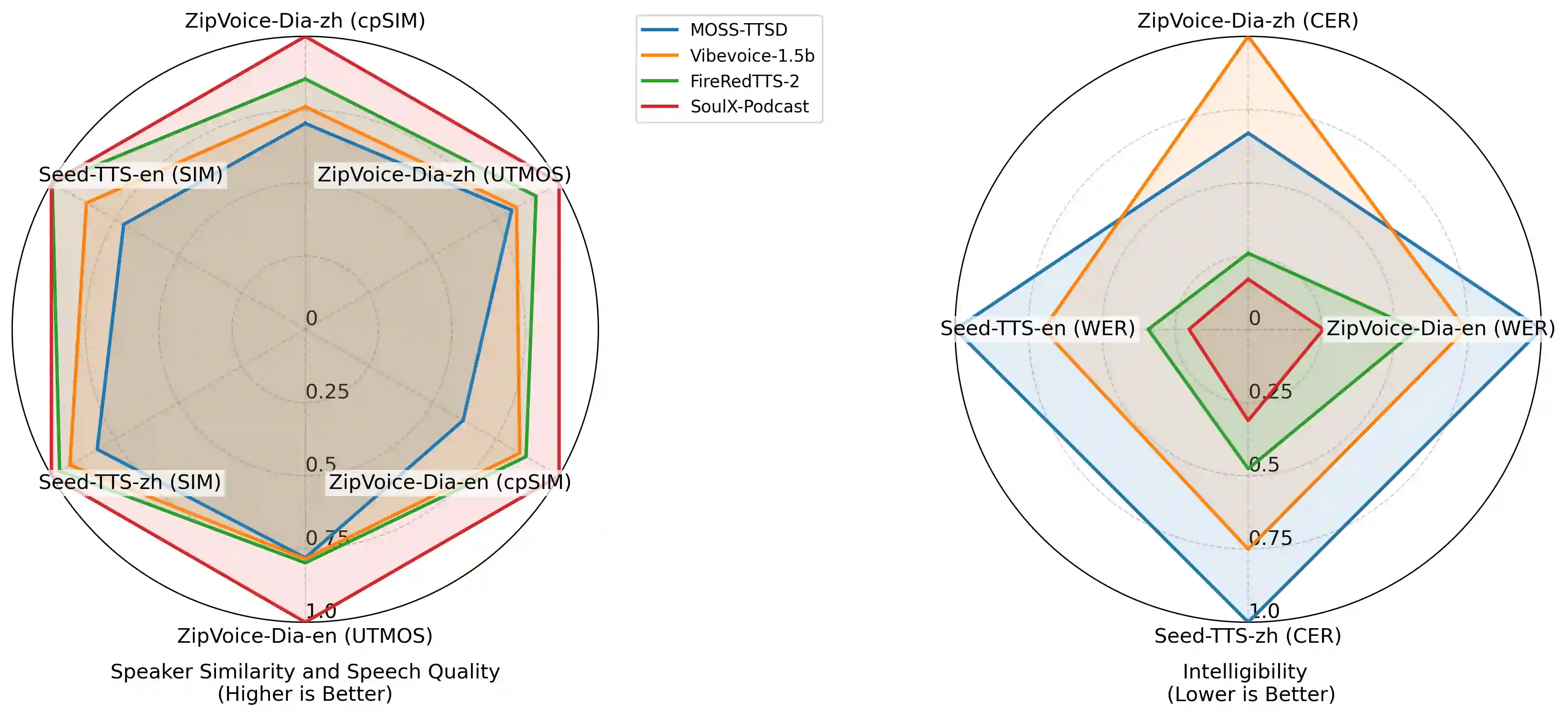
Recent advances in text-to-speech (TTS) synthesis have significantly improved speech expressiveness and naturalness. However, most existing systems are tailored for single-speaker synthesis and fall short in generating coherent multi-speaker conversational speech. This technical report presents SoulX-Podcast, a system designed for podcast-style multi-turn, multi-speaker dialogic speech generation, while also achieving state-of-the-art performance in conventional TTS tasks. To meet the higher naturalness demands of multi-turn spoken dialogue, SoulX-Podcast integrates a range of paralinguistic controls and supports both Mandarin and English, as well as several Chinese dialects, including Sichuanese, Henanese, and Cantonese, enabling more personalized podcast-style speech generation. Experimental results demonstrate that SoulX-Podcast can continuously produce over 90 minutes of conversation with stable speaker timbre and smooth speaker transitions. Moreover, speakers exhibit contextually adaptive prosody, reflecting natural rhythm and intonation changes as dialogues progress. Across multiple evaluation metrics, SoulX-Podcast achieves state-of-the-art performance in both monologue TTS and multi-turn conversational speech synthesis.
翻译:近年来,文本到语音合成技术取得了显著进展,显著提升了语音的表现力与自然度。然而,现有系统大多针对单说话人合成设计,在生成连贯的多说话人对话语音方面仍存在不足。本技术报告介绍了SoulX-Podcast系统,该系统专为播客风格的多轮次、多说话人对话语音生成而设计,同时在传统TTS任务中实现了最先进的性能。为满足多轮口语对话对更高自然度的要求,SoulX-Podcast集成了多种副语言控制功能,支持普通话、英语以及多种中国方言(包括四川话、河南话和粤语),从而实现更具个性化的播客风格语音生成。实验结果表明,SoulX-Podcast能够持续生成超过90分钟的对话,保持稳定的说话人音色和平滑的说话人转换。此外,说话人表现出上下文自适应的韵律特征,能够随着对话进程自然反映节奏与语调的变化。在多项评估指标中,SoulX-Podcast在独白TTS与多轮对话语音合成任务中均达到了最先进的性能水平。