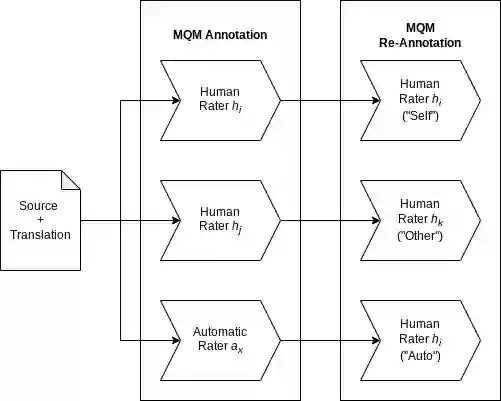
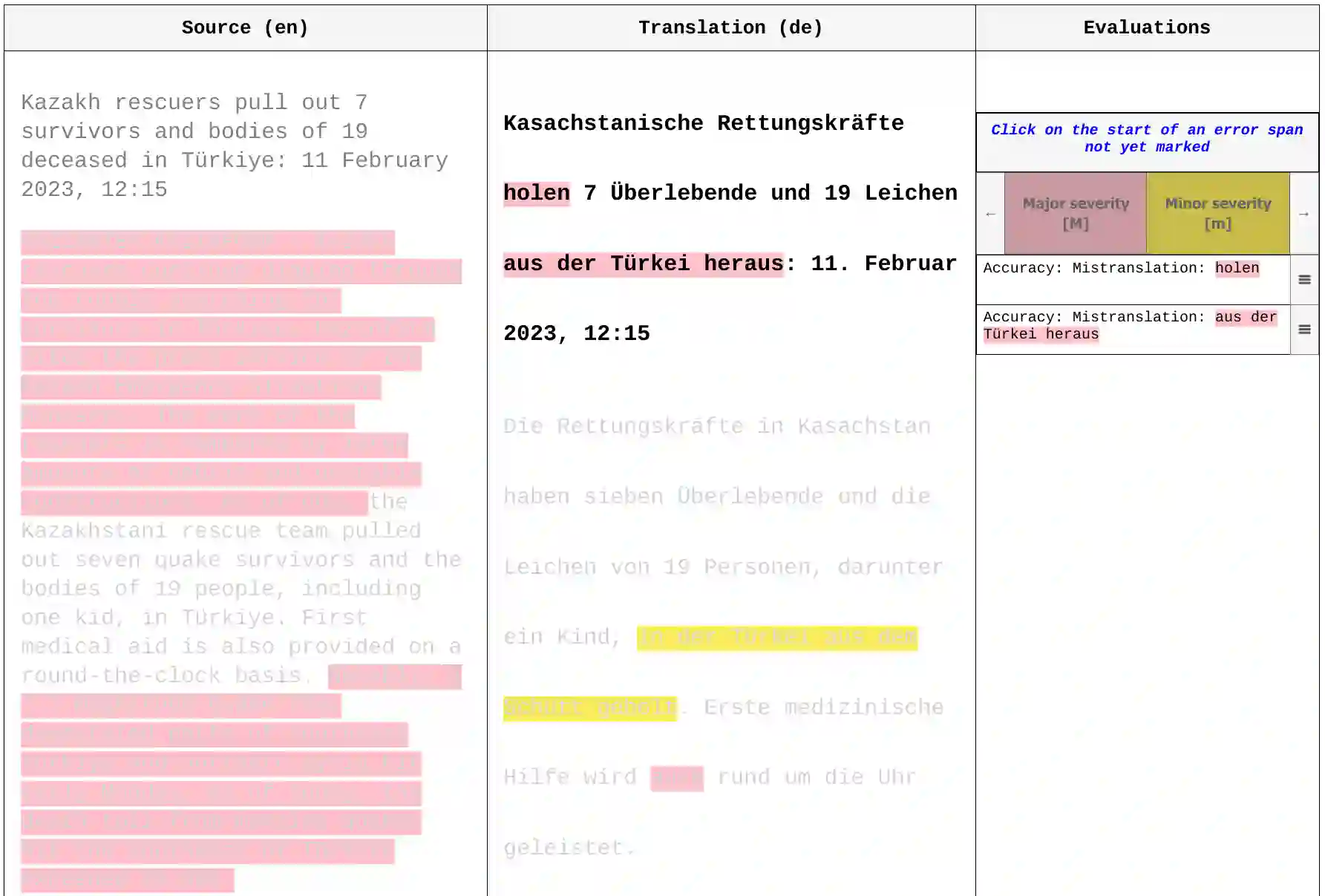
Human evaluation of machine translation is in an arms race with translation model quality: as our models get better, our evaluation methods need to be improved to ensure that quality gains are not lost in evaluation noise. To this end, we experiment with a two-stage version of the current state-of-the-art translation evaluation paradigm (MQM), which we call MQM re-annotation. In this setup, an MQM annotator reviews and edits a set of pre-existing MQM annotations, that may have come from themselves, another human annotator, or an automatic MQM annotation system. We demonstrate that rater behavior in re-annotation aligns with our goals, and that re-annotation results in higher-quality annotations, mostly due to finding errors that were missed during the first pass.
翻译:机器翻译的人工评估与翻译模型质量之间正展开一场军备竞赛:随着模型性能的提升,评估方法也需相应改进,以确保质量增益不会湮没于评估噪声之中。为此,我们尝试对当前最先进的翻译评估范式(MQM)进行两阶段改进,称之为 MQM 重标注。在该框架下,MQM 标注员需审阅并修订一组预先存在的 MQM 标注结果,这些标注可能来自其本人、其他人工标注员或自动 MQM 标注系统。我们证明重标注过程中评估者的行为符合预期目标,且重标注能生成更高质量的标注结果,这主要得益于其能发现初次标注时遗漏的错误。