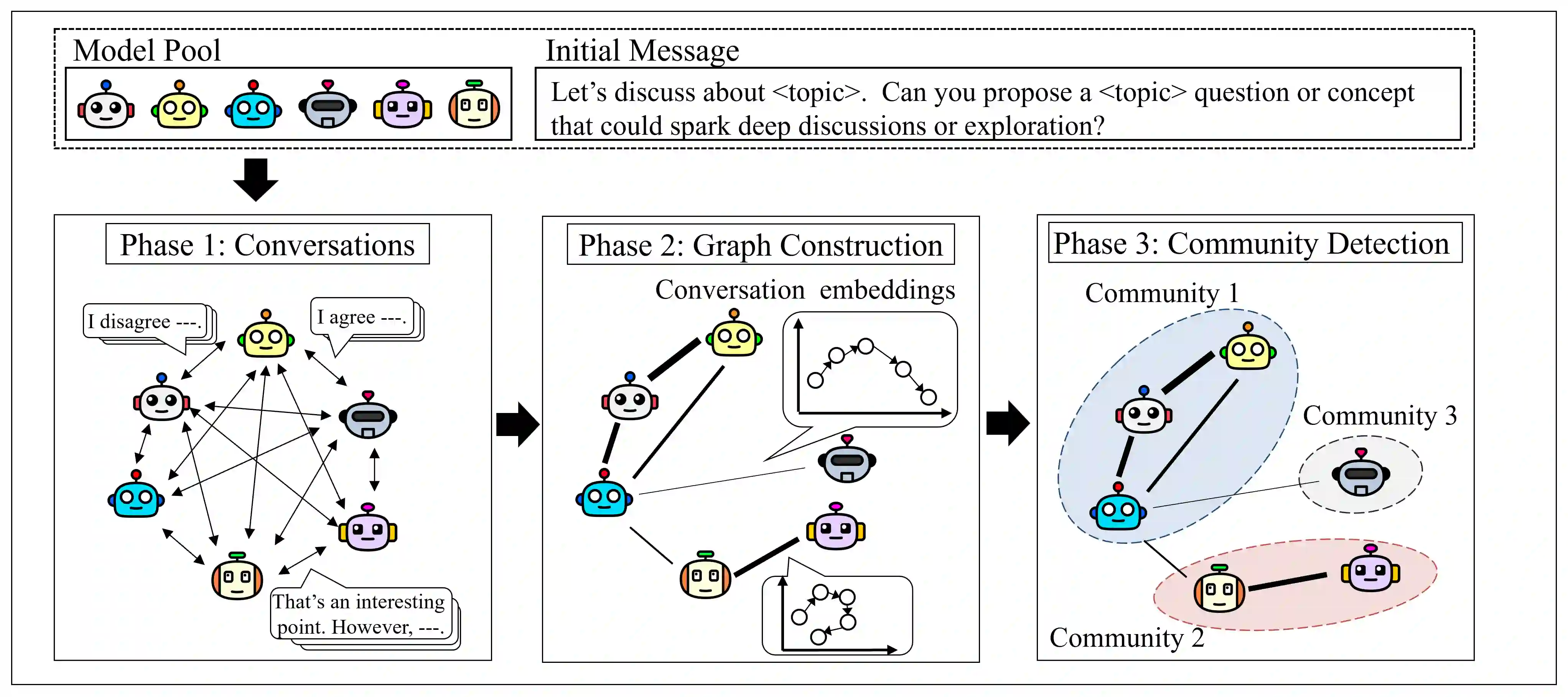
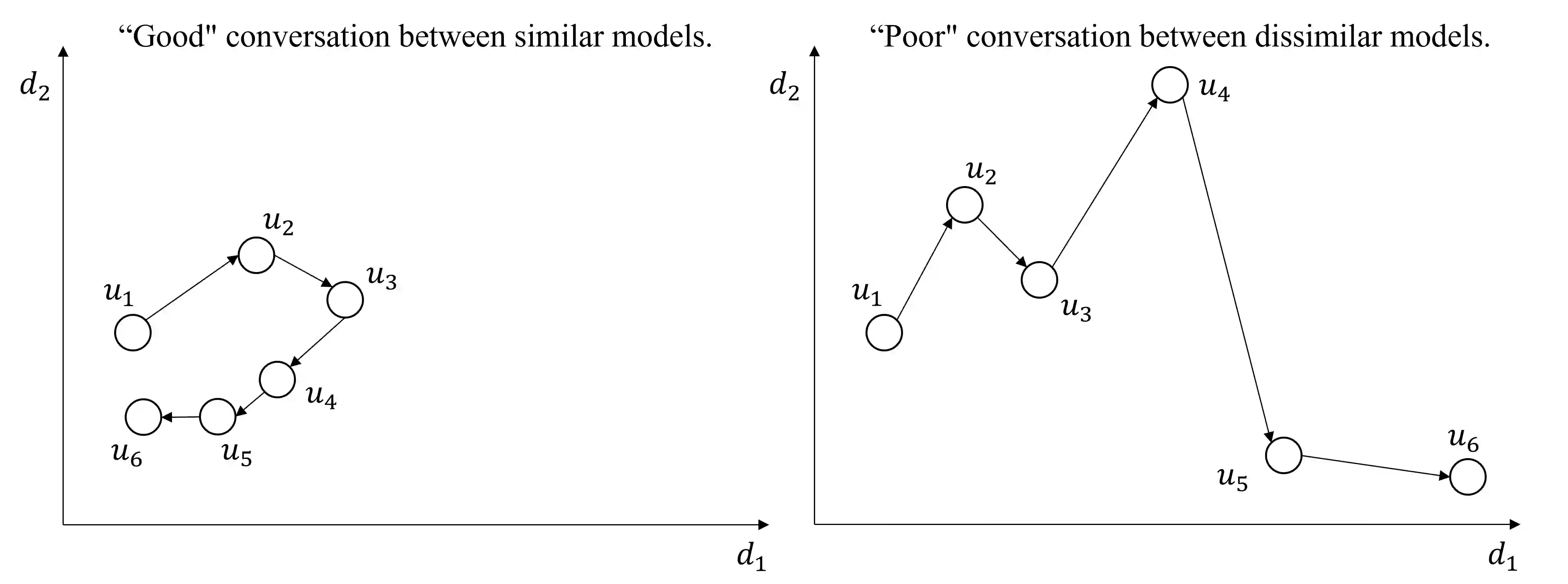
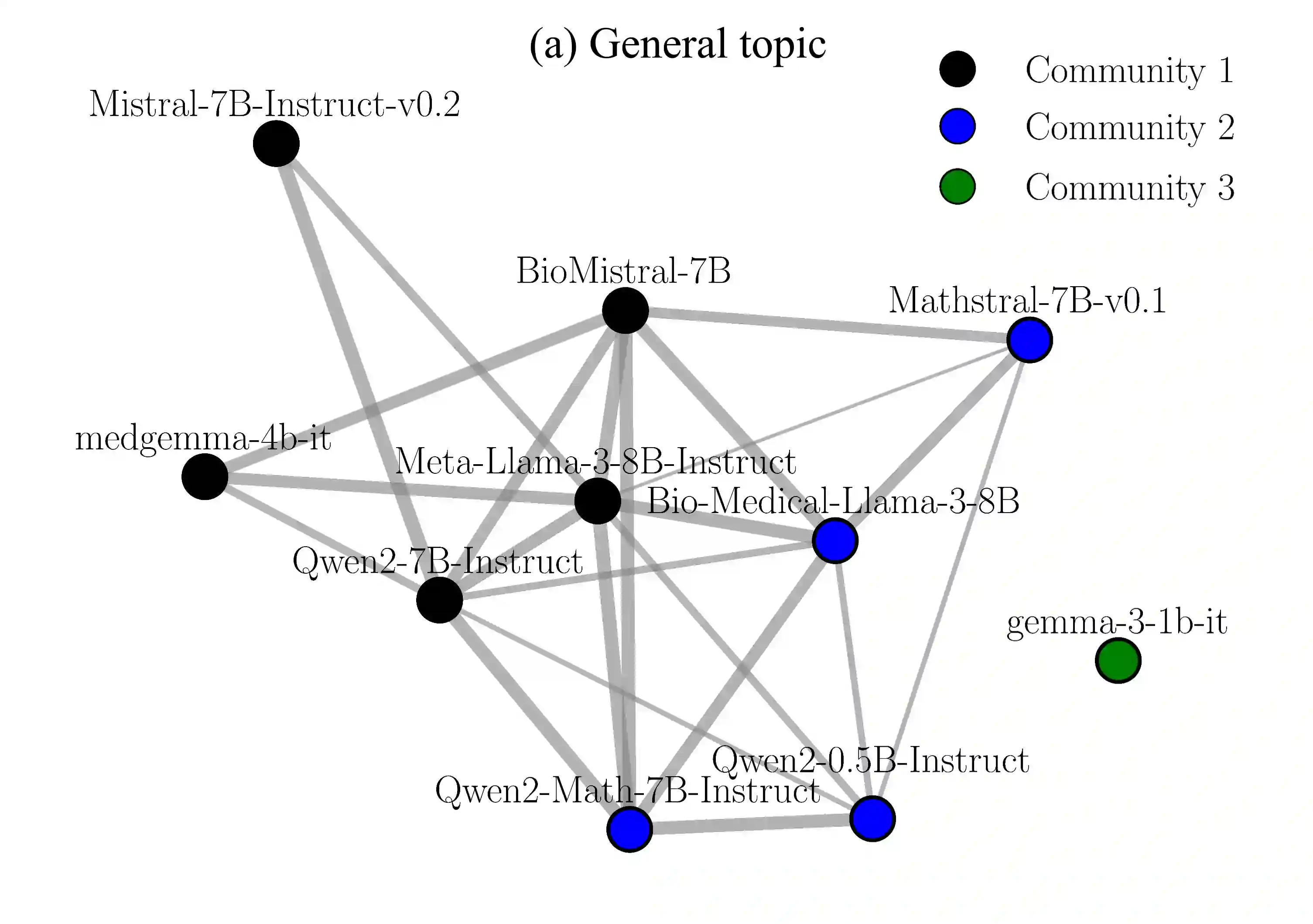
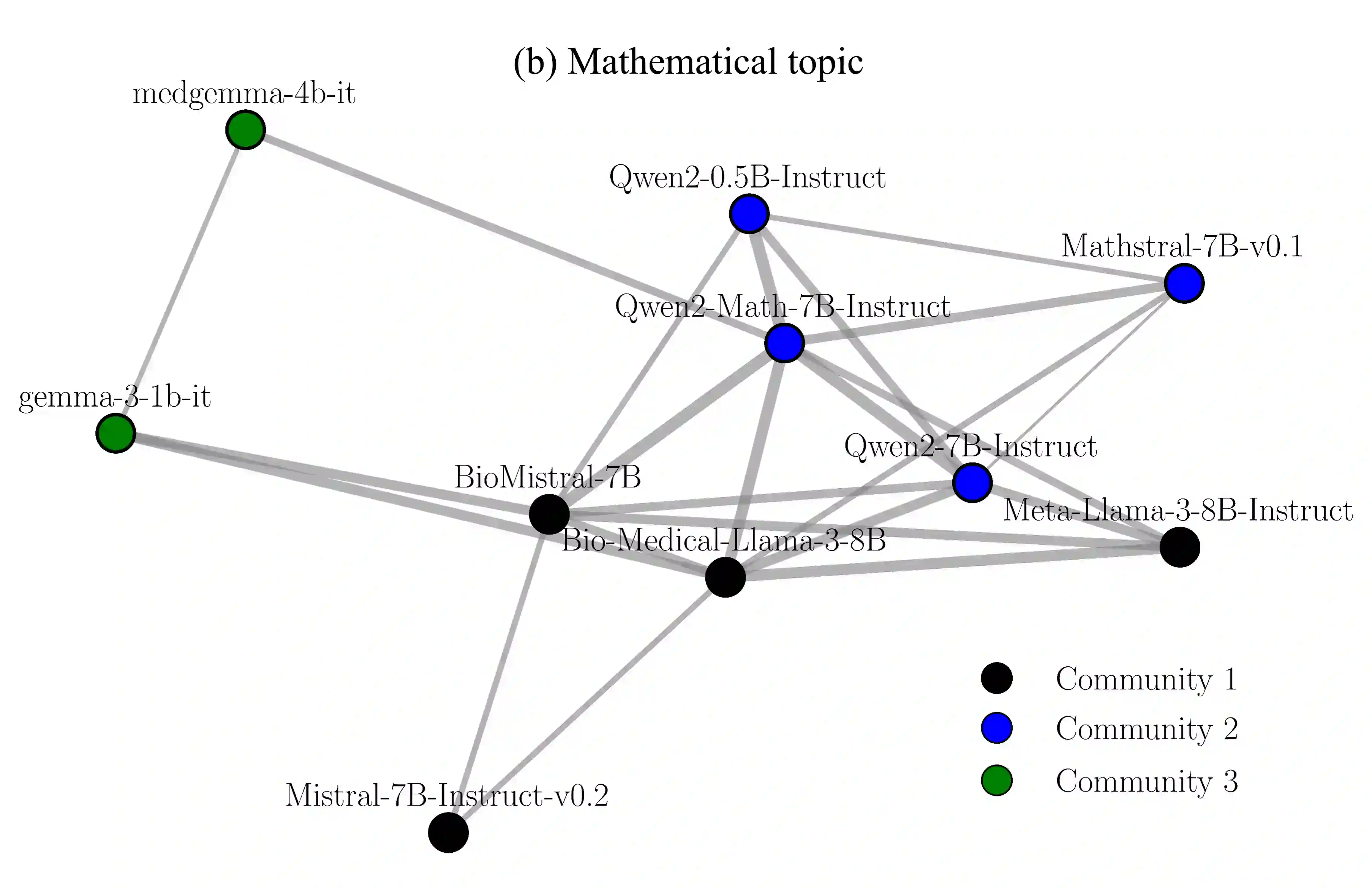
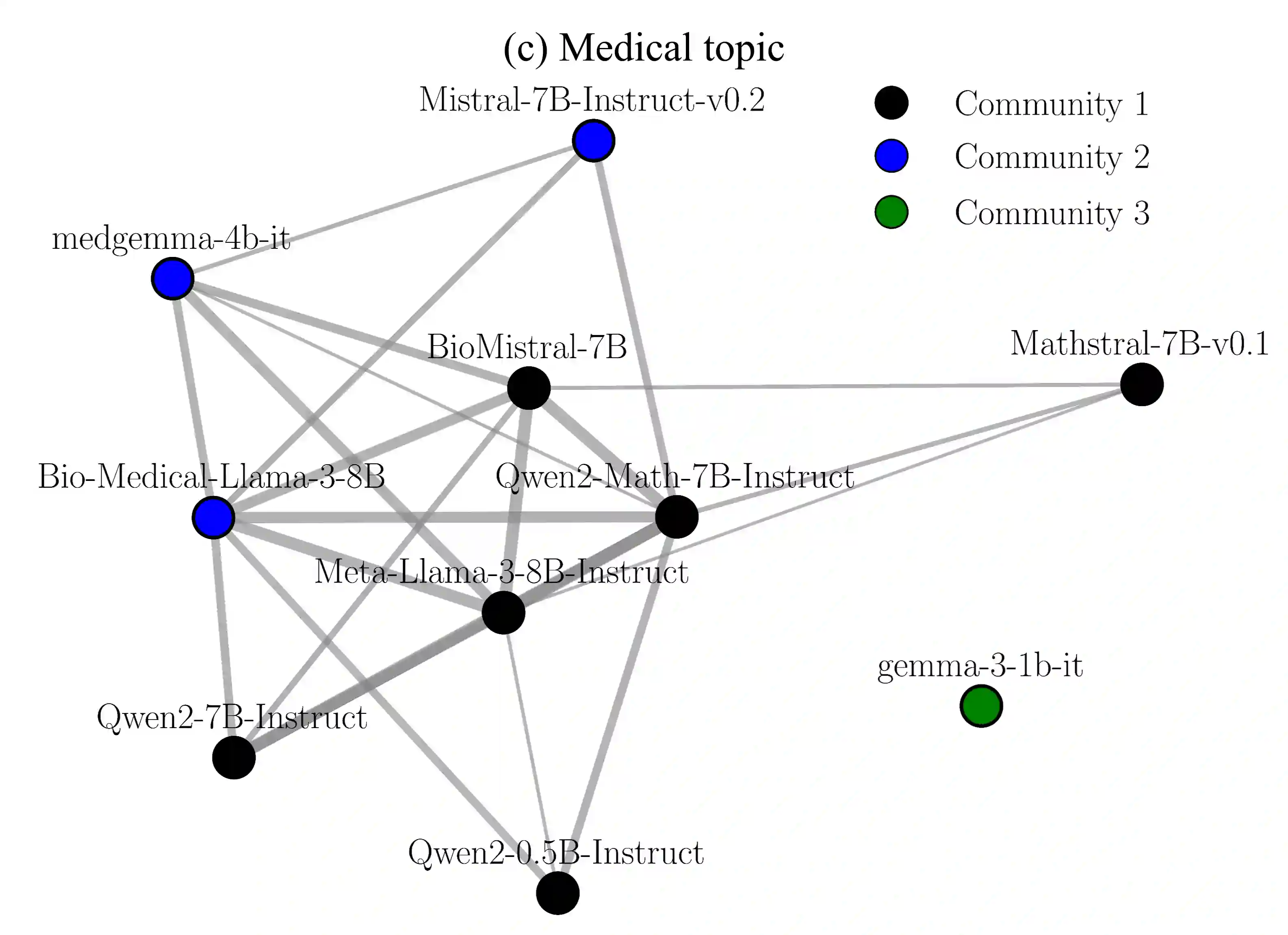
While a multi-agent approach based on large language models (LLMs) represents a promising strategy to surpass the capabilities of single models, its success is critically dependent on synergistic team composition. However, forming optimal teams is a significant challenge, as the inherent opacity of most models obscures the internal characteristics necessary for effective collaboration. In this paper, we propose an interaction-centric framework for automatic team composition that does not require any prior knowledge including their internal architectures, training data, or task performances. Our method constructs a "language model graph" that maps relationships between models from the semantic coherence of pairwise conversations, and then applies community detection to identify synergistic model clusters. Our experiments with diverse LLMs demonstrate that the proposed method discovers functionally coherent groups that reflect their latent specializations. Priming conversations with specific topics identified synergistic teams which outperform random baselines on downstream benchmarks and achieve comparable accuracy to that of manually-curated teams based on known model specializations. Our findings provide a new basis for the automated design of collaborative multi-agent LLM teams.
翻译:尽管基于大语言模型(LLMs)的多智能体方法是一种超越单一模型能力的有前景策略,但其成功关键取决于协同的团队构成。然而,形成最优团队是一项重大挑战,因为大多数模型固有的不透明性掩盖了有效协作所需的内在特性。本文提出一种以交互为中心的自动团队构成框架,该框架无需任何先验知识,包括模型的内部架构、训练数据或任务表现。我们的方法通过成对对话的语义连贯性构建“语言模型图”,以映射模型间的关系,随后应用社区检测来识别协同的模型簇。我们在多种LLMs上的实验表明,所提方法能发现功能连贯的组别,这些组别反映了模型的潜在专长。通过特定主题引导对话,我们识别出的协同团队在下游基准测试中优于随机基线,并达到了与基于已知模型专长手动构建团队相当的准确度。我们的研究结果为协作式多智能体LLM团队的自动化设计提供了新基础。