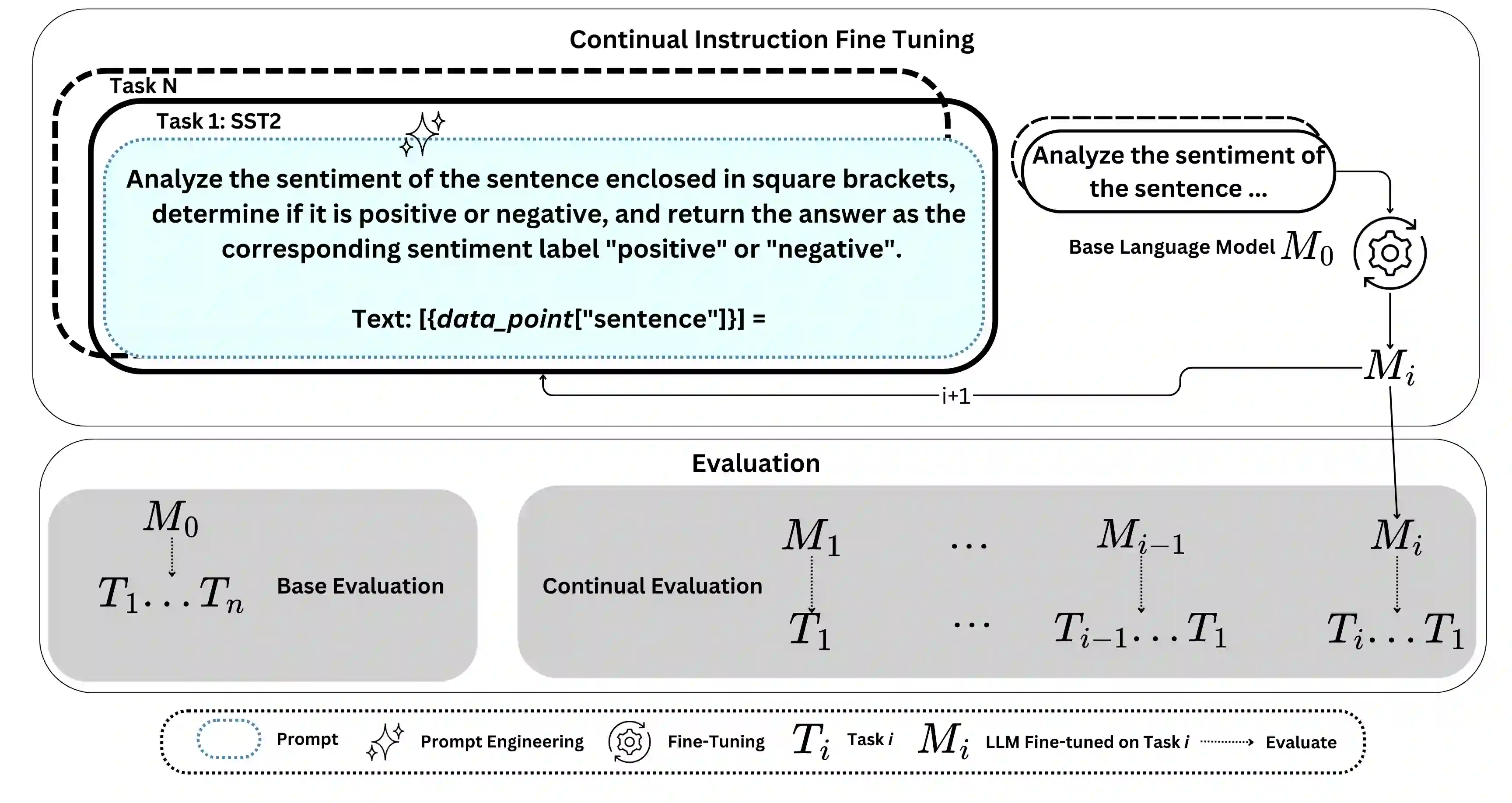
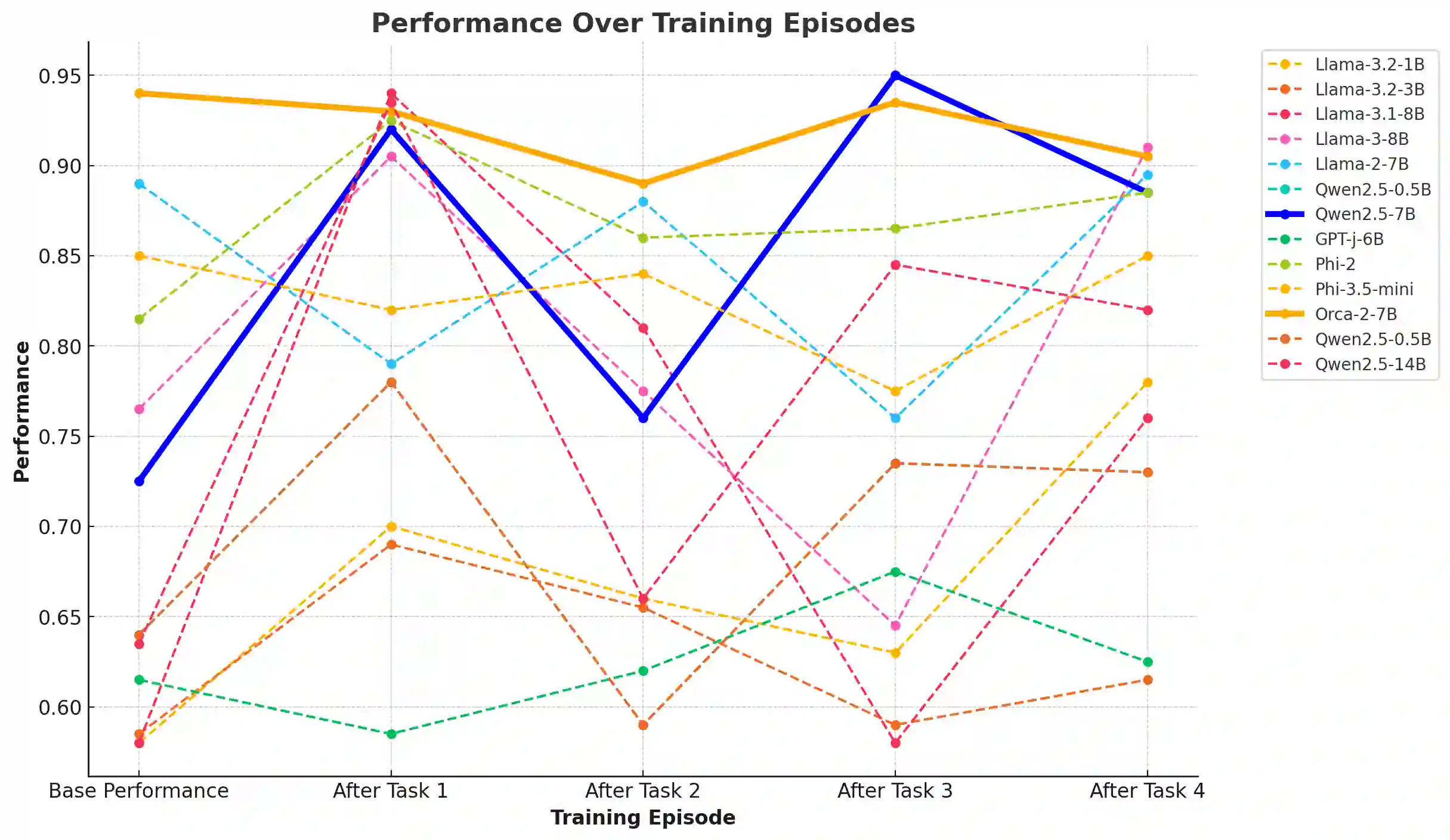
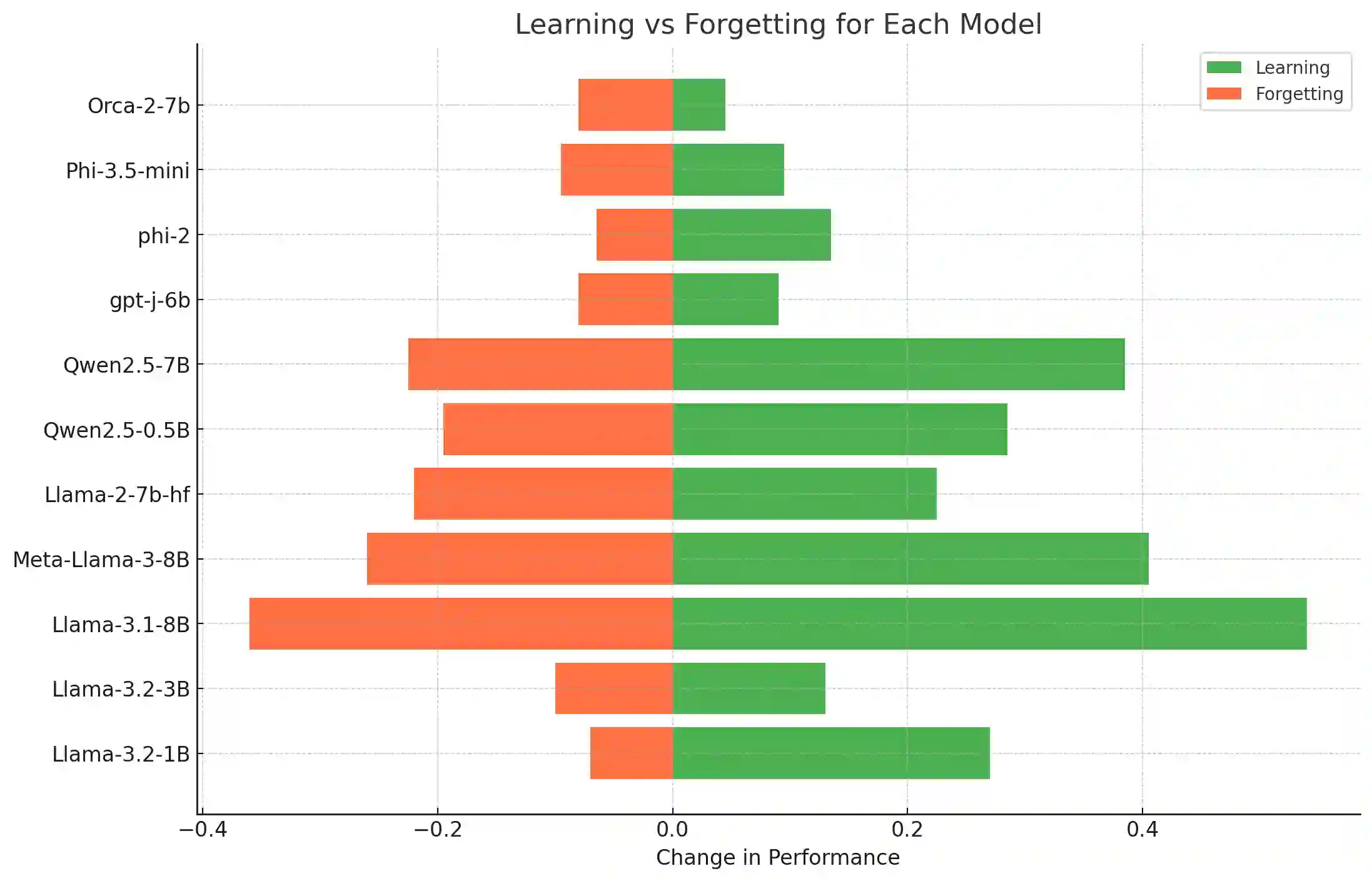
Large Language Models (LLMs) have significantly advanced Natural Language Processing (NLP), particularly in Natural Language Understanding (NLU) tasks. As we progress toward an agentic world where LLM-based agents autonomously handle specialized tasks, it becomes crucial for these models to adapt to new tasks without forgetting previously learned information - a challenge known as catastrophic forgetting. This study evaluates the continual fine-tuning of various open-source LLMs with different parameter sizes (specifically models under 10 billion parameters) on key NLU tasks from the GLUE benchmark, including SST-2, MRPC, CoLA, and MNLI. By employing prompt engineering and task-specific adjustments, we assess and compare the models' abilities to retain prior knowledge while learning new tasks. Our results indicate that models such as Phi-3.5-mini exhibit minimal forgetting while maintaining strong learning capabilities, making them well-suited for continual learning environments. Additionally, models like Orca-2-7b and Qwen2.5-7B demonstrate impressive learning abilities and overall performance after fine-tuning. This work contributes to understanding catastrophic forgetting in LLMs and highlights prompting engineering to optimize model performance for continual learning scenarios.
翻译:大型语言模型(LLMs)显著推动了自然语言处理(NLP)的发展,尤其在自然语言理解(NLU)任务中表现突出。随着我们迈向一个由LLM驱动的智能体世界,这些模型需要自主处理专业任务,因此它们必须能够在适应新任务的同时不遗忘先前学到的信息——这一挑战被称为灾难性遗忘。本研究评估了多种不同参数规模(特别是参数量低于100亿)的开源LLMs在GLUE基准测试中的关键NLU任务(包括SST-2、MRPC、CoLA和MNLI)上的持续微调效果。通过采用提示工程和任务特定调整,我们评估并比较了模型在学习新任务时保留已有知识的能力。结果表明,像Phi-3.5-mini这样的模型在保持强大学习能力的同时表现出极低的遗忘率,非常适合持续学习环境。此外,Orca-2-7b和Qwen2.5-7B等模型在微调后展现出优异的学习能力和整体性能。本研究有助于理解LLMs中的灾难性遗忘现象,并强调了通过提示工程优化模型在持续学习场景中性能的重要性。