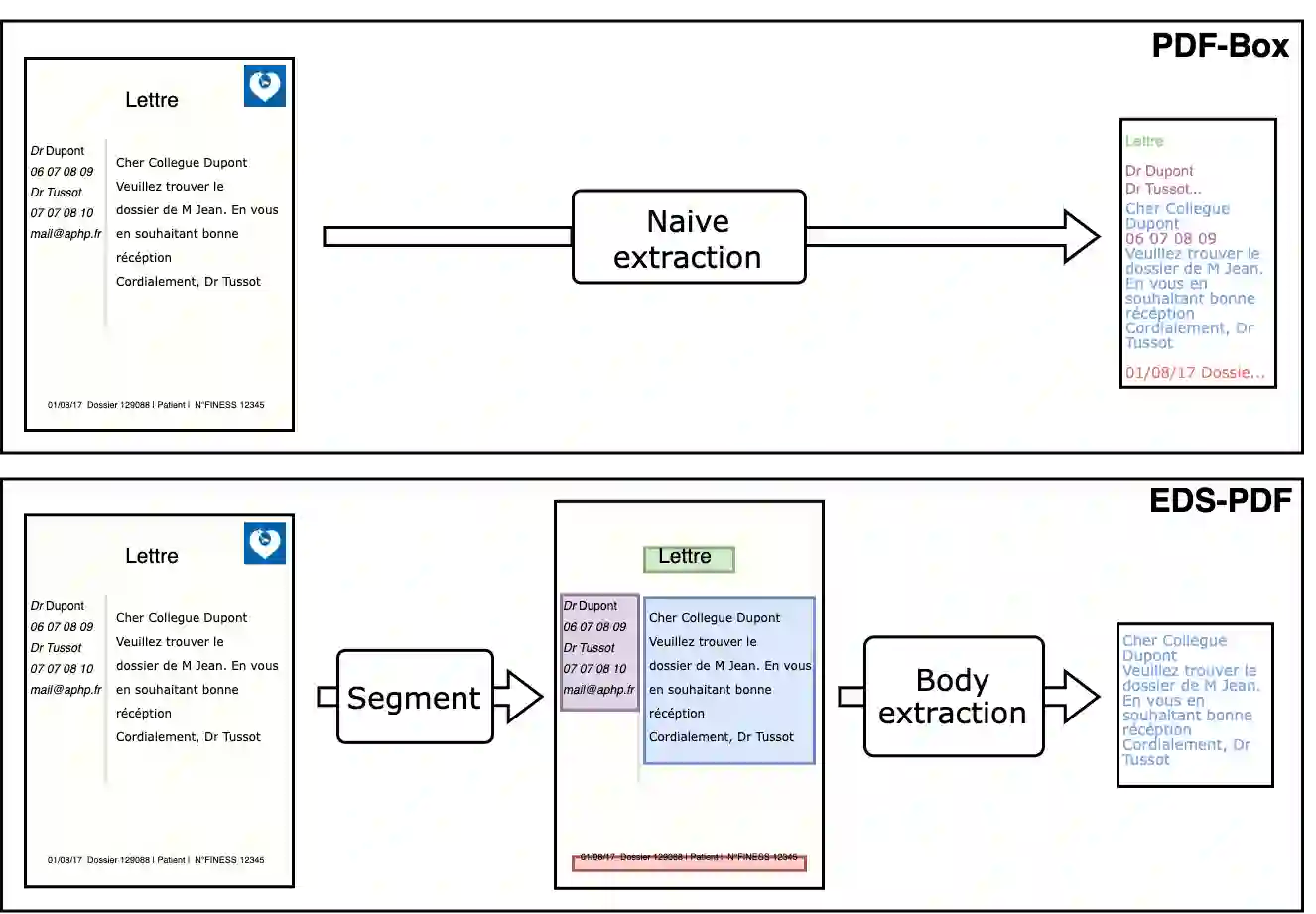
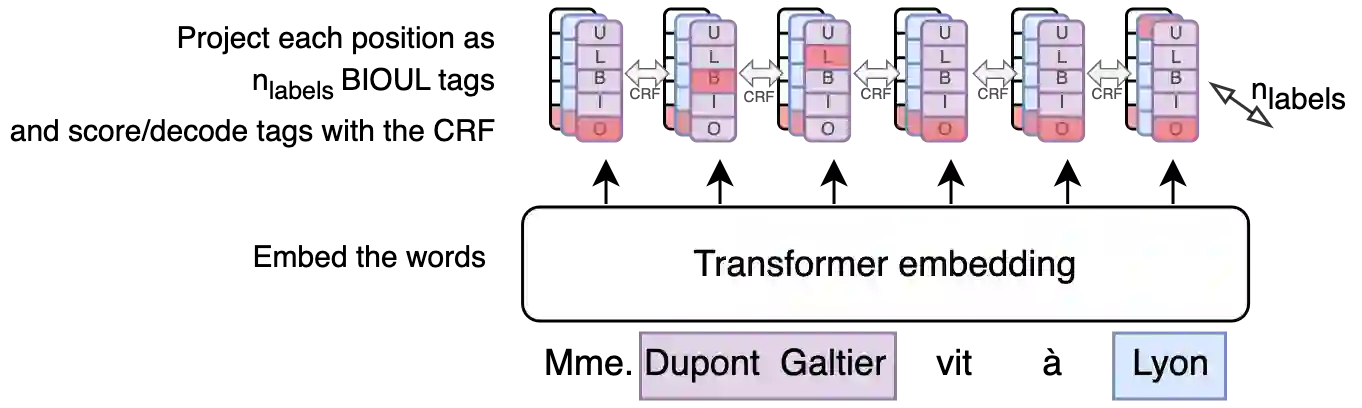
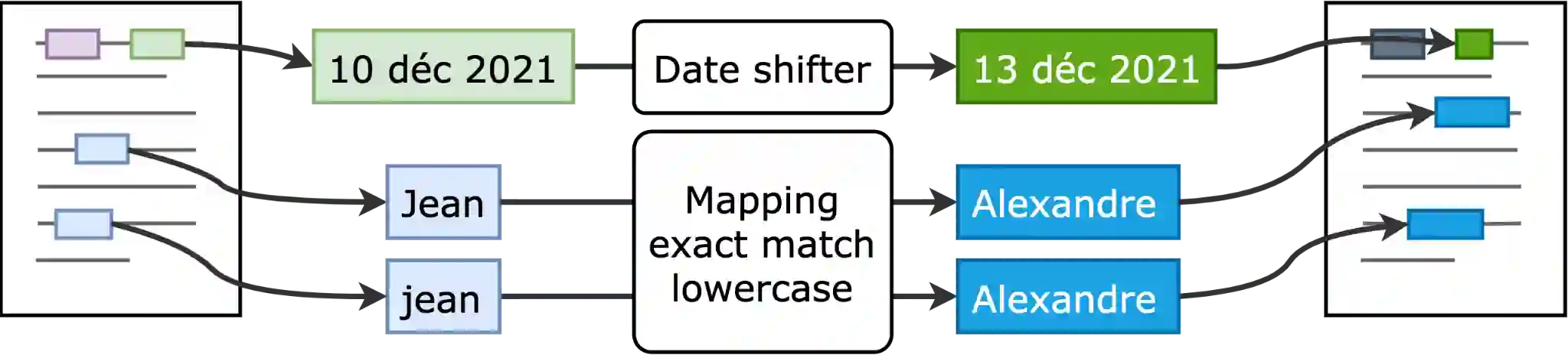
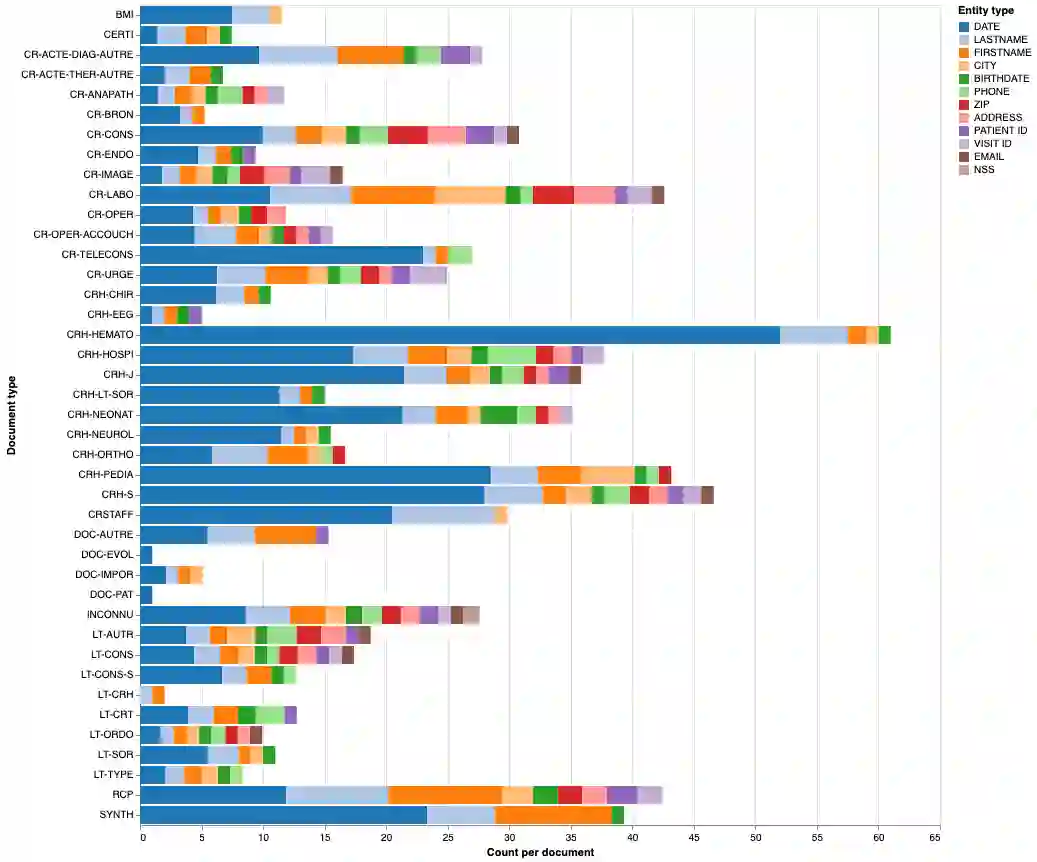
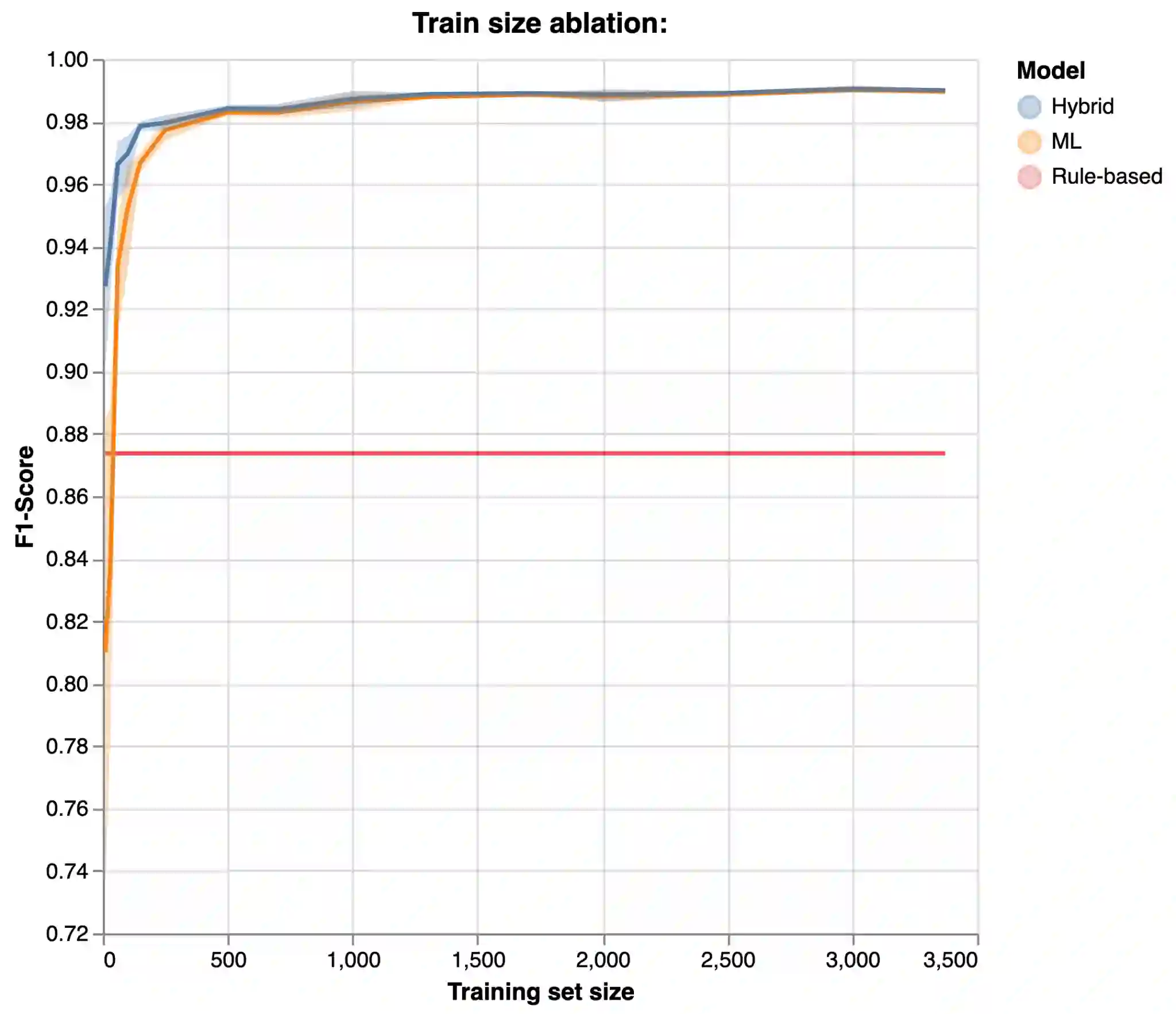
The objective of this study is to address the critical issue of de-identification of clinical reports in order to allow access to data for research purposes, while ensuring patient privacy. The study highlights the difficulties faced in sharing tools and resources in this domain and presents the experience of the Greater Paris University Hospitals (AP-HP) in implementing a systematic pseudonymization of text documents from its Clinical Data Warehouse. We annotated a corpus of clinical documents according to 12 types of identifying entities, and built a hybrid system, merging the results of a deep learning model as well as manual rules. Our results show an overall performance of 0.99 of F1-score. We discuss implementation choices and present experiments to better understand the effort involved in such a task, including dataset size, document types, language models, or rule addition. We share guidelines and code under a 3-Clause BSD license.
翻译:本研究旨在解决临床报告去标识化的关键问题,以便在研究目的下实现数据访问,同时保障患者隐私。研究指出了该领域工具和资源共享所面临的挑战,并介绍了巴黎公立医院集团(AP-HP)在其临床数据仓库中系统实施文本文档假名化的实践经验。我们根据12类标识实体对临床文档语料库进行了标注,并构建了一个融合深度学习模型结果与人工规则的混合系统。实验结果显示,该系统总体F1分数达到0.99。我们探讨了实施过程中的选择,并开展实验以深入理解此类任务所需的工作量,包括数据集规模、文档类型、语言模型选择及规则添加等方面的影响。相关指导原则和代码已依据3-Clause BSD许可协议进行共享。