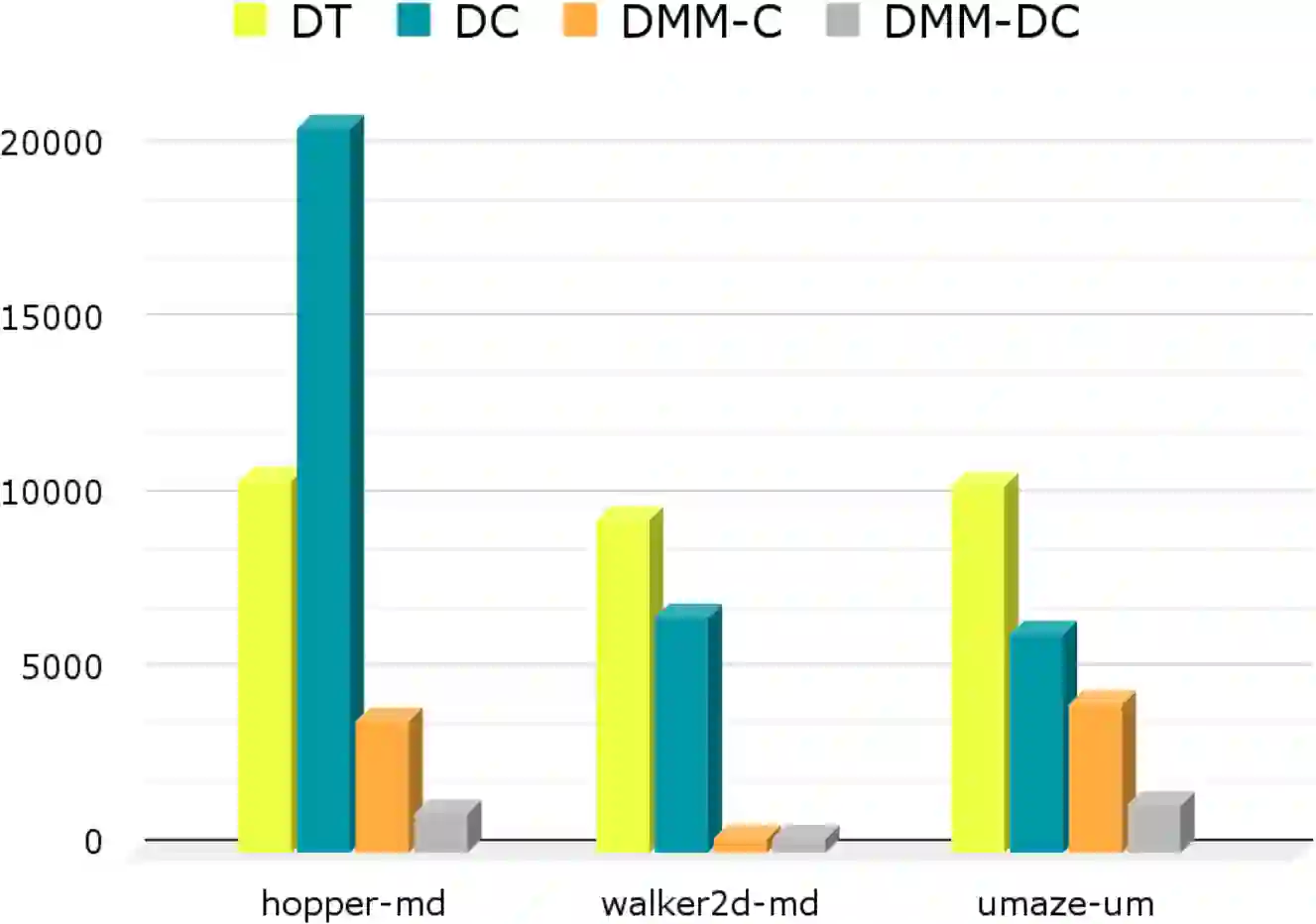
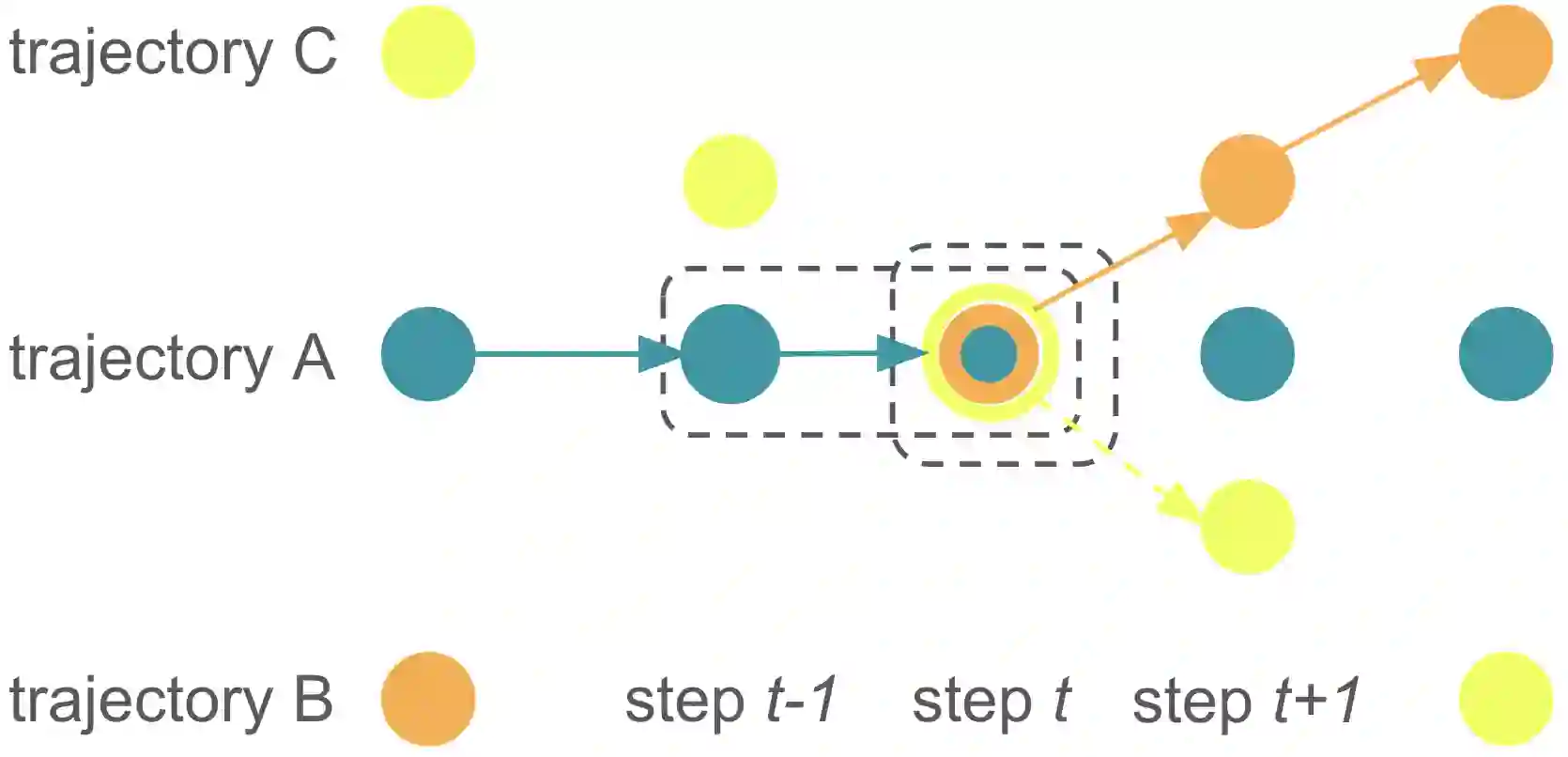
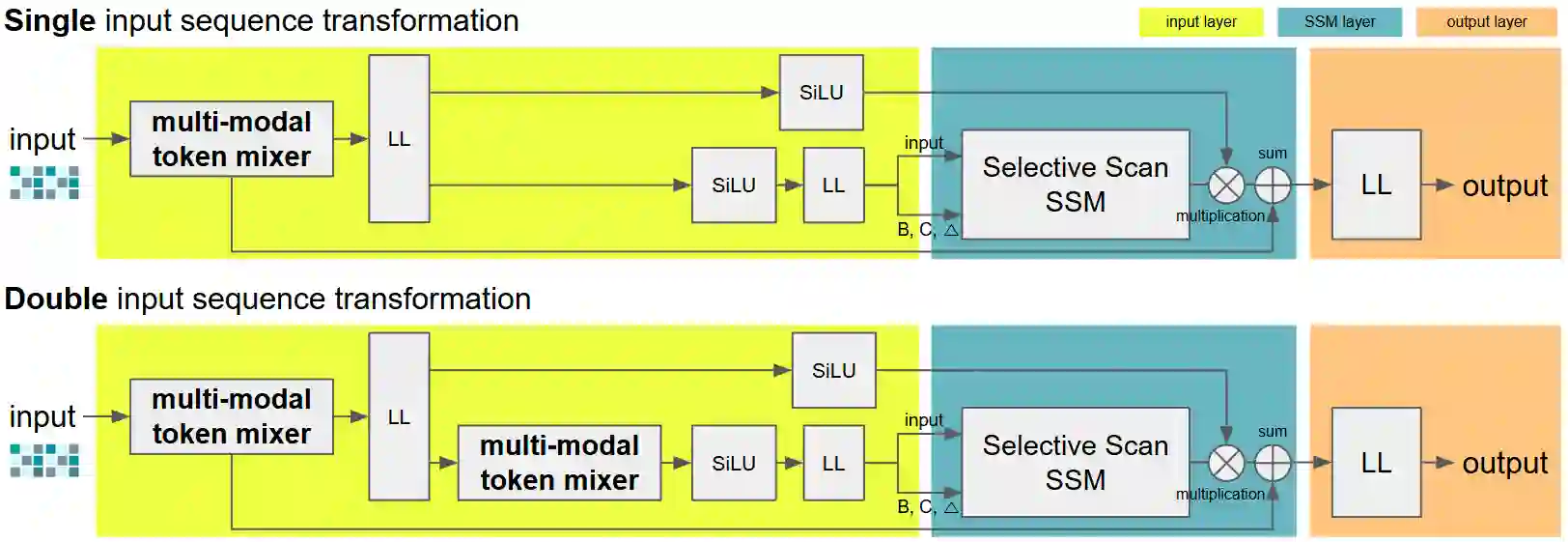
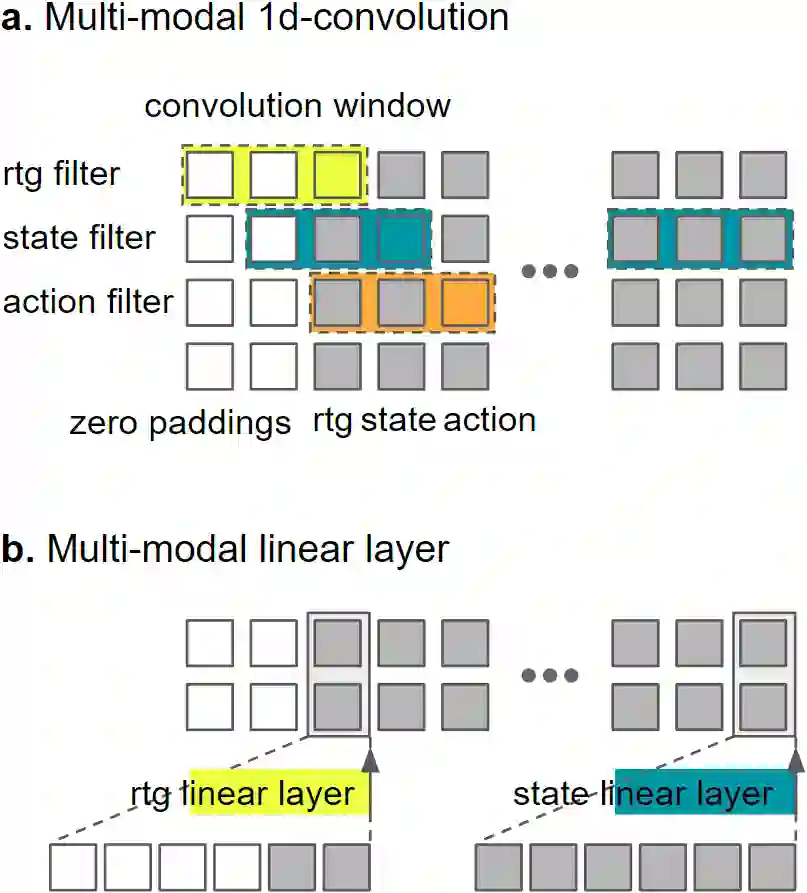
Sequence modeling with State Space models (SSMs) has demonstrated performance surpassing that of Transformers in various tasks, raising expectations for their potential to outperform the Decision Transformer and its enhanced variants in offline reinforcement learning (RL). However, decision models based on Mamba, a state-of-the-art SSM, failed to achieve superior performance compared to these enhanced Decision Transformers. We hypothesize that this limitation arises from information loss during the selective scanning phase. To address this, we propose the Decision MetaMamba (DMM), which augments Mamba with a token mixer in its input layer. This mixer explicitly accounts for the multimodal nature of offline RL inputs, comprising state, action, and return-to-go. The DMM demonstrates improved performance while significantly reducing parameter count compared to prior models. Notably, similar performance gains were achieved using a simple linear token mixer, emphasizing the importance of preserving information from proximate time steps rather than the specific design of the token mixer itself. This novel modification to Mamba's input layer represents a departure from conventional timestamp-based encoding approaches used in Transformers. By enhancing performance of Mamba in offline RL, characterized by memory efficiency and fast inference, this work opens new avenues for its broader application in future RL research.
翻译:基于状态空间模型(SSMs)的序列建模已在多种任务中展现出超越Transformer的性能,这提升了人们对其在离线强化学习(RL)中超越决策Transformer及其增强变体的期望。然而,基于当前最先进SSM——Mamba的决策模型,未能实现相对于这些增强型决策Transformer的优越性能。我们假设这一局限源于选择性扫描阶段的信息损失。为解决此问题,我们提出了决策元Mamba(DMM),其在Mamba的输入层中引入了一个令牌混合器。该混合器明确考虑了离线RL输入的多模态性质,这些输入包含状态、动作和剩余回报。DMM在显著减少参数数量的同时,展现出优于先前模型的性能。值得注意的是,使用简单的线性令牌混合器也能实现类似的性能提升,这强调了保留邻近时间步信息的重要性,而非令牌混合器本身的具体设计。这种对Mamba输入层的新颖修改,代表了与Transformer中常用的基于时间戳编码方法的背离。通过提升Mamba在离线RL中的性能——该领域以内存高效和快速推理为特点,这项工作为其在未来RL研究中的更广泛应用开辟了新途径。