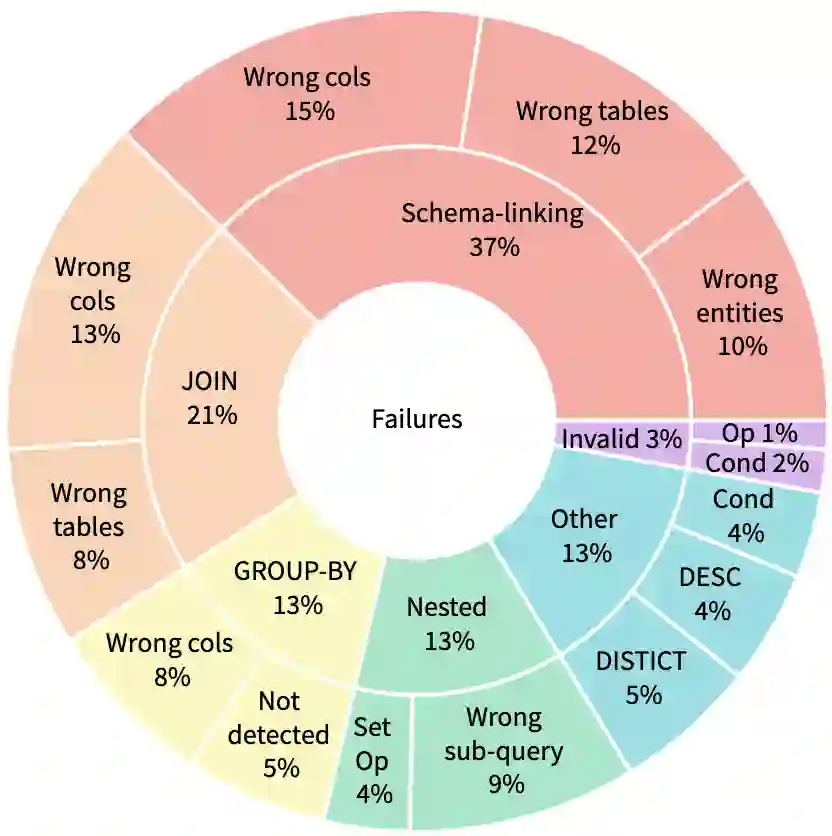
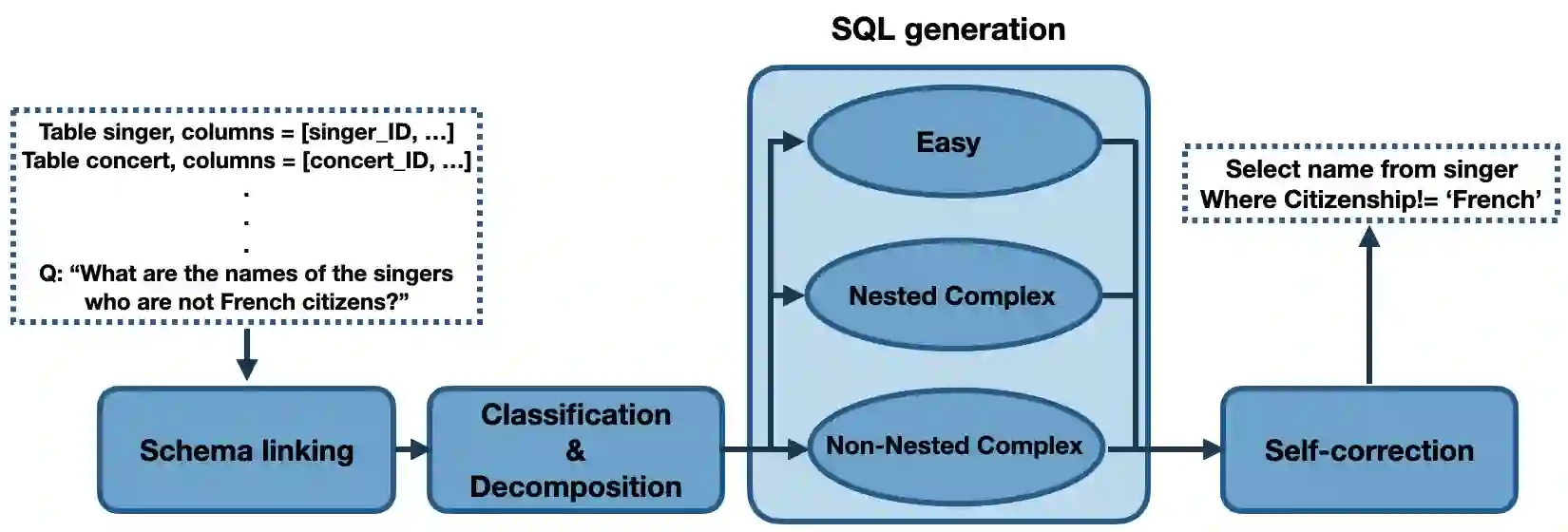
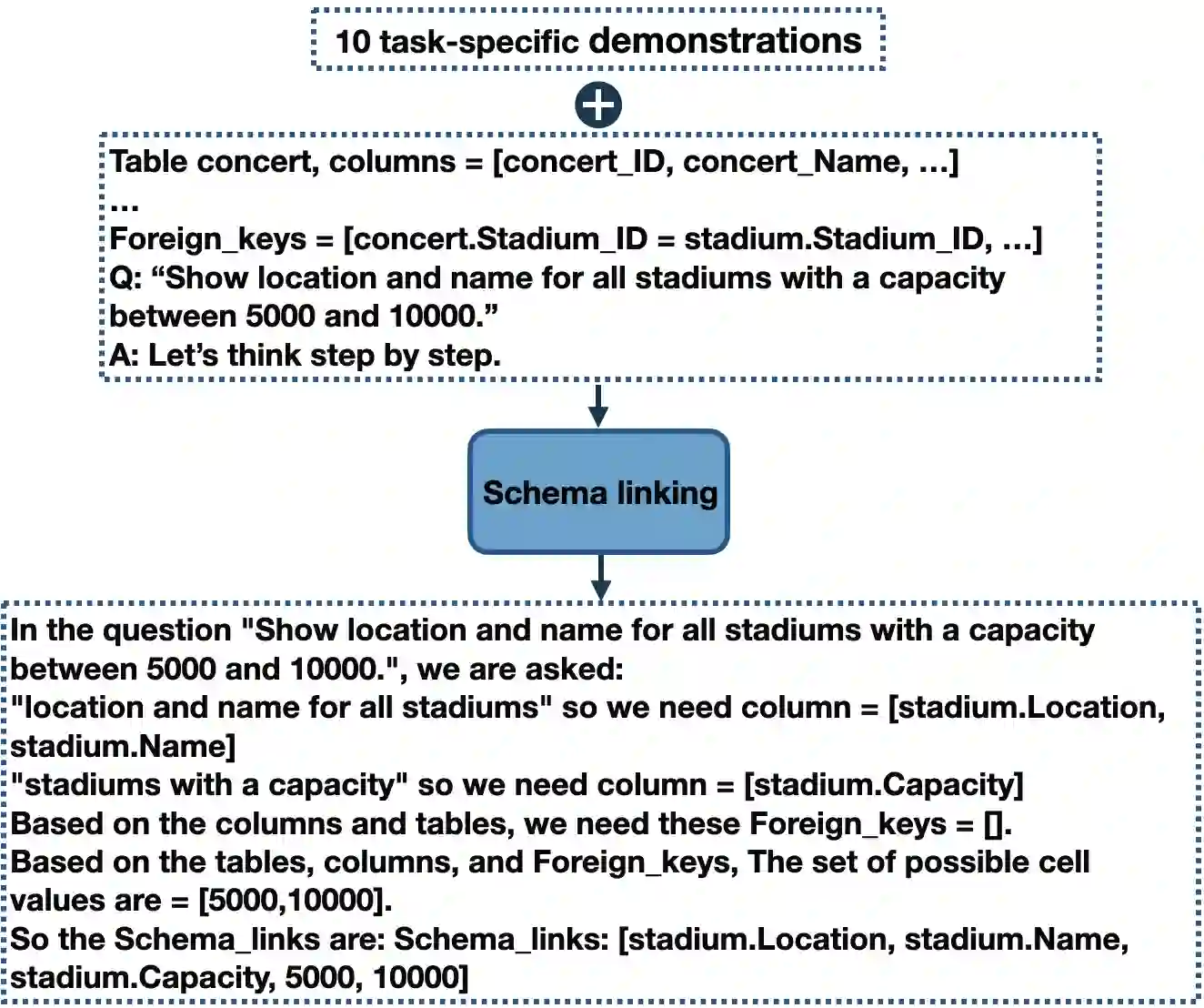
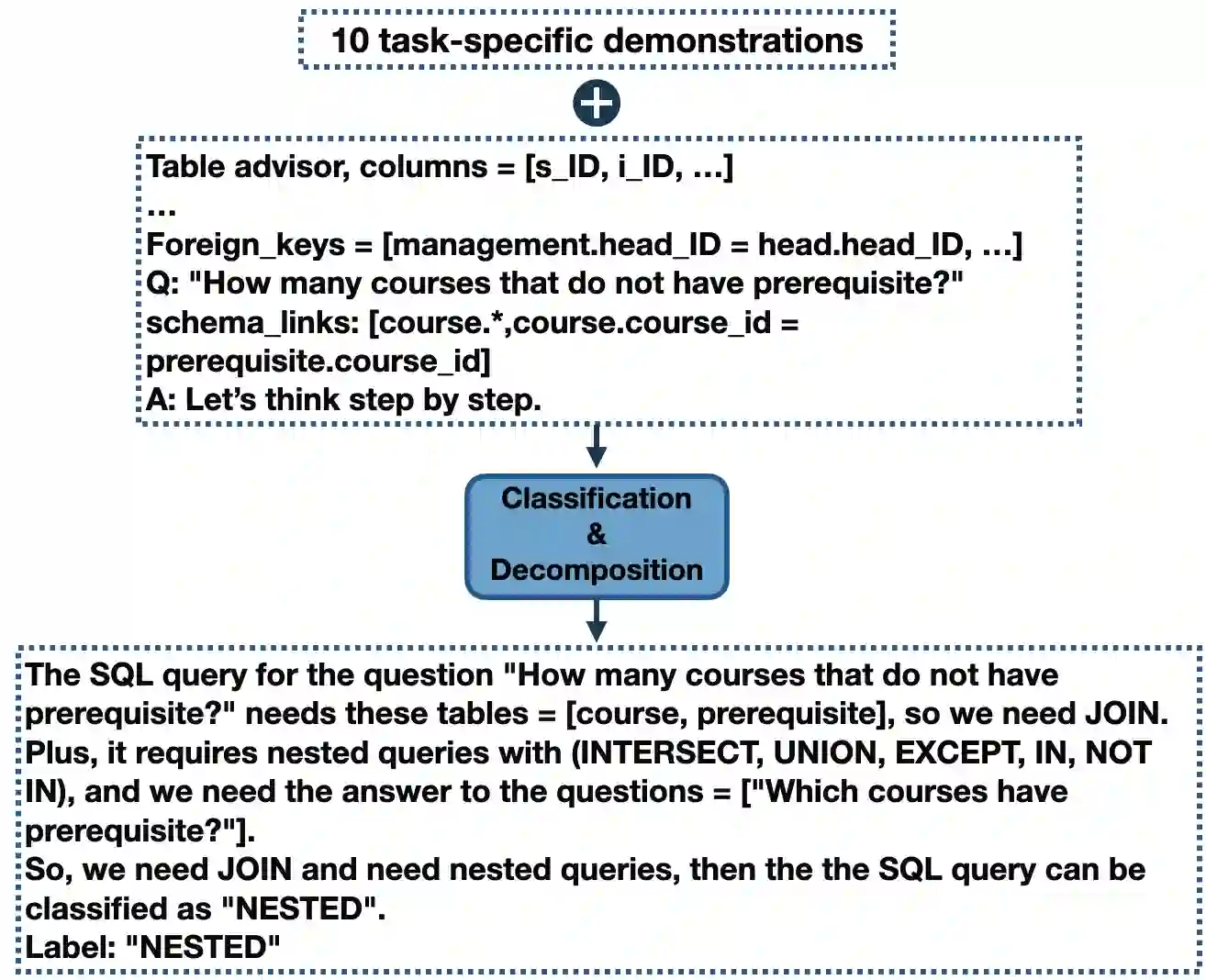
We study the problem of decomposing a complex text-to-sql task into smaller sub-tasks and how such a decomposition can significantly improve the performance of Large Language Models (LLMs) in the reasoning process. There is currently a significant gap between the performance of fine-tuned models and prompting approaches using LLMs on challenging text-to-sql datasets such as Spider. We show that SQL queries, despite their declarative structure, can be broken down into sub-problems and the solutions of those sub-problems can be fed into LLMs to significantly improve their performance. Our experiments with three LLMs show that this approach consistently improves their performance by roughly 10%, pushing the accuracy of LLMs towards state-of-the-art, and even beating large fine-tuned models on the holdout Spider dataset.
翻译:我们研究了将复杂文本到SQL任务分解为更小子任务的问题,并探讨了这种分解如何能在推理过程中显著提升大型语言模型(LLMs)的性能。目前,在Spider等具有挑战性的文本到SQL数据集上,微调模型与使用LLMs的提示方法之间存在显著性能差距。我们证明,尽管SQL查询具有声明性结构,但可以将其分解为子问题,并将这些子问题的解决方案输入LLMs,从而显著提升其性能。通过使用三种LLMs进行的实验表明,该方法能持续提升约10%的性能,使LLMs的准确率接近当前最优水平,甚至在保留的Spider数据集上超越了大型微调模型。