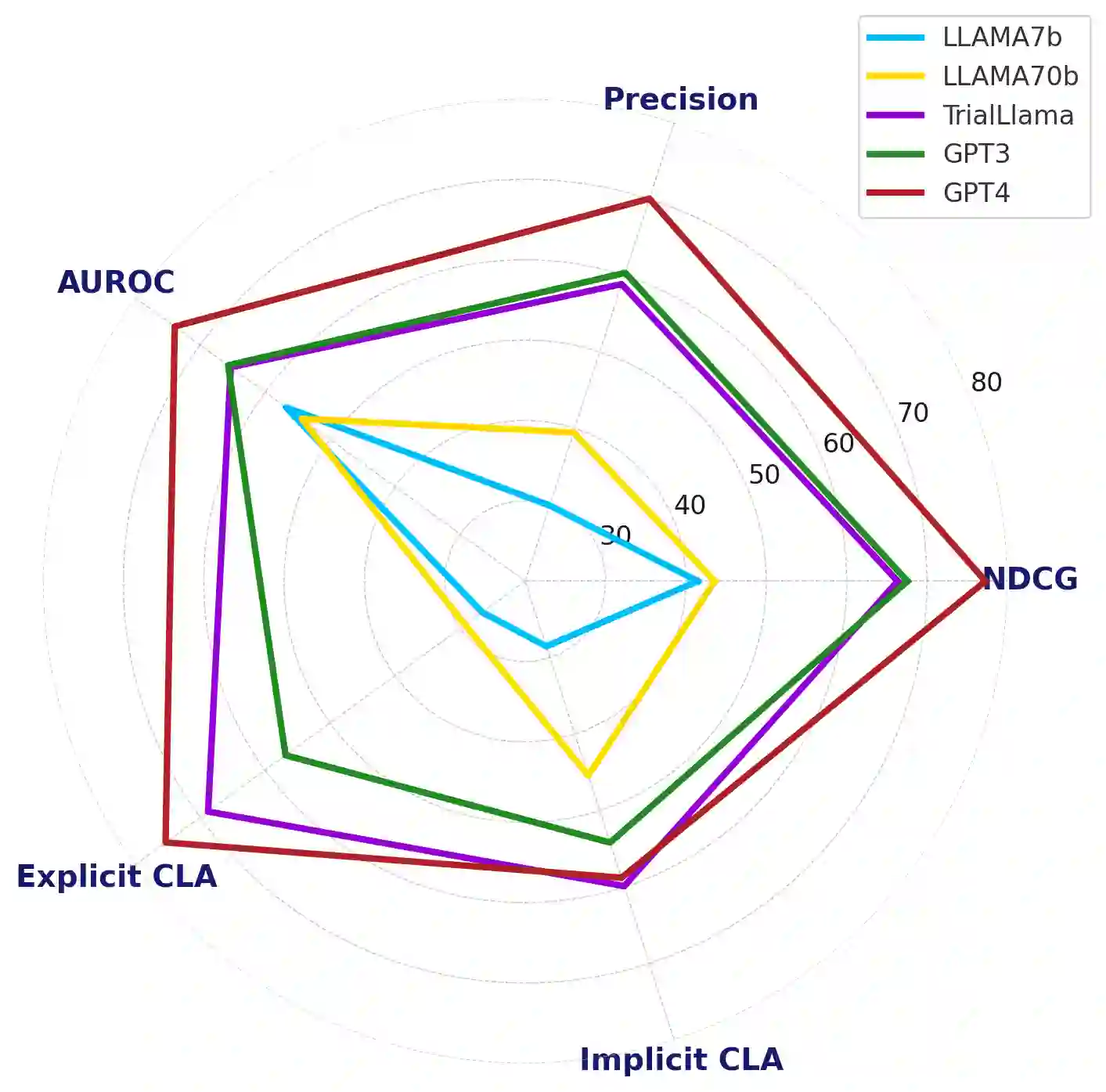
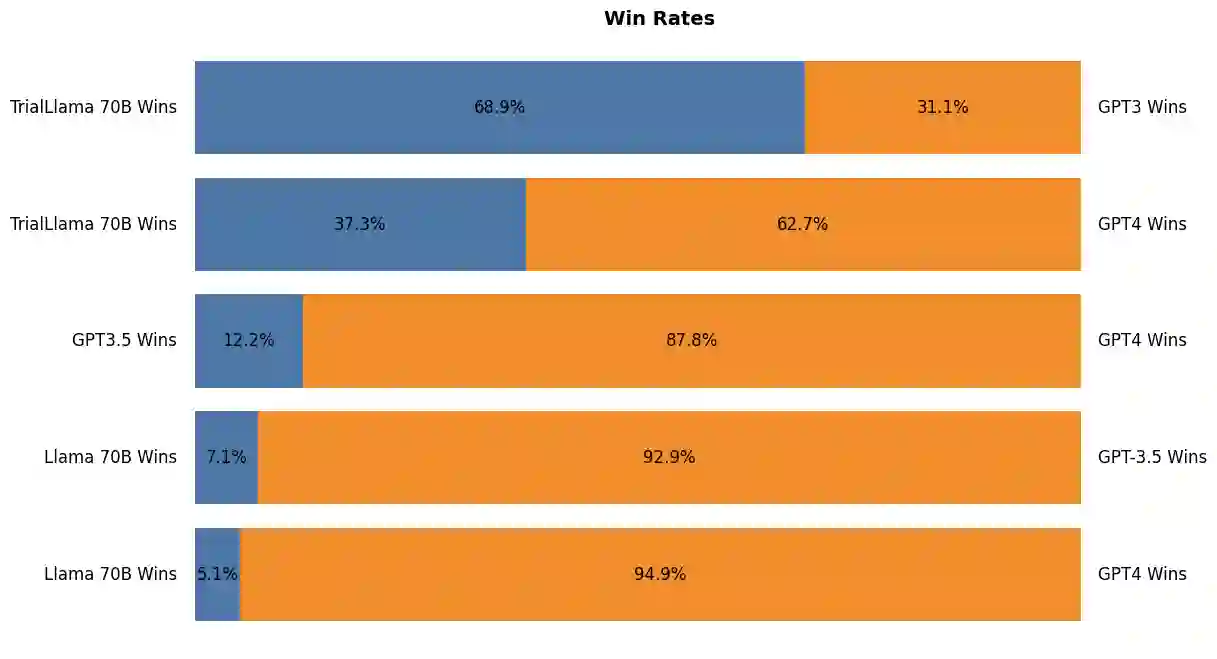
The recent success of large language models (LLMs) has paved the way for their adoption in the high-stakes domain of healthcare. Specifically, the application of LLMs in patient-trial matching, which involves assessing patient eligibility against clinical trial's nuanced inclusion and exclusion criteria, has shown promise. Recent research has shown that GPT-3.5, a widely recognized LLM developed by OpenAI, can outperform existing methods with minimal 'variable engineering' by simply comparing clinical trial information against patient summaries. However, there are significant challenges associated with using closed-source proprietary LLMs like GPT-3.5 in practical healthcare applications, such as cost, privacy and reproducibility concerns. To address these issues, this study presents the first systematic examination of the efficacy of both proprietary (GPT-3.5, and GPT-4) and open-source LLMs (LLAMA 7B,13B, and 70B) for the task of patient-trial matching. Employing a multifaceted evaluation framework, we conducted extensive automated and human-centric assessments coupled with a detailed error analysis for each model. To enhance the adaptability of open-source LLMs, we have created a specialized synthetic dataset utilizing GPT-4, enabling effective fine-tuning under constrained data conditions. Our findings reveal that open-source LLMs, when fine-tuned on this limited and synthetic dataset, demonstrate performance parity with their proprietary counterparts. This presents a massive opportunity for their deployment in real-world healthcare applications. To foster further research and applications in this field, we release both the annotated evaluation dataset along with the fine-tuned LLM -- Trial-LLAMA -- for public use.
翻译:大语言模型(LLMs)的最新成功为它们在高风险的医疗保健领域的应用铺平了道路。具体而言,LLMs在患者-临床试验匹配中的应用——即根据临床试验微妙的纳入和排除标准评估患者资格——已展现出前景。近期研究表明,由OpenAI开发的广泛认可的LLM——GPT-3.5,只需通过简单比较临床试验信息与患者摘要,就能以极少的“变量工程”超越现有方法。然而,在实用医疗保健应用中使用像GPT-3.5这样的闭源专有LLM面临着重大挑战,例如成本、隐私和可重复性问题。为解决这些问题,本研究首次系统性地检验了专有模型(GPT-3.5和GPT-4)和开源LLMs(LLAMA 7B、13B和70B)在患者-临床试验匹配任务中的有效性。采用多维度评估框架,我们进行了广泛的自动化和以人为中心的评估,并对每个模型进行了详细的错误分析。为了增强开源LLMs的适应性,我们利用GPT-4创建了一个专门的合成数据集,从而能在受限数据条件下进行有效的微调。我们的研究结果表明,在该有限合成数据集上微调后的开源LLMs,其性能与专有模型相当。这为它们在真实医疗保健应用中的部署提供了巨大机遇。为促进该领域的进一步研究和应用,我们公开发布了带注释的评估数据集以及微调后的LLM——Trial-LLAMA。