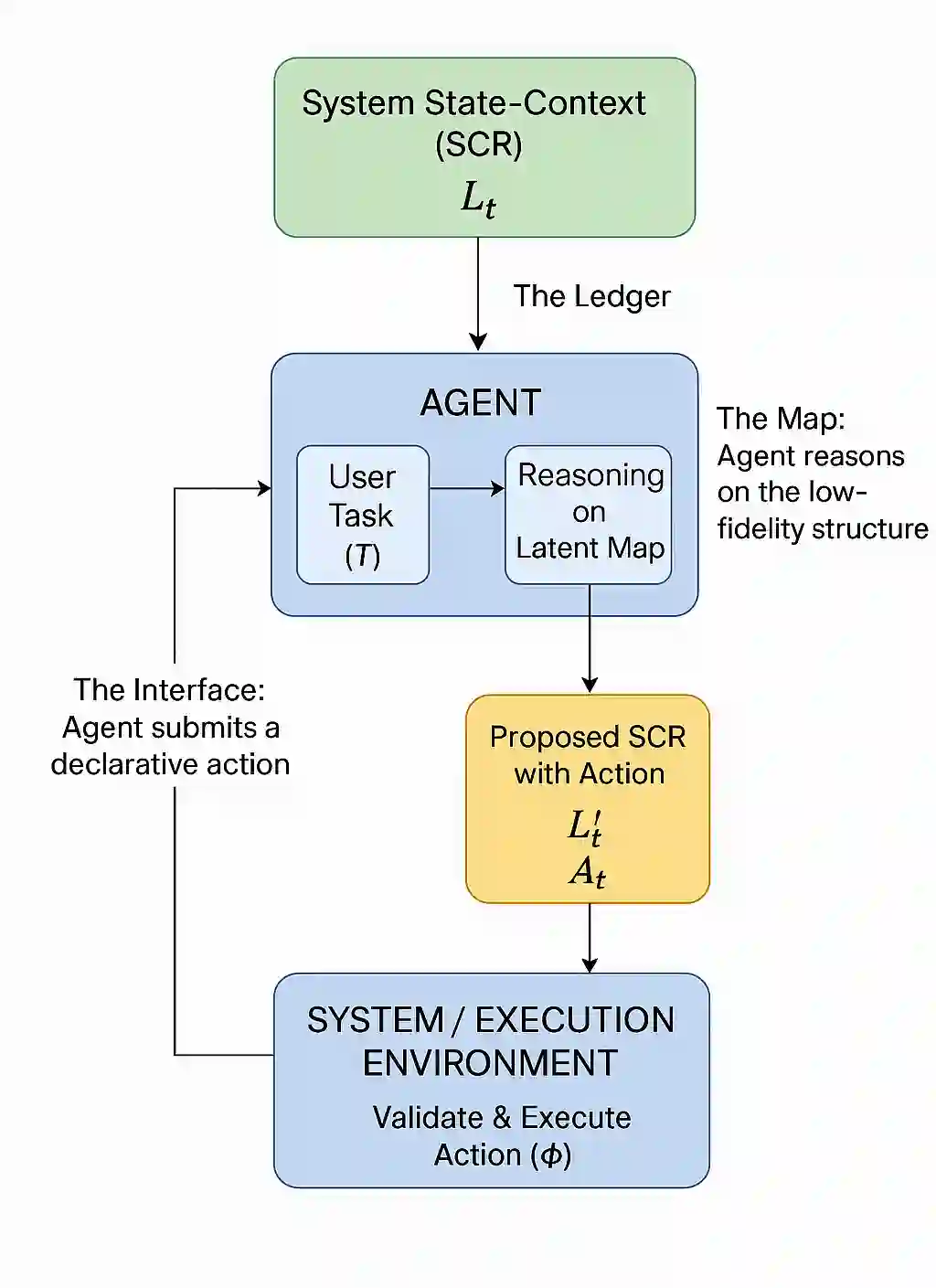
Large Language Models (LLMs) are increasingly deployed as autonomous agents, yet their practical utility is fundamentally constrained by a limited context window and state desynchronization resulting from the LLMs' stateless nature and inefficient context management. These limitations lead to unreliable output, unpredictable behavior, and inefficient resource usage, particularly when interacting with large, structured, and sensitive knowledge systems such as codebases and documents. To address these challenges, we introduce the Gatekeeper Protocol, a novel, domain-agnostic framework that governs agent-system interactions. Our protocol mandates that the agent first operate and reason on a minimalist, low-fidelity "latent state" representation of the system to strategically request high-fidelity context on demand. All interactions are mediated through a unified JSON format that serves as a declarative, state-synchronized protocol, ensuring the agent's model of the system remains verifiably grounded in the system's reality. We demonstrate the efficacy of this protocol with Sage, a reference implementation of the Gatekeeper Protocol for software development. Our results show that this approach significantly increases agent reliability, improves computational efficiency by minimizing token consumption, and enables scalable interaction with complex systems, creating a foundational methodology for building more robust, predictable, and grounded AI agents for any structured knowledge domain.
翻译:大型语言模型(LLM)正日益被部署为自主智能体,但其实际效用从根本上受限于有限的上下文窗口以及由LLM的无状态特性和低效上下文管理导致的状态失同步问题。这些限制会导致不可靠的输出、不可预测的行为以及低效的资源使用,尤其是在与代码库和文档等大型、结构化且敏感的知识系统交互时。为应对这些挑战,我们提出了门卫协议(Gatekeeper Protocol),这是一个新颖的、领域无关的框架,用于管理智能体与系统之间的交互。我们的协议要求智能体首先在一个极简的、低保真度的系统“潜在状态”表示上进行操作和推理,从而按需策略性地请求高保真度的上下文。所有交互均通过统一的JSON格式进行中介,该格式作为一种声明式的、状态同步的协议,确保智能体对系统的模型能够可验证地基于系统现实。我们通过Sage(门卫协议在软件开发领域的一个参考实现)展示了该协议的有效性。我们的结果表明,该方法显著提高了智能体的可靠性,通过最小化令牌消耗提升了计算效率,并实现了与复杂系统的可扩展交互,为在任何结构化知识领域构建更稳健、可预测且基于现实的AI智能体奠定了一种基础性方法论。