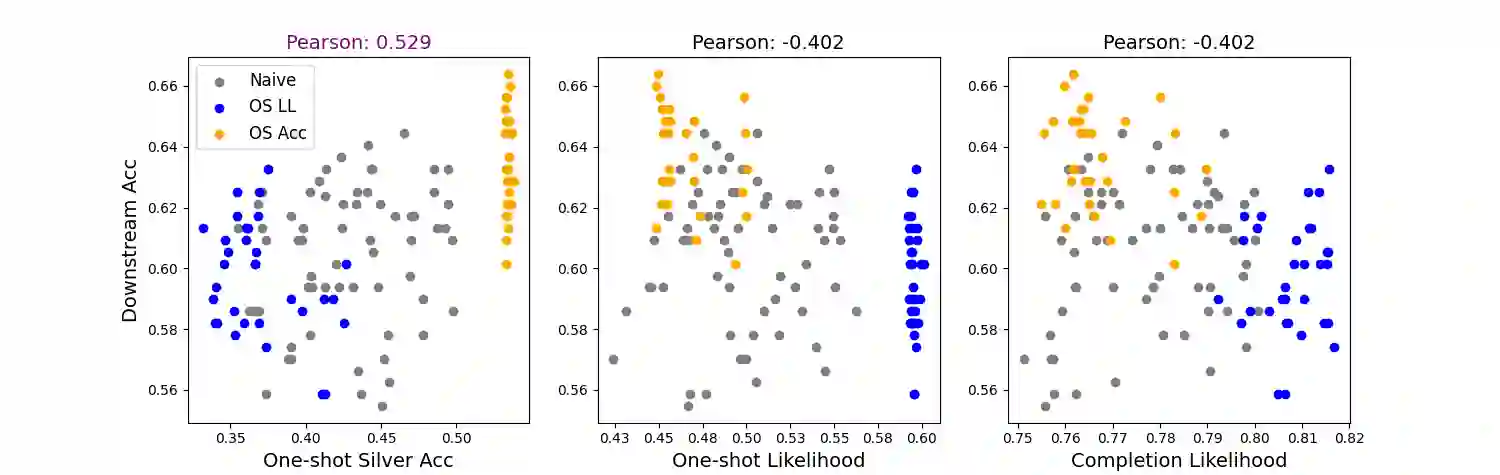
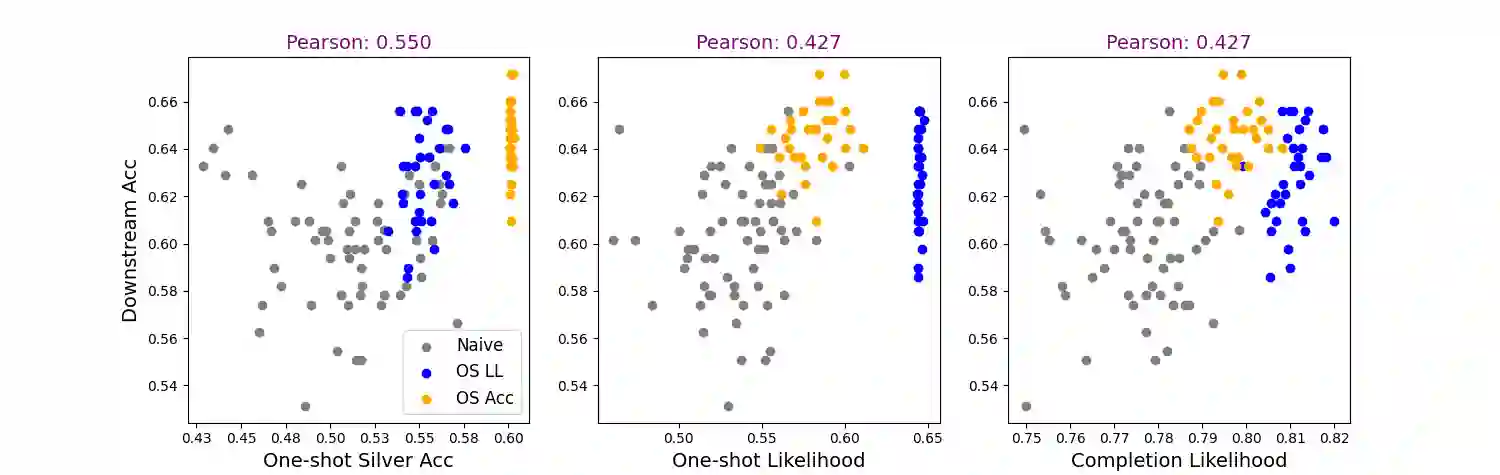
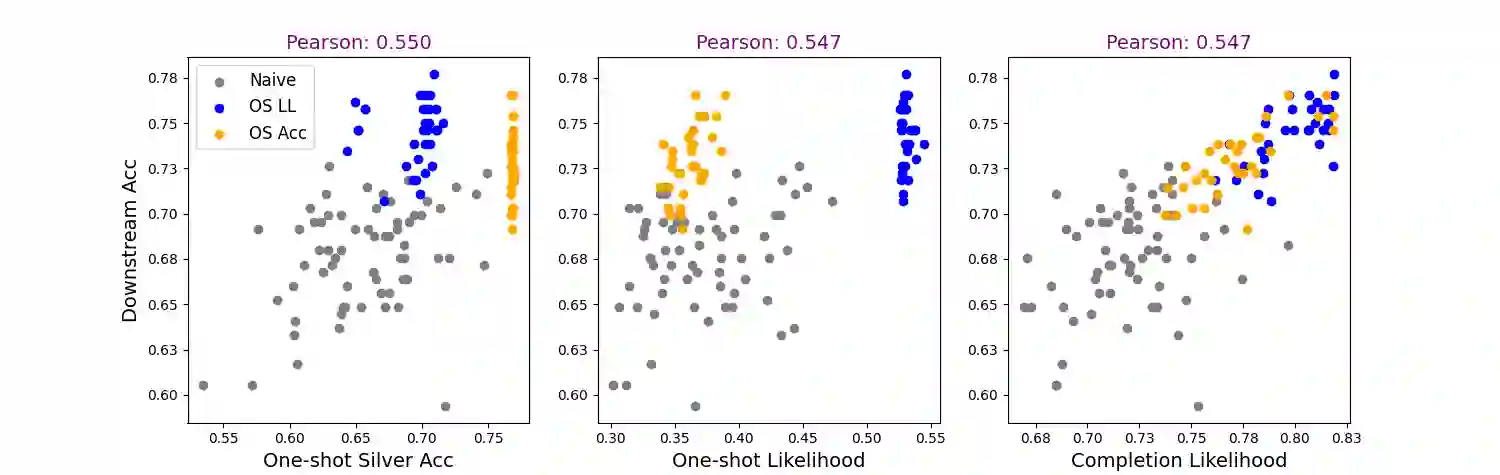
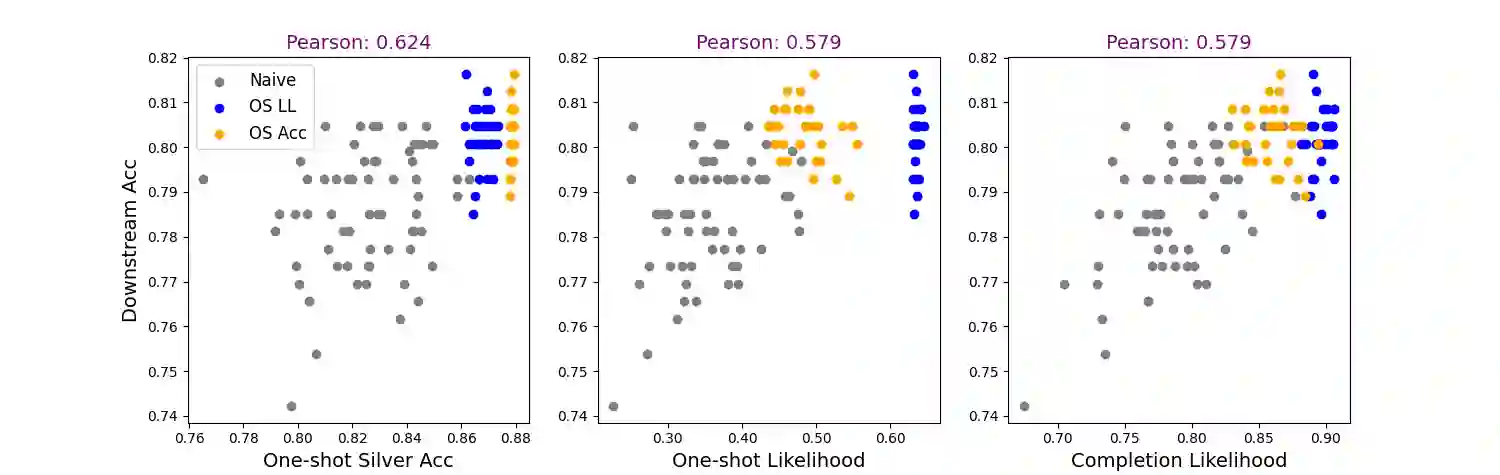
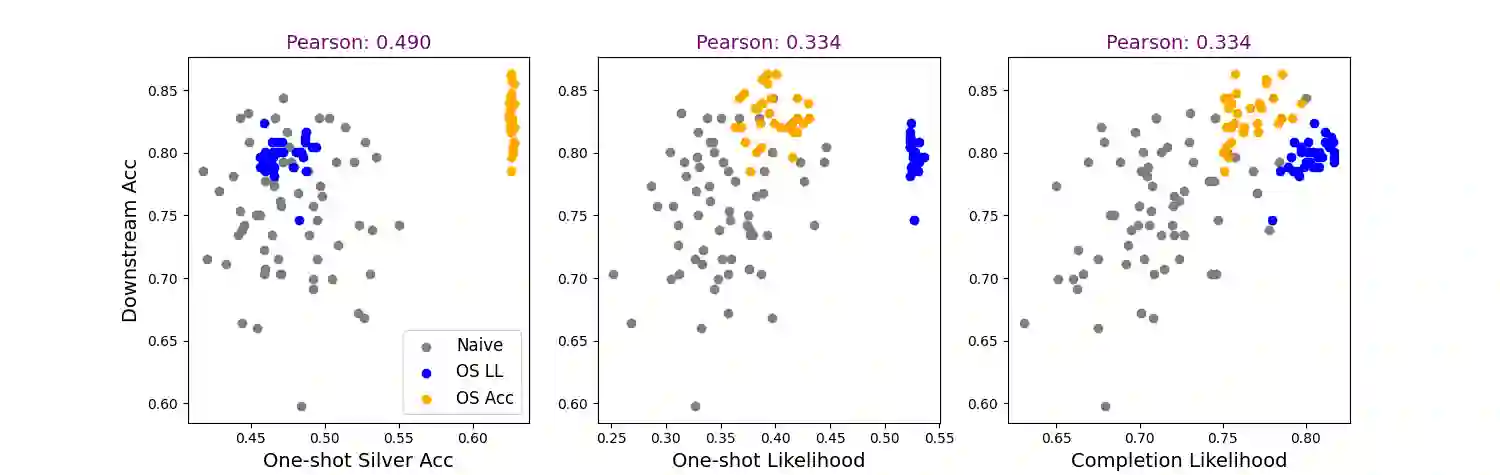
Recent work has addressed textual reasoning tasks by prompting large language models with explanations via the chain-of-thought paradigm. However, subtly different explanations can yield widely varying downstream task accuracy, so explanations that have not been "tuned" for a task, such as off-the-shelf explanations written by nonexperts, may lead to mediocre performance. This paper tackles the problem of how to optimize explanation-infused prompts in a black-box fashion. We first generate sets of candidate explanations for each example in the prompt using a leave-one-out scheme. We then use a two-stage framework where we first evaluate explanations for each in-context example in isolation according to proxy metrics. Finally, we search over sets of explanations to find a set which yields high performance against a silver-labeled development set, drawing inspiration from recent work on bootstrapping language models on unlabeled data. Across four textual reasoning tasks spanning question answering, mathematical reasoning, and natural language inference, results show that our proxy metrics correlate with ground truth accuracy and our overall method can effectively improve prompts over crowdworker annotations and naive search strategies.
翻译:近期研究通过链式思维范式,利用解释引导大型语言模型处理文本推理任务。然而,细微差异的解释可能导致下游任务准确率出现显著波动,因此未经任务特定"调优"的解释(如非专家编写的现成解释)可能仅能获得平庸的性能。本文旨在解决如何以黑盒方式优化融入解释的提示问题。我们首先采用留一法为提示中的每个示例生成候选解释集,继而构建两阶段框架:先根据代理指标独立评估每个上下文示例对应的解释,随后受近期关于利用无标签数据引导语言模型自举研究的启发,在候选解释集合中搜索能对银标开发集产生高绩效的配置。在涵盖问答、数学推理和自然语言推理的四项文本推理任务中,实验结果表明我们的代理指标与真实准确率具有相关性,且整体方法相较众包标注和朴素搜索策略能有效提升提示质量。