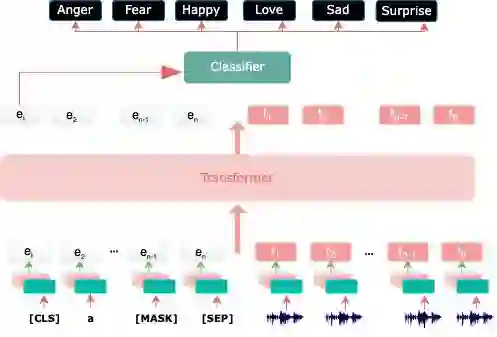
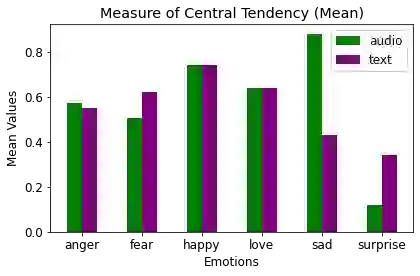
Technological advancement and its omnipresent connection have pushed humans past the boundaries and limitations of a computer screen, physical state, or geographical location. It has provided a depth of avenues that facilitate human-computer interaction that was once inconceivable such as audio and body language detection. Given the complex modularities of emotions, it becomes vital to study human-computer interaction, as it is the commencement of a thorough understanding of the emotional state of users and, in the context of social networks, the producers of multimodal information. This study first acknowledges the accuracy of classification found within multimodal emotion detection systems compared to unimodal solutions. Second, it explores the characterization of multimedia content produced based on their emotions and the coherence of emotion in different modalities by utilizing deep learning models to classify emotion across different modalities.
翻译:技术进步及其无处不在的连通性,已推动人类超越了计算机屏幕、物理状态或地理位置的界限与限制。它提供了丰富的途径来促进人机交互,例如音频与肢体语言检测——这在过去是难以想象的。鉴于情感复杂多变的模块特性,研究人机交互变得至关重要,因为这正是深入理解用户情感状态的开端,在社会网络语境下,也是理解多模态信息生产者的情感状态的开端。本研究首先证实了多模态情感检测系统相较于单模态方案在分类准确性方面的优势。其次,它探究了基于情感所生产的多媒体内容的表征特性,以及不同模态间情感的一致性,具体通过利用深度学习模型对不同模态的情感进行分类来实现。