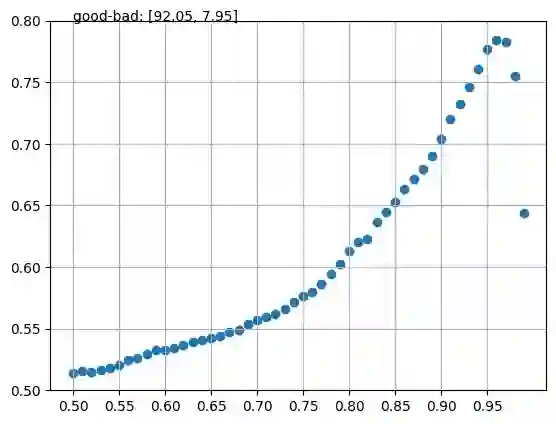
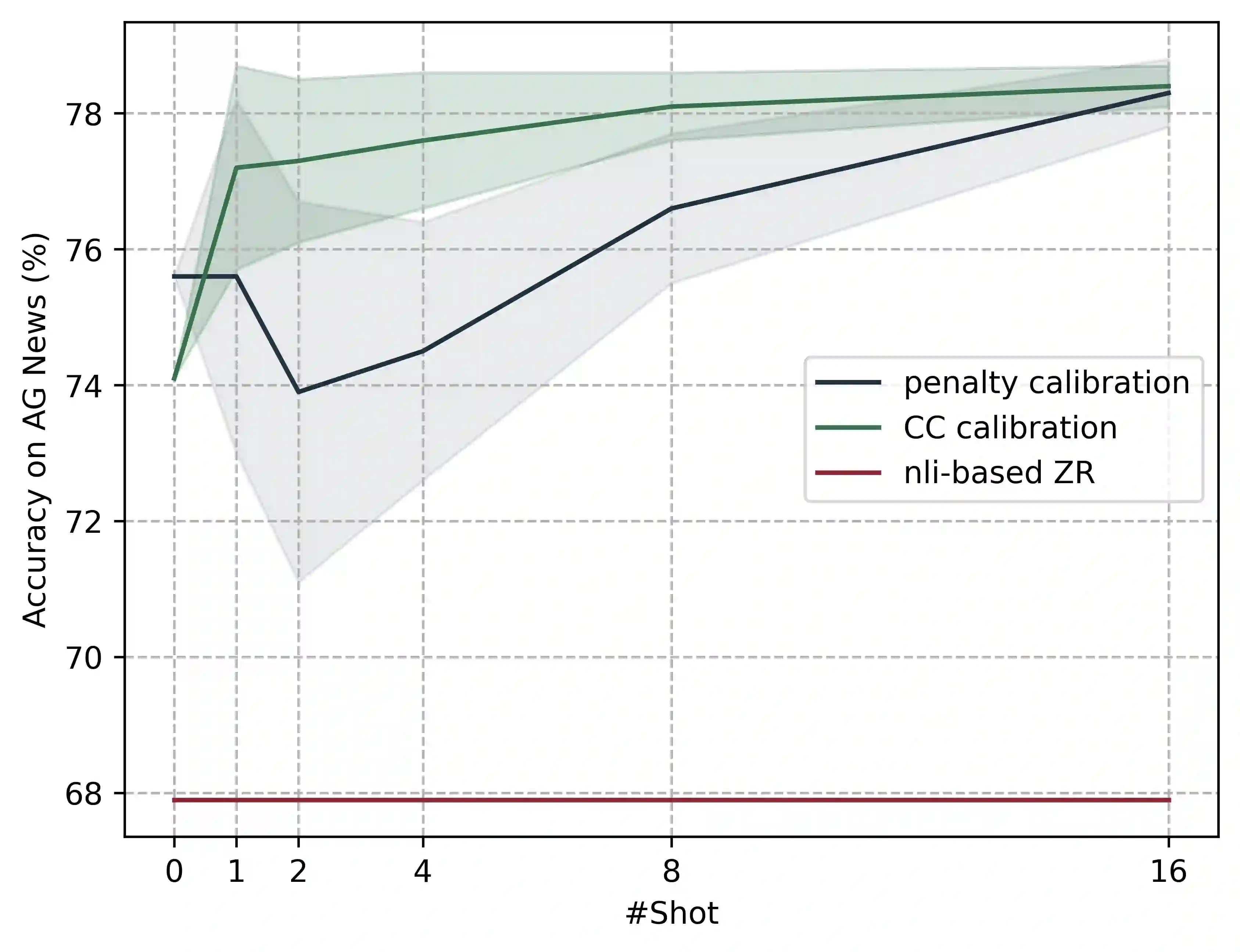
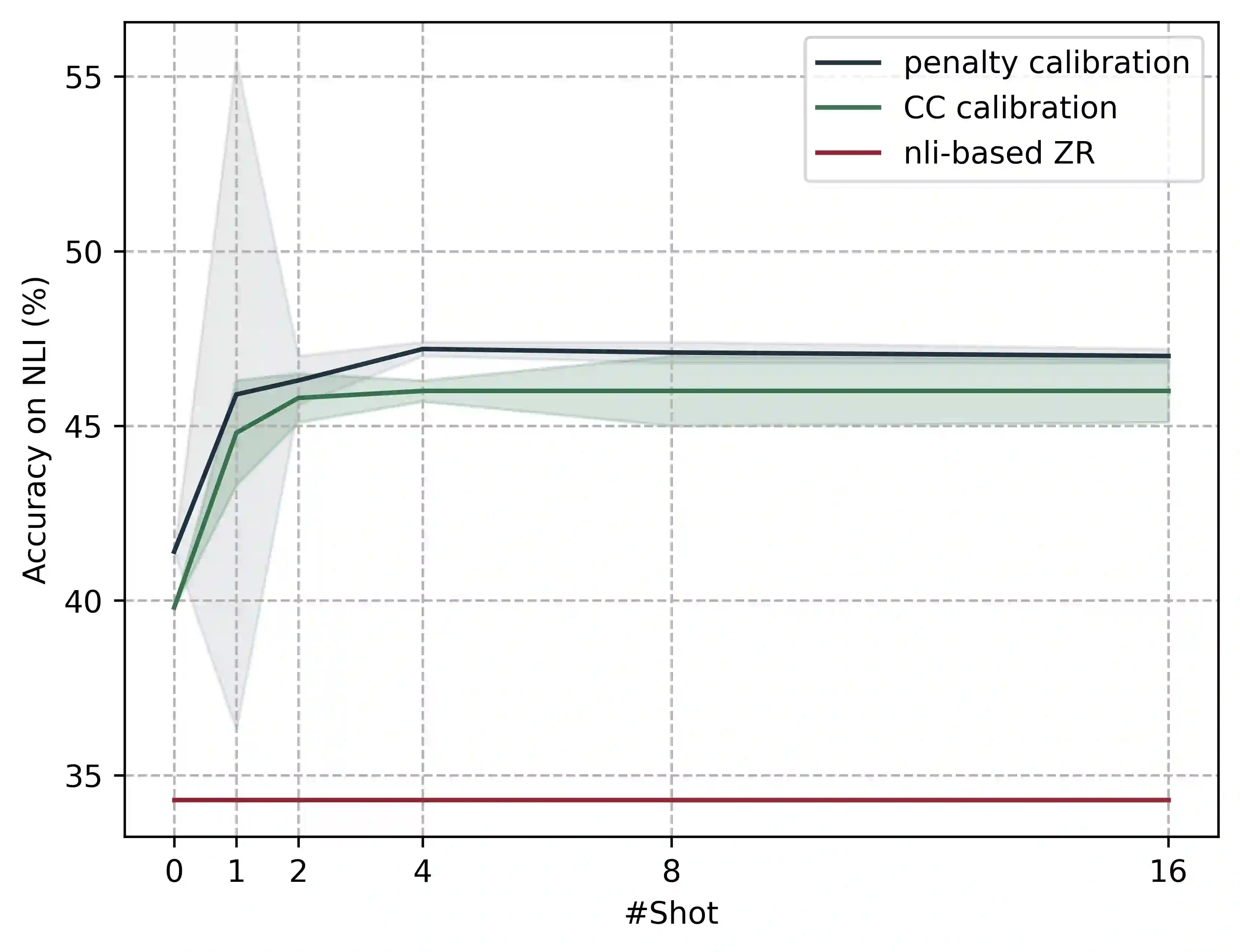
Pretrained multilingual encoder models can directly perform zero-shot multilingual tasks or linguistic probing by reformulating the input examples into cloze-style prompts. This is accomplished by predicting the probabilities of the label words at the masked token position, without requiring any updates to the model parameters. However, the performance of this method is limited by the model's bias toward predicting label words which frequently occurred during the pretraining. These words typically receive high probabilities. To address this issue, we combine the models with calibration techniques which modify the probabilities of label words predicted by the models. We first validate the effectiveness of a proposed simple calibration method together with other existing techniques on monolingual encoders in both zero- and few-shot scenarios. We subsequently employ these calibration techniques on multilingual encoders, resulting in substantial performance improvements across a wide range of tasks.
翻译:预训练的多语言编码器模型可通过将输入示例重构为完形填空式提示,直接执行零样本多语言任务或语言探针分析。该方法通过预测掩码标记位置处标签词的概率实现,无需更新模型参数。然而,该方法的表现受限于模型对预训练阶段高频出现的标签词的预测偏差——这些词汇通常获得较高的概率值。为解决该问题,我们结合校准技术调整模型预测的标签词概率。首先,在零样本和少样本场景下,我们验证了所提出的简易校准方法及其他现有技术在单语言编码器上的有效性。随后,我们将这些校准技术应用于多语言编码器,在广泛的任务中取得了显著的性能提升。