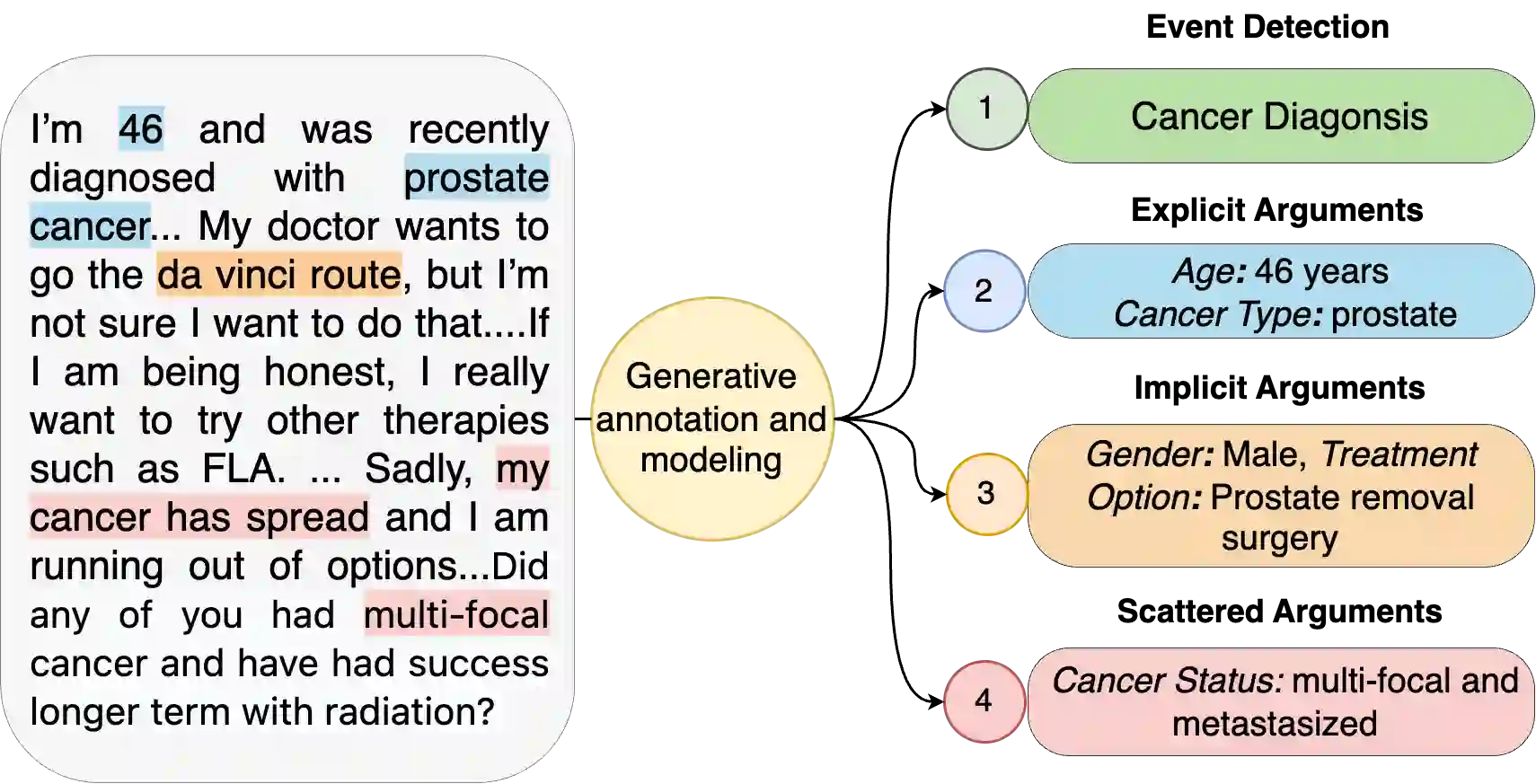
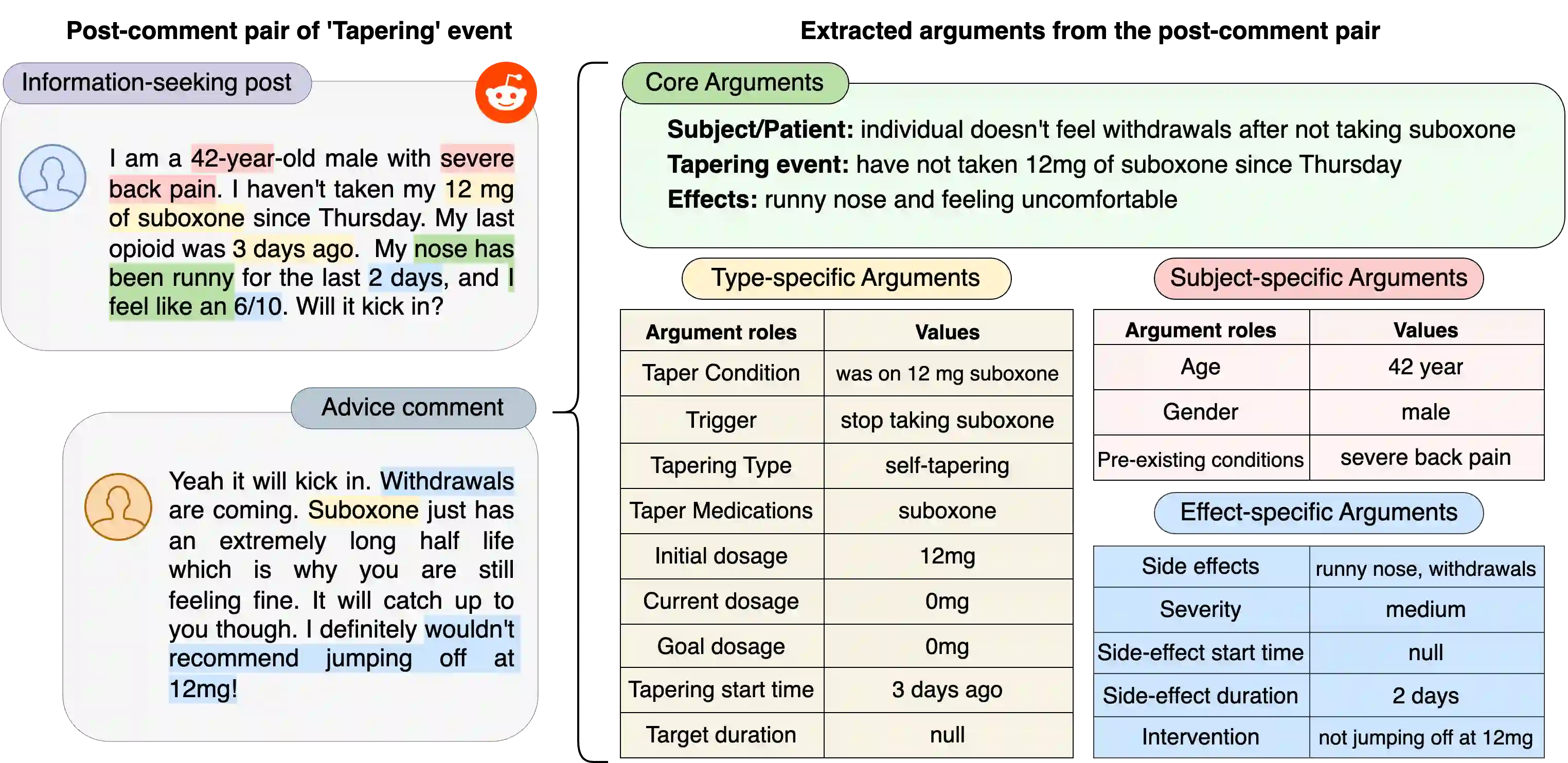
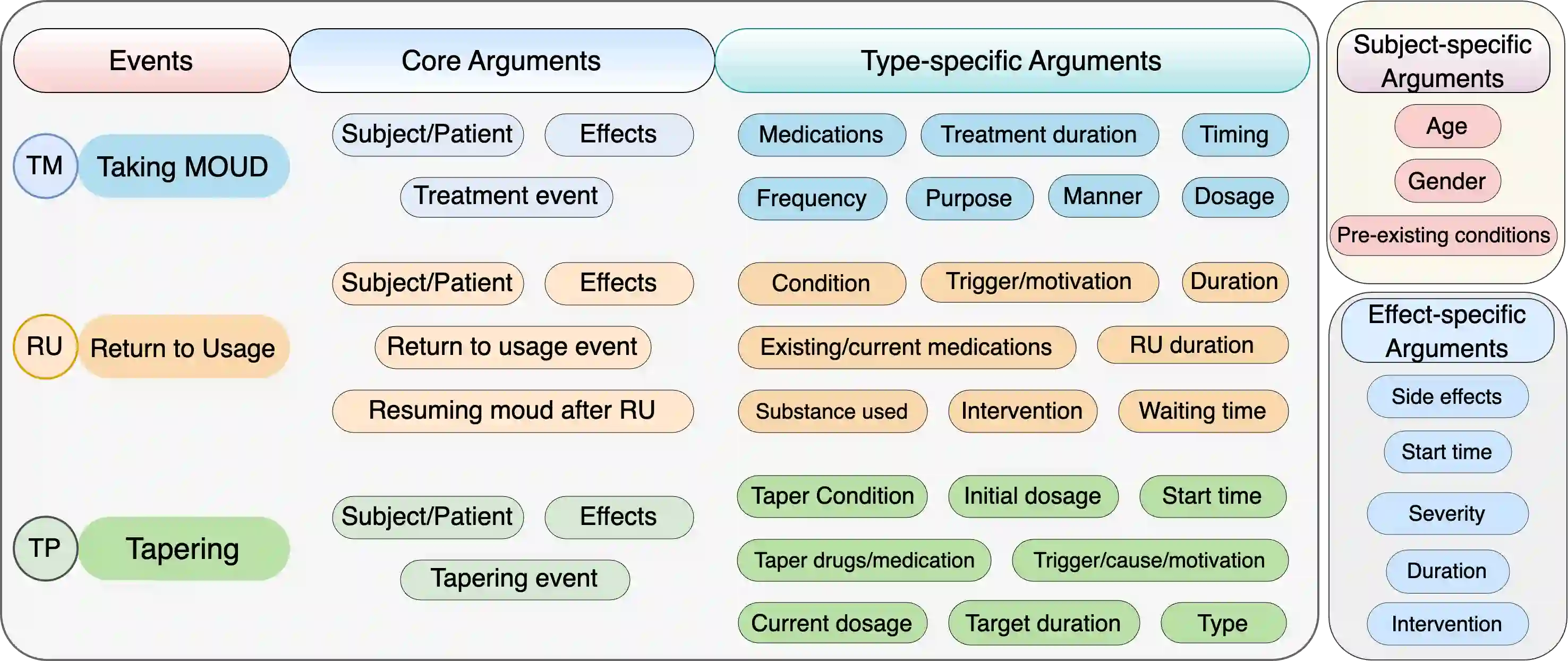
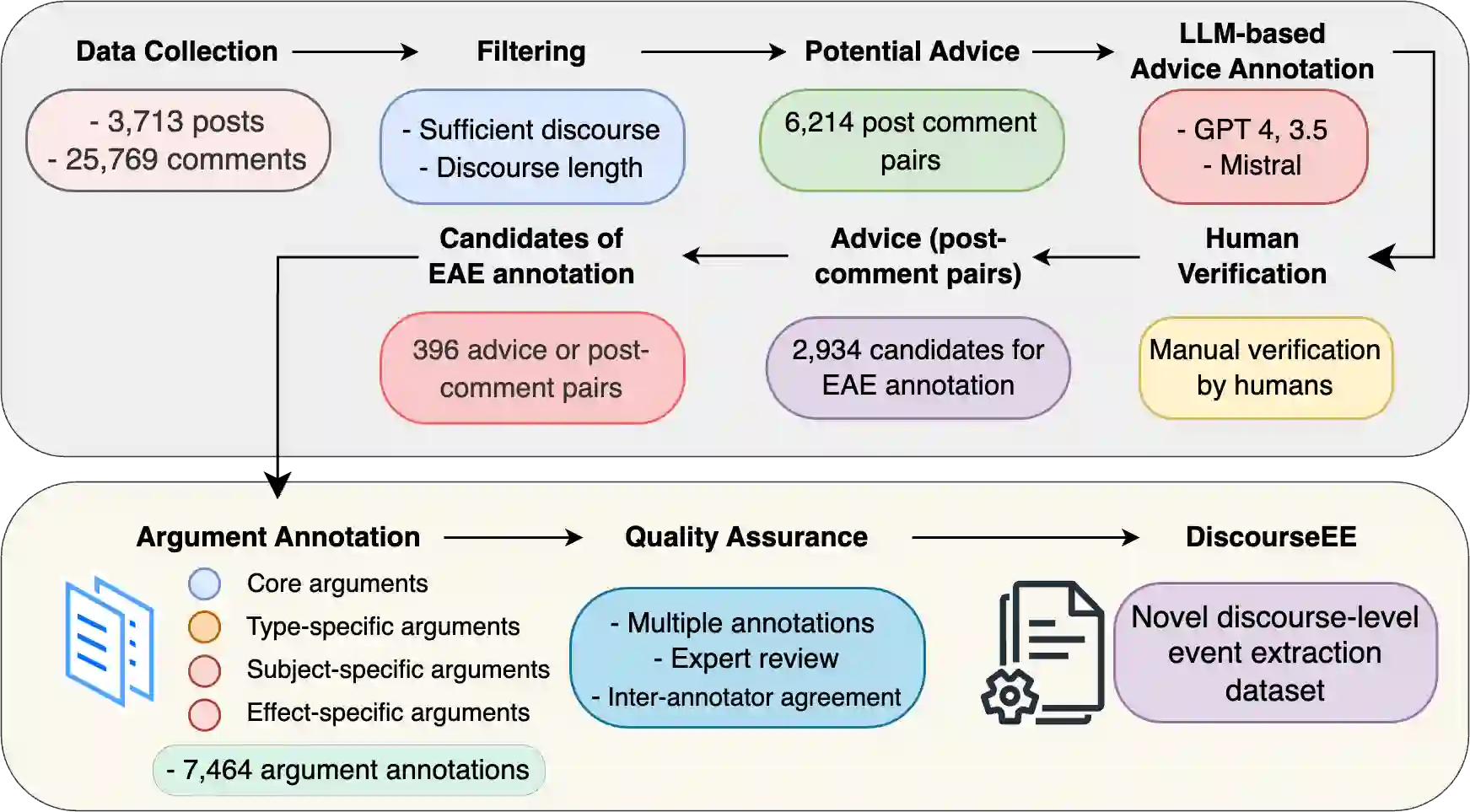
Prior works formulate the extraction of event-specific arguments as a span extraction problem, where event arguments are explicit -- i.e. assumed to be contiguous spans of text in a document. In this study, we revisit this definition of Event Extraction (EE) by introducing two key argument types that cannot be modeled by existing EE frameworks. First, implicit arguments are event arguments which are not explicitly mentioned in the text, but can be inferred through context. Second, scattered arguments are event arguments that are composed of information scattered throughout the text. These two argument types are crucial to elicit the full breadth of information required for proper event modeling. To support the extraction of explicit, implicit, and scattered arguments, we develop a novel dataset, DiscourseEE, which includes 7,464 argument annotations from online health discourse. Notably, 51.2% of the arguments are implicit, and 17.4% are scattered, making DiscourseEE a unique corpus for complex event extraction. Additionally, we formulate argument extraction as a text generation problem to facilitate the extraction of complex argument types. We provide a comprehensive evaluation of state-of-the-art models and highlight critical open challenges in generative event extraction. Our data and codebase are available at https://omar-sharif03.github.io/DiscourseEE.
翻译:先前的研究将事件特定论元的抽取定义为跨度抽取问题,其中事件论元被假定为显式的——即文档中连续的文本片段。在本研究中,我们通过引入两种无法被现有事件抽取框架建模的关键论元类型,重新审视事件抽取的这一定义。首先,隐式论元指未在文本中明确提及但可通过上下文推断的事件论元。其次,分散式论元指由分散在文本各处的信息组成的事件论元。这两种论元类型对于获取完整事件建模所需的信息广度至关重要。为支持显式、隐式和分散式论元的抽取,我们构建了一个新颖的数据集DiscourseEE,其中包含来自在线健康讨论的7,464个论元标注。值得注意的是,51.2%的论元为隐式,17.4%为分散式,这使得DiscourseEE成为复杂事件抽取的独特语料库。此外,我们将论元抽取构建为文本生成问题,以促进复杂论元类型的抽取。我们对前沿模型进行了全面评估,并指出了生成式事件抽取中亟待解决的关键挑战。我们的数据与代码库已公开于https://omar-sharif03.github.io/DiscourseEE。