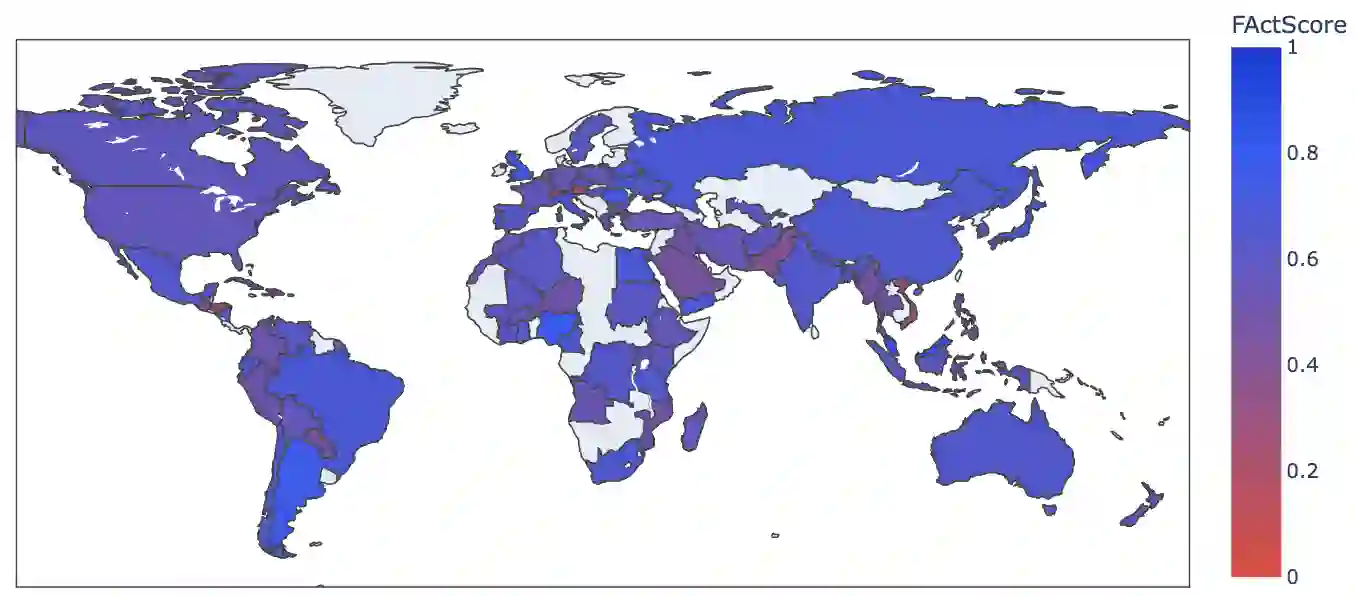
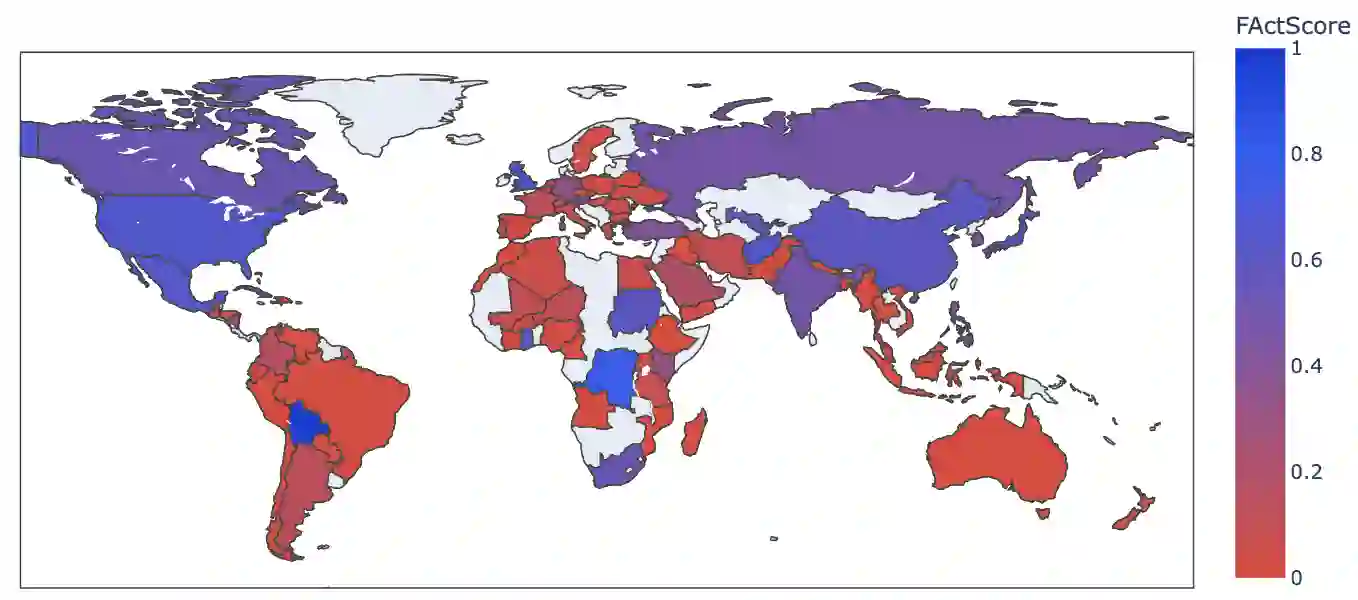
Large Language Models (LLMs) are prone to factuality hallucination, generating text that contradicts established knowledge. While extensive research has addressed this in English, little is known about multilingual LLMs. This paper systematically evaluates multilingual LLMs' factual accuracy across languages and geographic regions. We introduce a novel pipeline for multilingual factuality evaluation, adapting FActScore(Min et al., 2023) for diverse languages. Our analysis across nine languages reveals that English consistently outperforms others in factual accuracy and quantity of generated facts. Furthermore, multilingual models demonstrate a bias towards factual information from Western continents. These findings highlight the need for improved multilingual factuality assessment and underscore geographical biases in LLMs' fact generation.
翻译:大语言模型(LLMs)易产生事实性幻觉,生成与已有知识相矛盾的文本。尽管已有大量研究针对英语这一问题展开探讨,但关于多语言大语言模型的研究尚不充分。本文系统评估了多语言大语言模型在不同语言和地理区域上的事实准确性。我们提出了一种全新的多语言事实性评估流程,将FActScore(Min 等人,2023)适配至多种语言。针对九种语言的分析表明,英语在事实准确性和生成事实的数量上始终优于其他语言。此外,多语言模型表现出对西方国家事实信息的偏好。这些发现凸显了改进多语言事实性评估方法的必要性,并揭示了LLMs事实生成中的地理偏差。