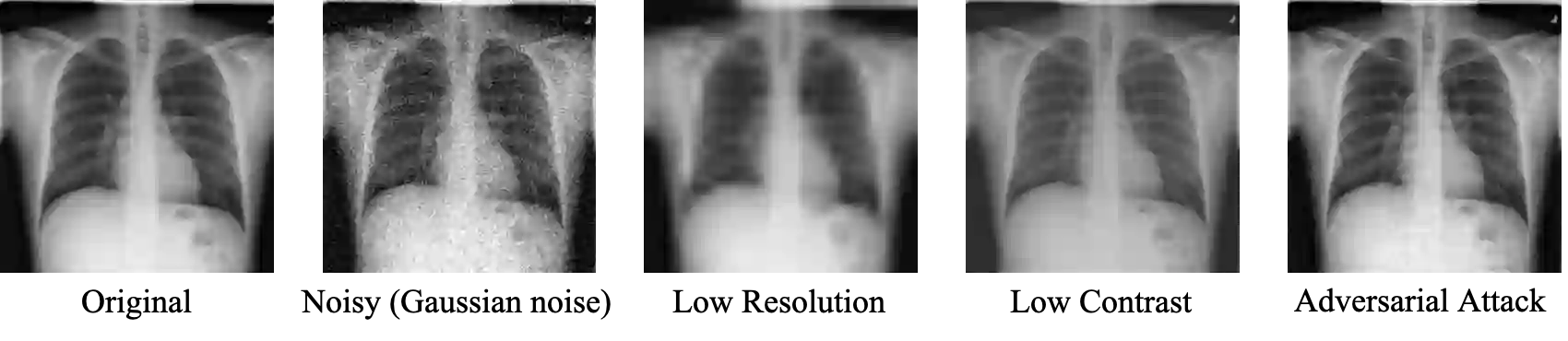
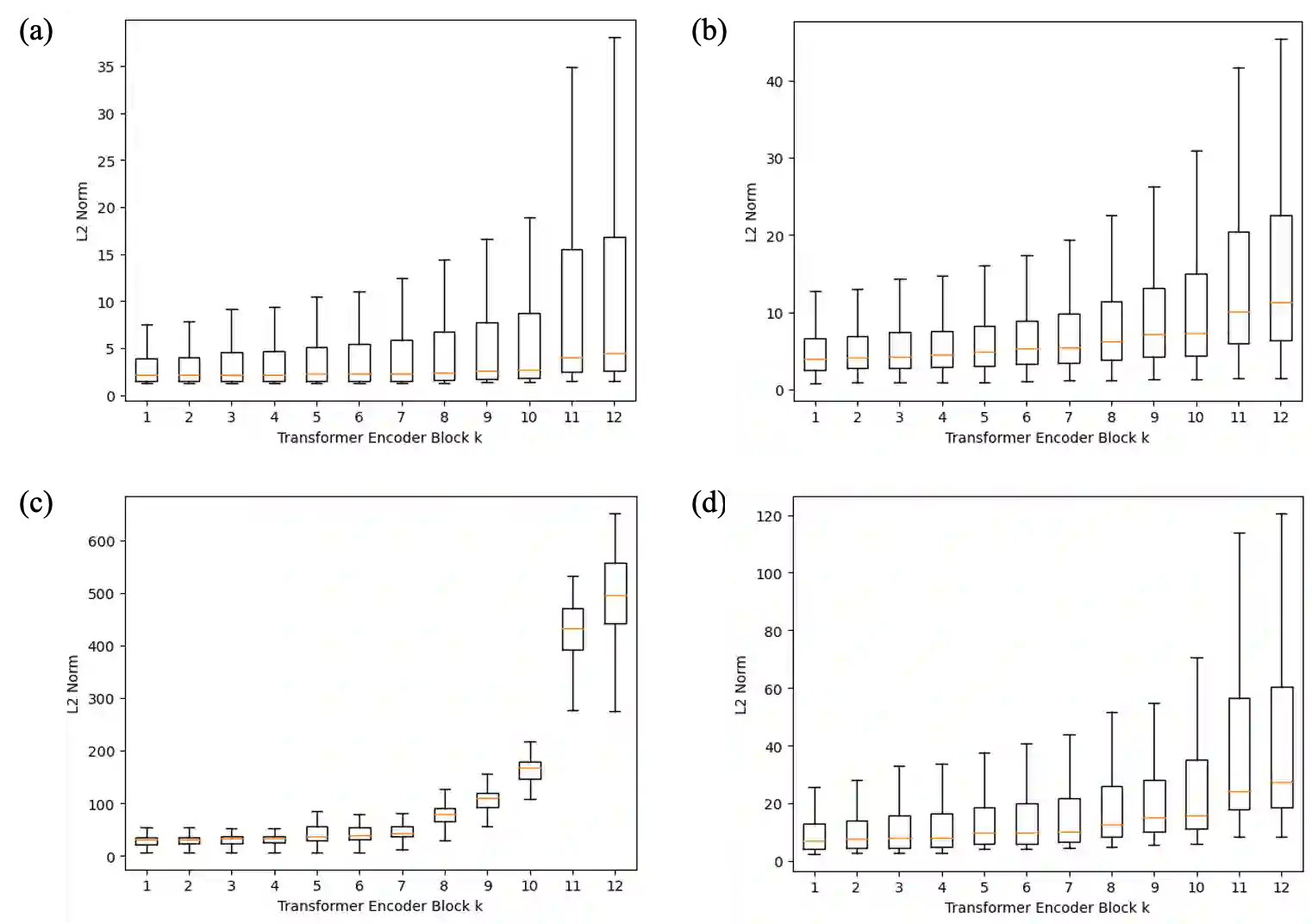
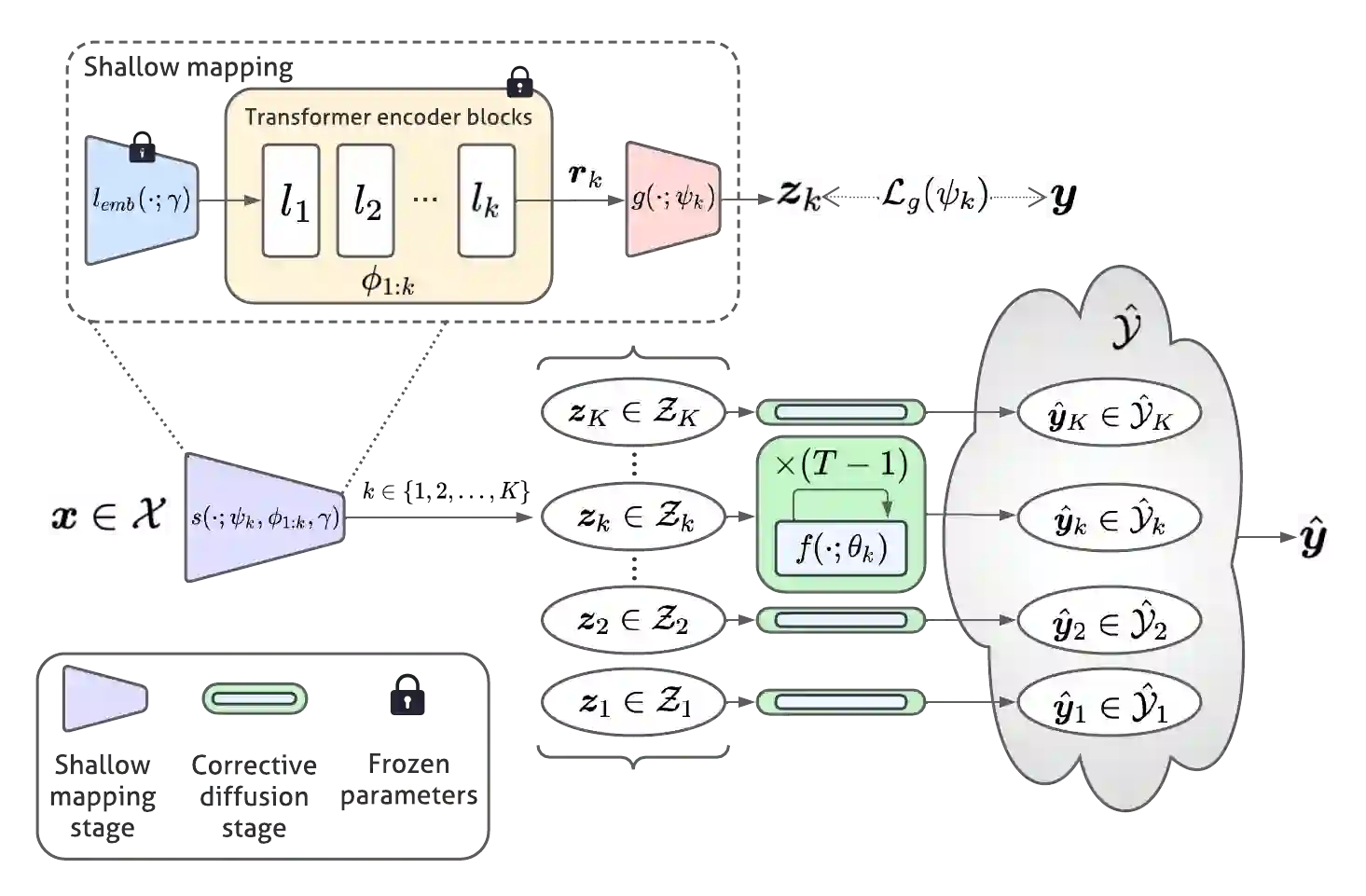
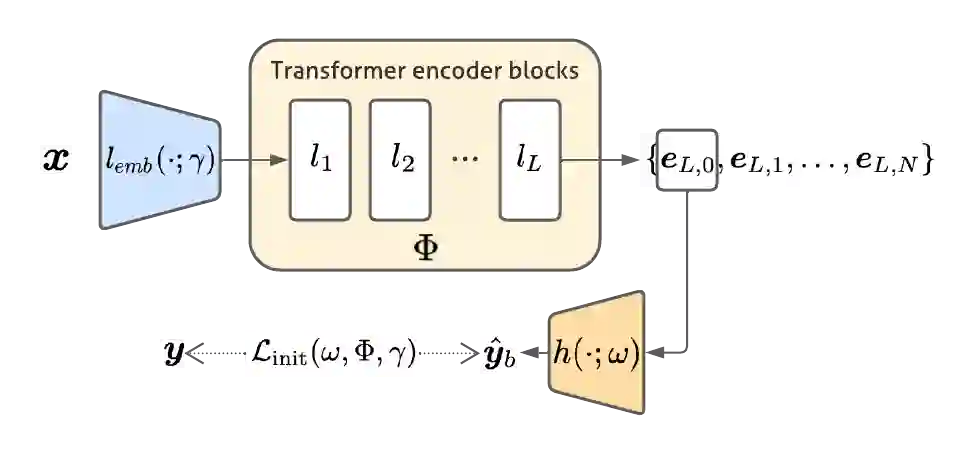
While deep learning models have achieved remarkable success across a range of medical image analysis tasks, deployment of these models in real clinical contexts requires that they be robust to variability in the acquired images. While many methods apply predefined transformations to augment the training data to enhance test-time robustness, these transformations may not ensure the model's robustness to the diverse variability seen in patient images. In this paper, we introduce a novel three-stage approach based on transformers coupled with conditional diffusion models, with the goal of improving model robustness to the kinds of imaging variability commonly encountered in practice without the need for pre-determined data augmentation strategies. To this end, multiple image encoders first learn hierarchical feature representations to build discriminative latent spaces. Next, a reverse diffusion process, guided by the latent code, acts on an informative prior and proposes prediction candidates in a generative manner. Finally, several prediction candidates are aggregated in a bi-level aggregation protocol to produce the final output. Through extensive experiments on medical imaging benchmark datasets, we show that our method improves upon state-of-the-art methods in terms of robustness and confidence calibration. Additionally, we introduce a strategy to quantify the prediction uncertainty at the instance level, increasing their trustworthiness to clinicians using them in clinical practice.
翻译:尽管深度学习模型在多项医学图像分析任务中取得了显著成功,但将其部署至真实临床环境时,必须确保模型对采集图像中变异性的鲁棒性。现有方法多采用预定义变换增强训练数据以提升测试阶段鲁棒性,但这些变换可能无法保证模型对患者图像中多样化变异性的适应能力。本文提出了一种基于Transformer与条件扩散模型的三阶段新颖方法,旨在无需预设数据增强策略的前提下,提升模型对临床实践中常见成像变异性的鲁棒性。该方法首先通过多个图像编码器学习层次化特征表征以构建判别性潜在空间;随后,由潜在编码引导的逆扩散过程作用于信息性先验,以生成式方式提出预测候选;最后,通过双层聚合协议整合多个预测候选以产生最终输出。在医学影像基准数据集上的大量实验表明,本方法在鲁棒性和置信度校准方面优于现有最先进方法。此外,我们还引入了一种量化实例级预测不确定性的策略,从而提升临床医生使用这些模型时的可信度。