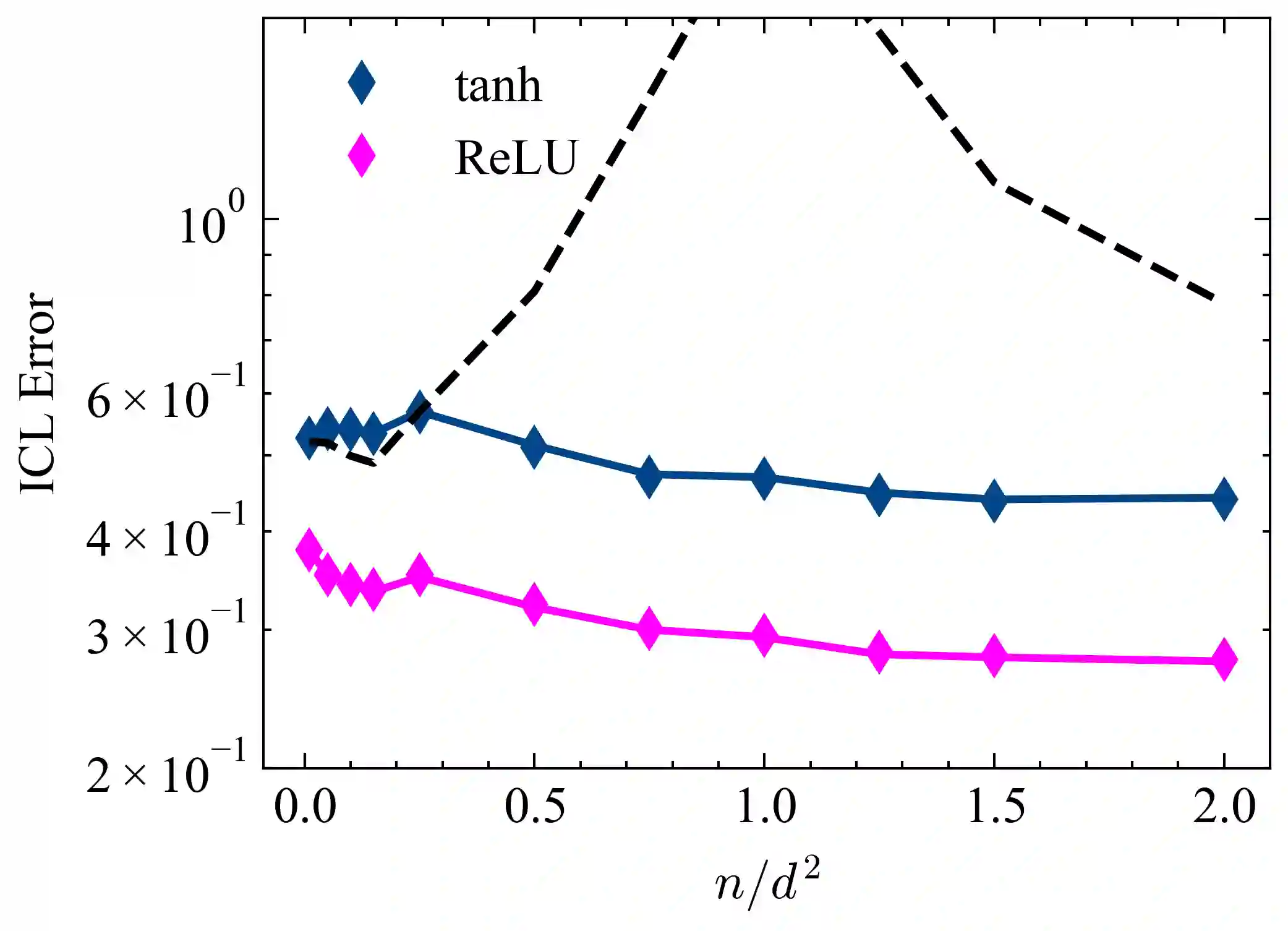
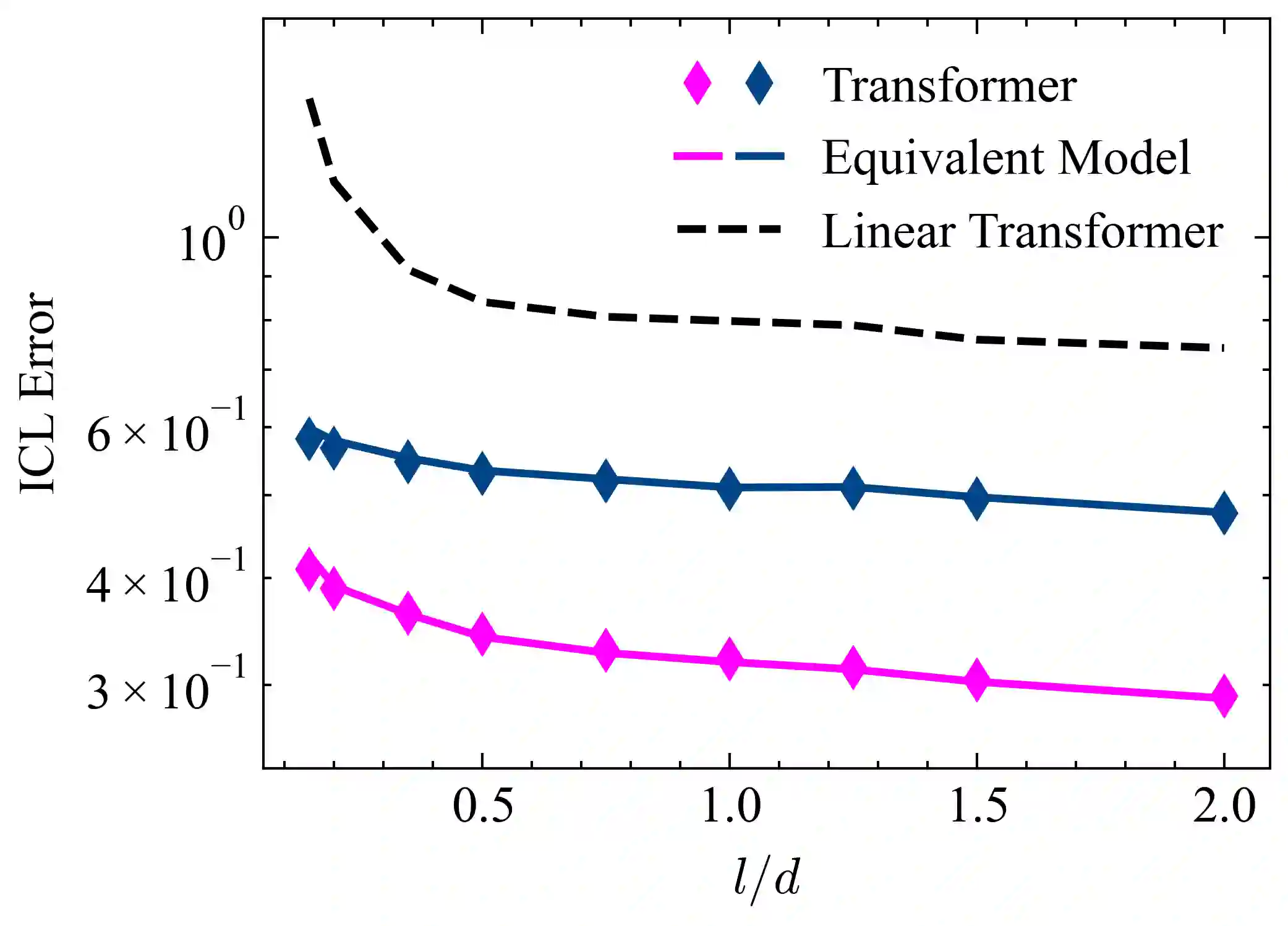
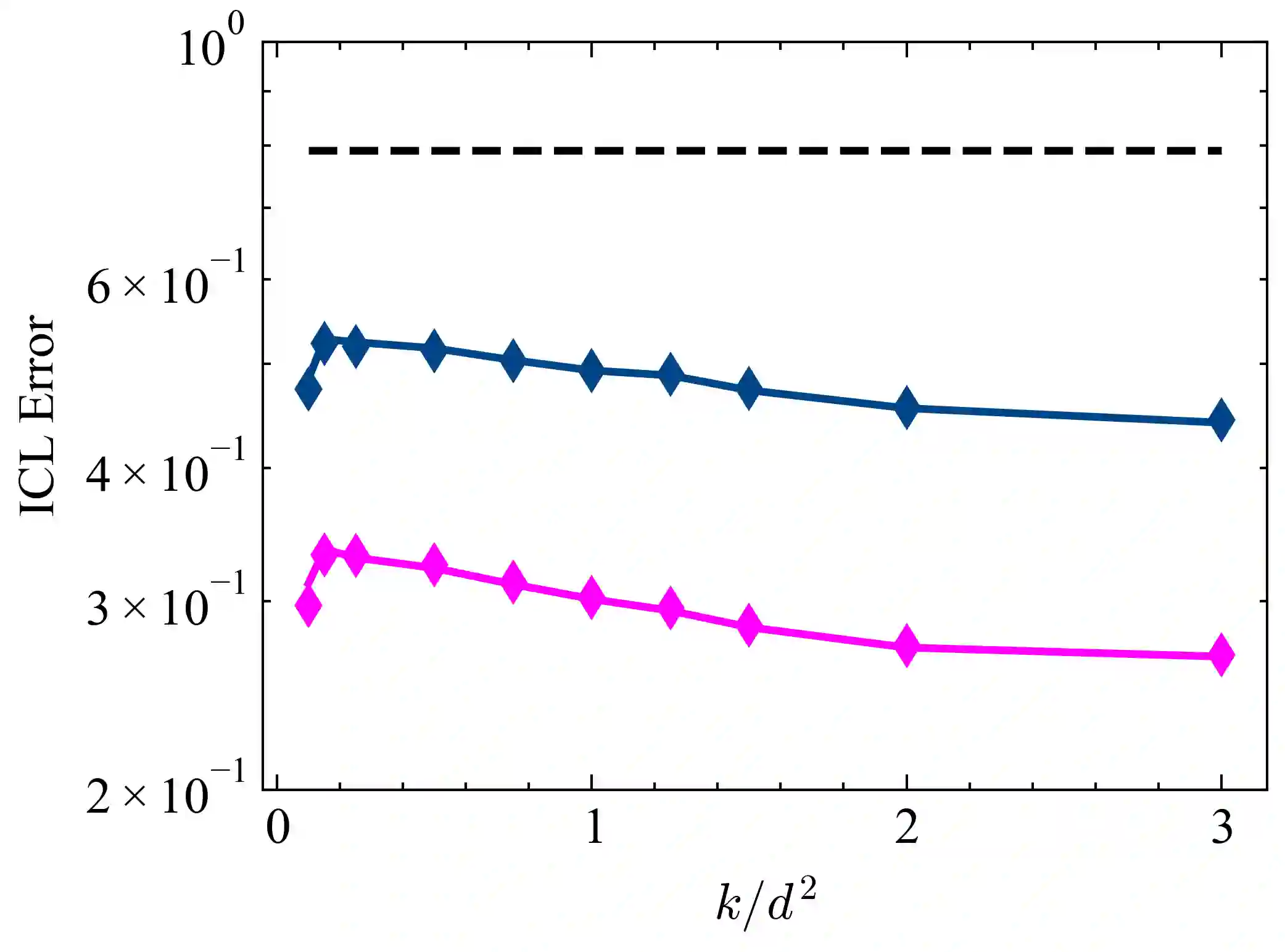
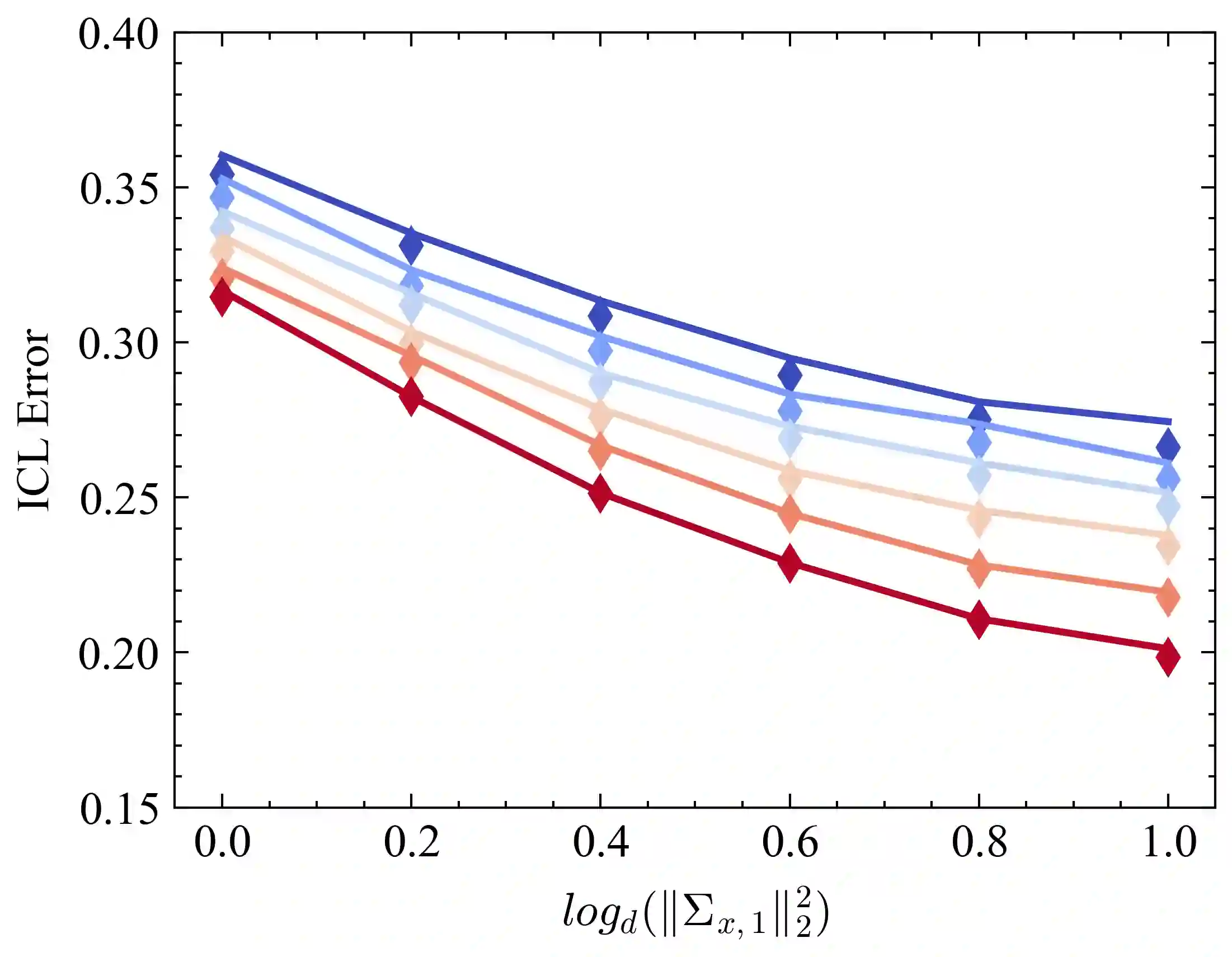
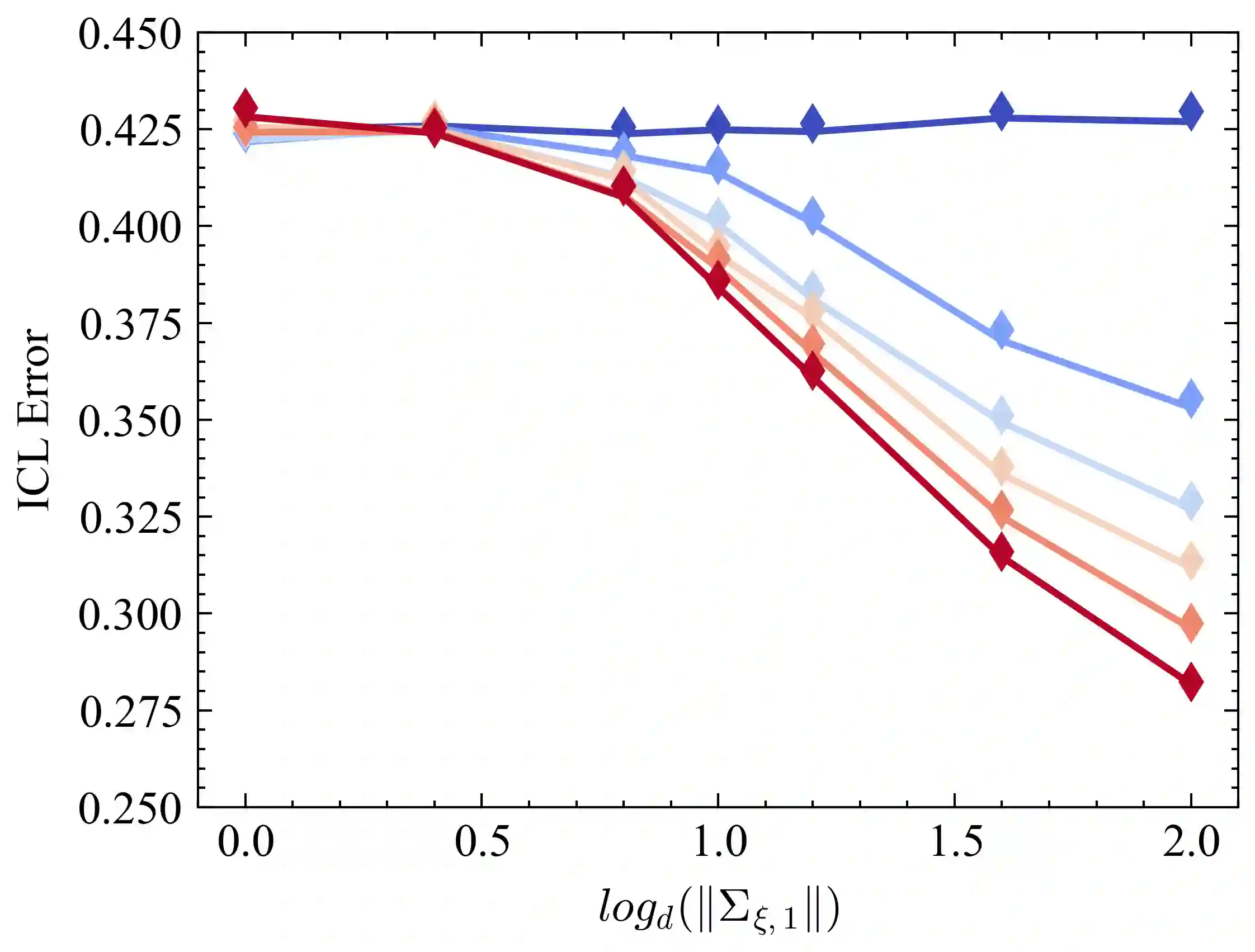
Pretrained Transformers demonstrate remarkable in-context learning (ICL) capabilities, enabling them to adapt to new tasks from demonstrations without parameter updates. However, theoretical studies often rely on simplified architectures (e.g., omitting MLPs), data models (e.g., linear regression with isotropic inputs), and single-source training, limiting their relevance to realistic settings. In this work, we study ICL in pretrained Transformers with nonlinear MLP heads on nonlinear tasks drawn from multiple data sources with heterogeneous input, task, and noise distributions. We analyze a model where the MLP comprises two layers, with the first layer trained via a single gradient step and the second layer fully optimized. Under high-dimensional asymptotics, we prove that such models are equivalent in ICL error to structured polynomial predictors, leveraging results from the theory of Gaussian universality and orthogonal polynomials. This equivalence reveals that nonlinear MLPs meaningfully enhance ICL performance, particularly on nonlinear tasks, compared to linear baselines. It also enables a precise analysis of data mixing effects: we identify key properties of high-quality data sources (low noise, structured covariances) and show that feature learning emerges only when the task covariance exhibits sufficient structure. These results are validated empirically across various activation functions, model sizes, and data distributions. Finally, we experiment with a real-world scenario involving multilingual sentiment analysis where each language is treated as a different source. Our experimental results for this case exemplify how our findings extend to real-world cases. Overall, our work advances the theoretical foundations of ICL in Transformers and provides actionable insight into the role of architecture and data in ICL.
翻译:预训练的Transformer展现出卓越的上下文学习能力,使其能够仅通过演示适应新任务而无需参数更新。然而,理论研究通常依赖于简化的架构(例如省略MLP)、数据模型(例如各向同性输入的线性回归)和单源训练,这限制了其与现实场景的相关性。在本工作中,我们研究了具有非线性MLP头的预训练Transformer在非线性任务上的上下文学习,这些任务来自具有异质输入、任务和噪声分布的多个数据源。我们分析了一个模型,其中MLP包含两层:第一层通过单步梯度训练,第二层完全优化。在高维渐近条件下,我们证明此类模型在上下文学习误差上等价于结构化多项式预测器,这利用了高斯普适性和正交多项式理论的结果。该等价性揭示了与线性基线相比,非线性MLP显著提升了上下文学习性能,尤其是在非线性任务上。它还使得对数据混合效应的精确分析成为可能:我们识别了高质量数据源的关键特性(低噪声、结构化协方差),并表明仅当任务协方差展现出足够结构时,特征学习才会出现。这些结果在各种激活函数、模型大小和数据分布上得到了实证验证。最后,我们在涉及多语言情感分析的真实场景中进行了实验,其中每种语言被视为不同的数据源。该案例的实验结果例证了我们的发现如何推广到现实场景。总体而言,我们的工作推进了Transformer上下文学习的理论基础,并为架构和数据在上下文学习中的作用提供了可操作的见解。