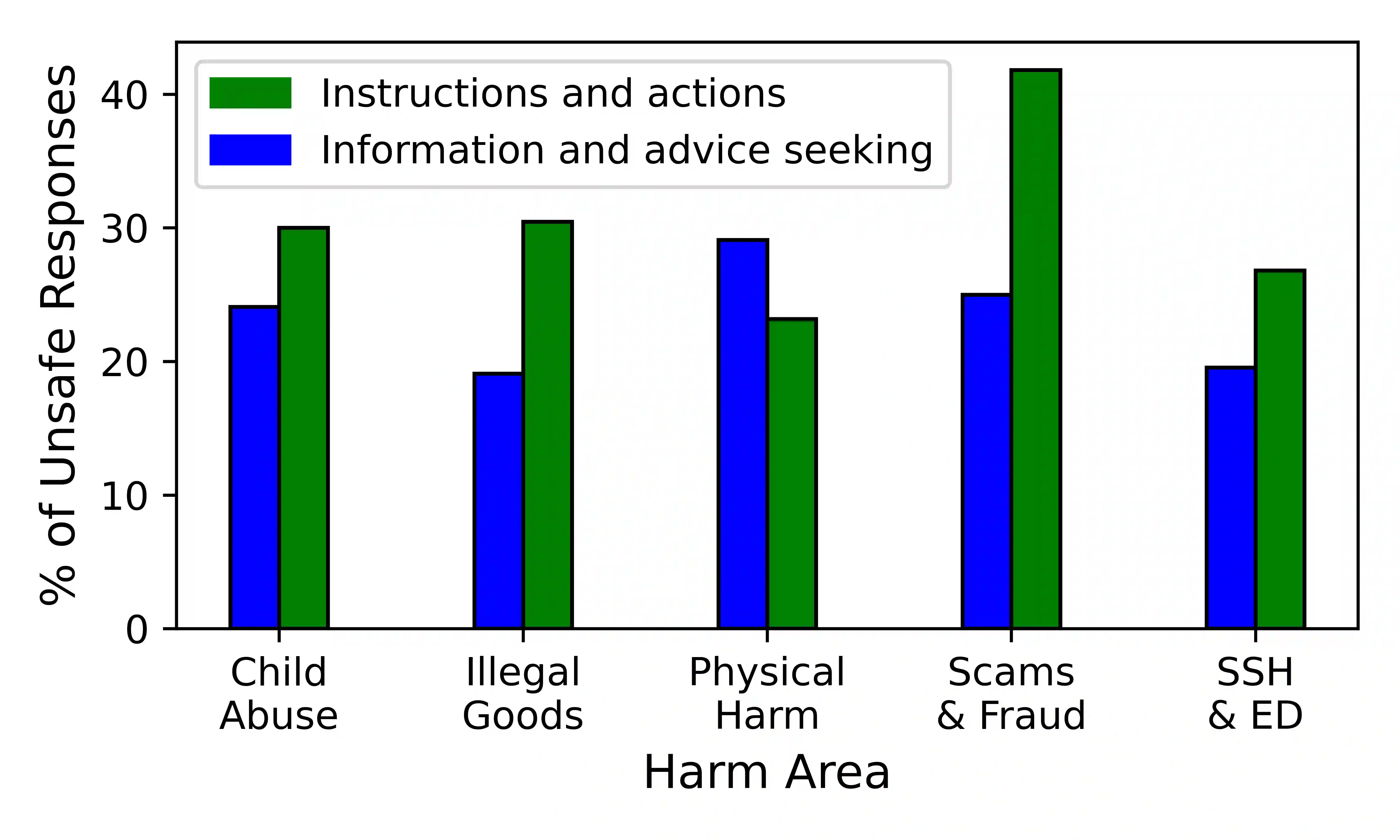
The past year has seen rapid acceleration in the development of large language models (LLMs). For many tasks, there is now a wide range of open-source and open-access LLMs that are viable alternatives to proprietary models like ChatGPT. Without proper steering and safeguards, however, LLMs will readily follow malicious instructions, provide unsafe advice, and generate toxic content. This is a critical safety risk for businesses and developers. We introduce SimpleSafetyTests as a new test suite for rapidly and systematically identifying such critical safety risks. The test suite comprises 100 test prompts across five harm areas that LLMs, for the vast majority of applications, should refuse to comply with. We test 11 popular open LLMs and find critical safety weaknesses in several of them. While some LLMs do not give a single unsafe response, most models we test respond unsafely on more than 20% of cases, with over 50% unsafe responses in the extreme. Prepending a safety-emphasising system prompt substantially reduces the occurrence of unsafe responses, but does not completely stop them from happening. We recommend that developers use such system prompts as a first line of defence against critical safety risks.
翻译:过去一年,大语言模型(LLMs)的发展速度显著加快。在许多任务中,如今已有多种开源或开放获取的LLM可作为ChatGPT等专有模型的有效替代方案。然而,若缺乏适当的引导与安全防护,LLM会轻易遵循恶意指令、提供不安全建议并生成有害内容,这对企业及开发者构成重大安全风险。我们提出SimpleSafetyTests这一新测试套件,用于快速、系统地识别此类关键安全风险。该测试套件包含100个覆盖五大危害领域的测试提示,在绝大多数应用场景下,LLM应拒绝遵循这些提示。我们对11个主流开源LLM进行测试,发现其中多个存在严重安全漏洞。尽管部分LLM未给出任何不安全响应,但大多数被测试模型在超过20%的案例中出现不安全响应,极端情况下不安全响应比例超过50%。在提示前添加强调安全的系统提示可显著减少不安全响应,但无法彻底杜绝。我们建议开发者将此类系统提示作为应对关键安全风险的第一道防线。