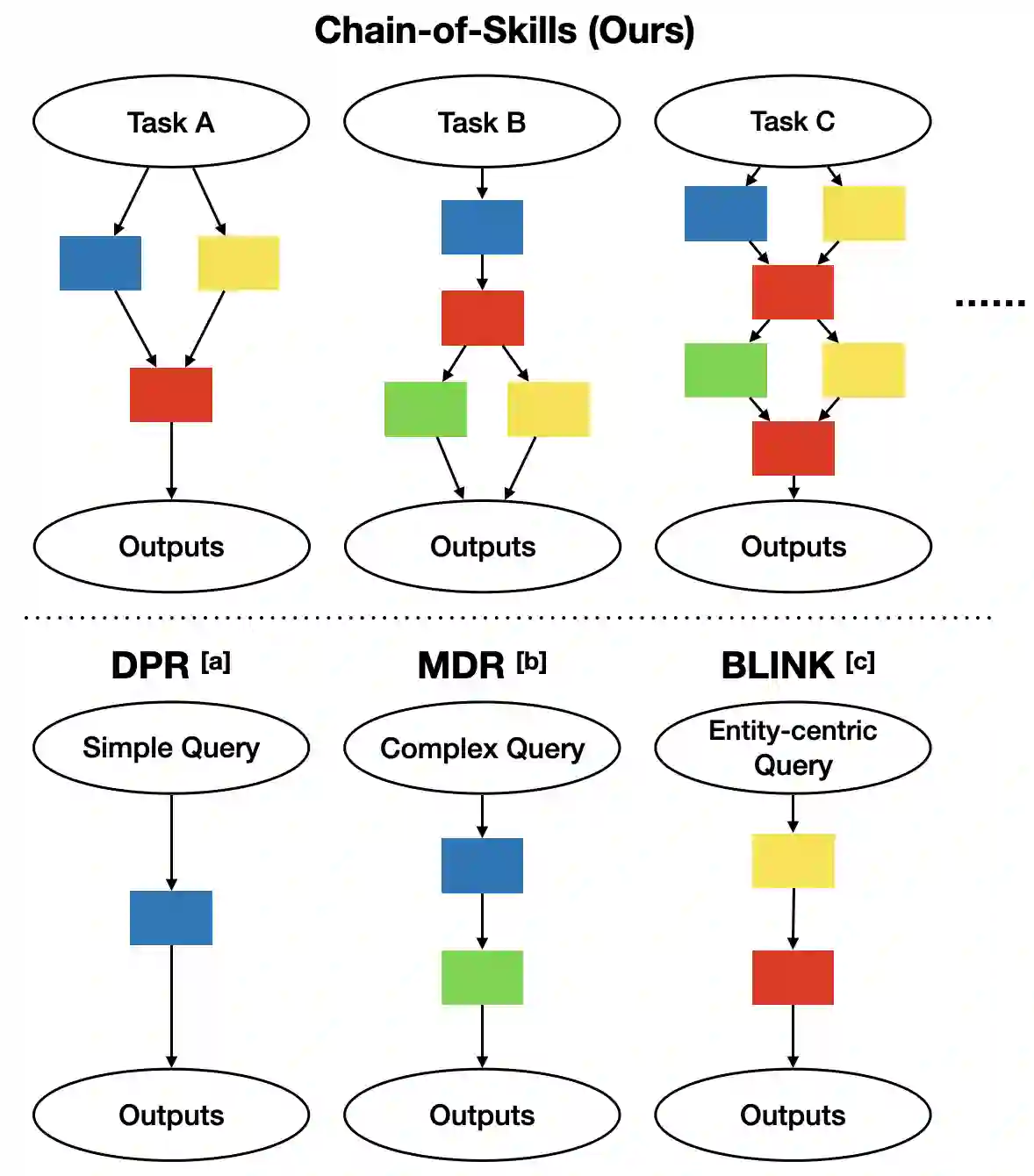
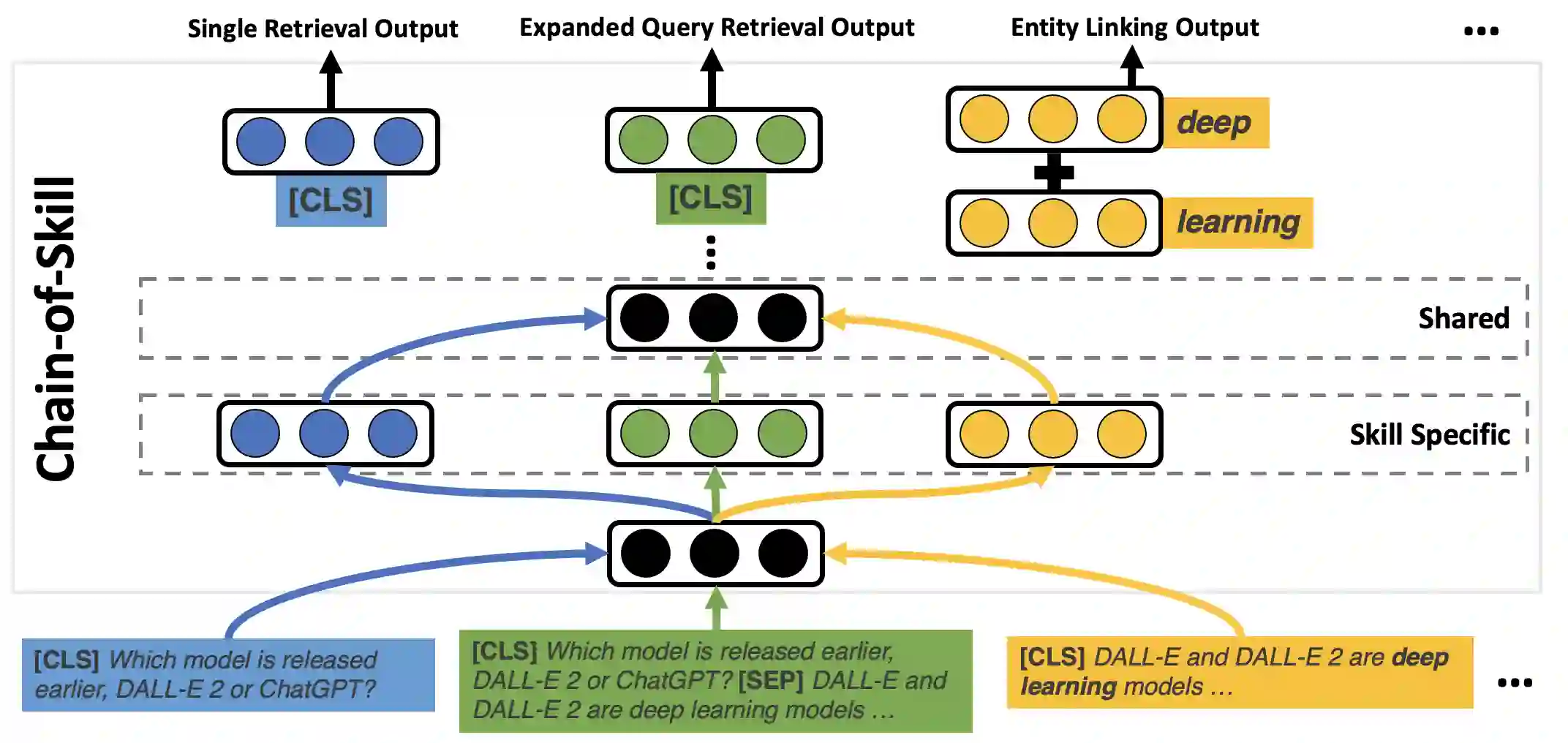
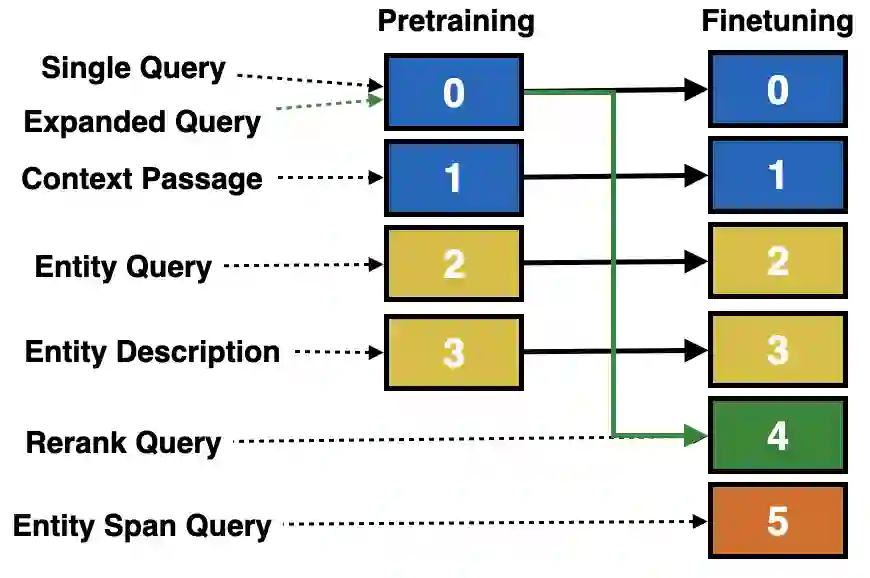
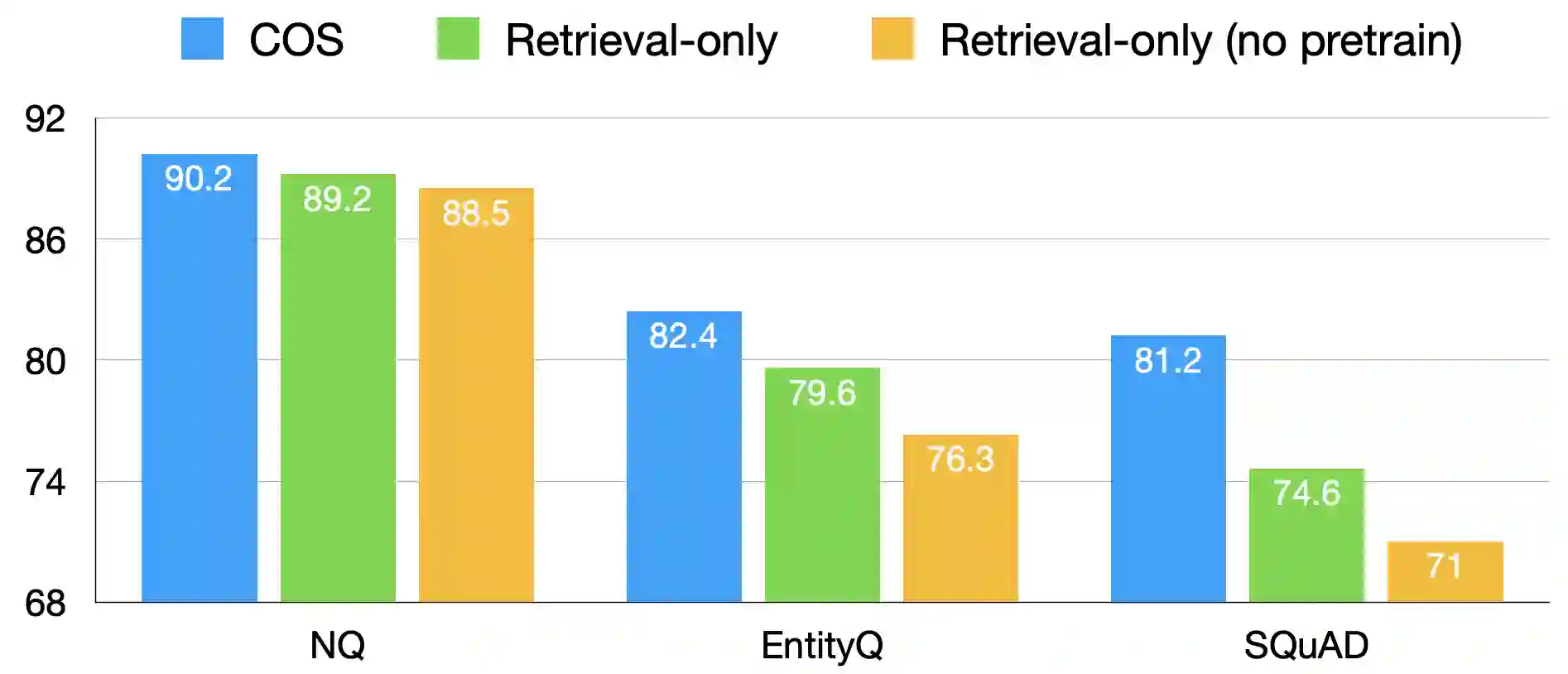
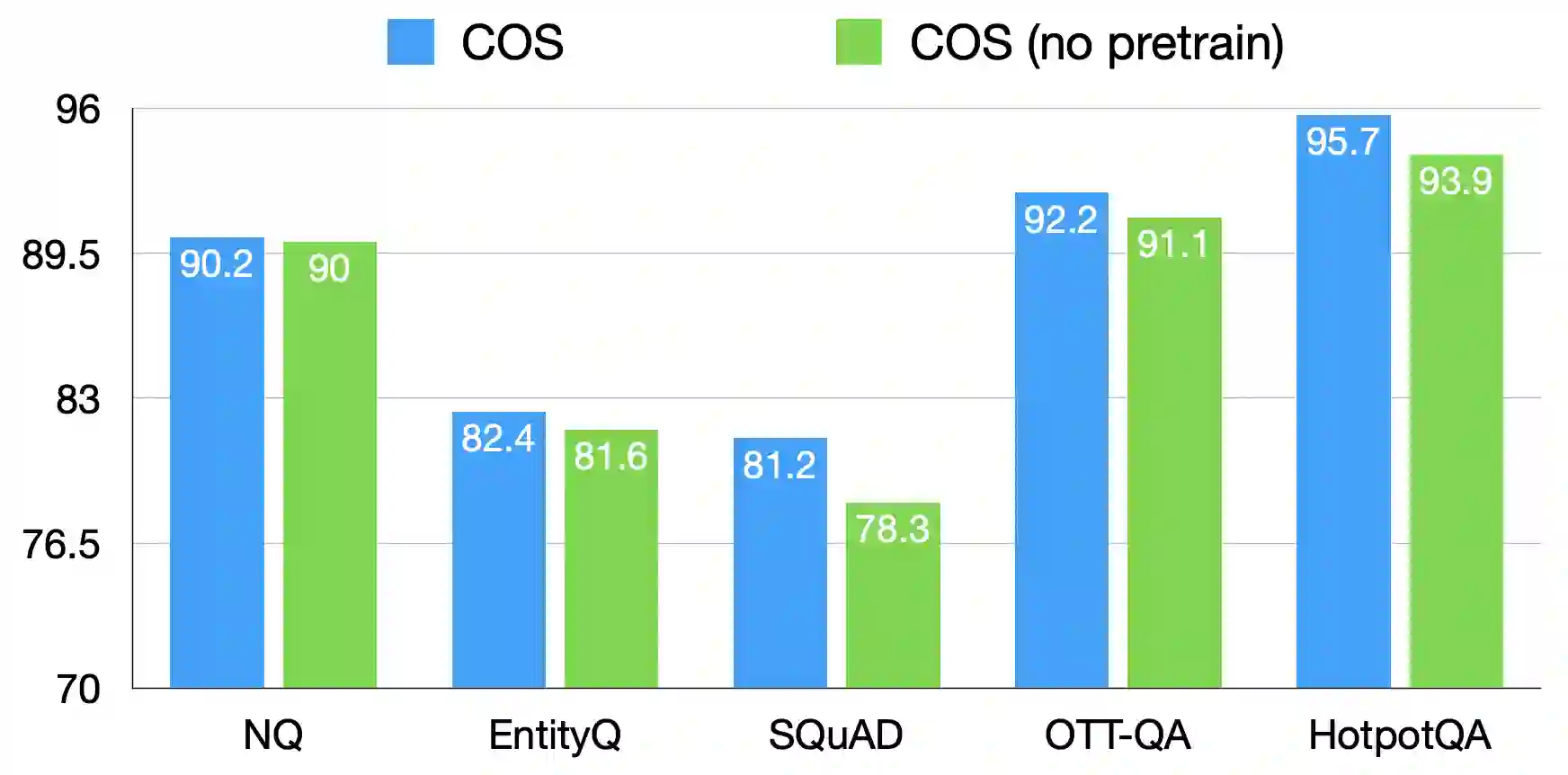
The retrieval model is an indispensable component for real-world knowledge-intensive tasks, e.g., open-domain question answering (ODQA). As separate retrieval skills are annotated for different datasets, recent work focuses on customized methods, limiting the model transferability and scalability. In this work, we propose a modular retriever where individual modules correspond to key skills that can be reused across datasets. Our approach supports flexible skill configurations based on the target domain to boost performance. To mitigate task interference, we design a novel modularization parameterization inspired by sparse Transformer. We demonstrate that our model can benefit from self-supervised pretraining on Wikipedia and fine-tuning using multiple ODQA datasets, both in a multi-task fashion. Our approach outperforms recent self-supervised retrievers in zero-shot evaluations and achieves state-of-the-art fine-tuned retrieval performance on NQ, HotpotQA and OTT-QA.
翻译:检索模型是真实世界知识密集型任务(如开放域问答)中不可或缺的组件。由于不同数据集标注了不同的检索技能,近期研究侧重于定制化方法,限制了模型的可迁移性与可扩展性。本文提出一种模块化检索器,其中各独立模块对应可在不同数据集间复用的关键技能。该方法支持基于目标领域灵活配置技能以提升性能。为缓解任务间干扰,我们受稀疏Transformer启发设计了一种新颖的模块化参数化方案。实验表明,该模型可通过维基百科自监督预训练及多任务微调多个ODQA数据集获益。在零样本评估中,我们的方法优于近期自监督检索器,并在NQ、HotpotQA及OTT-QA数据集上实现了最先进的微调检索性能。