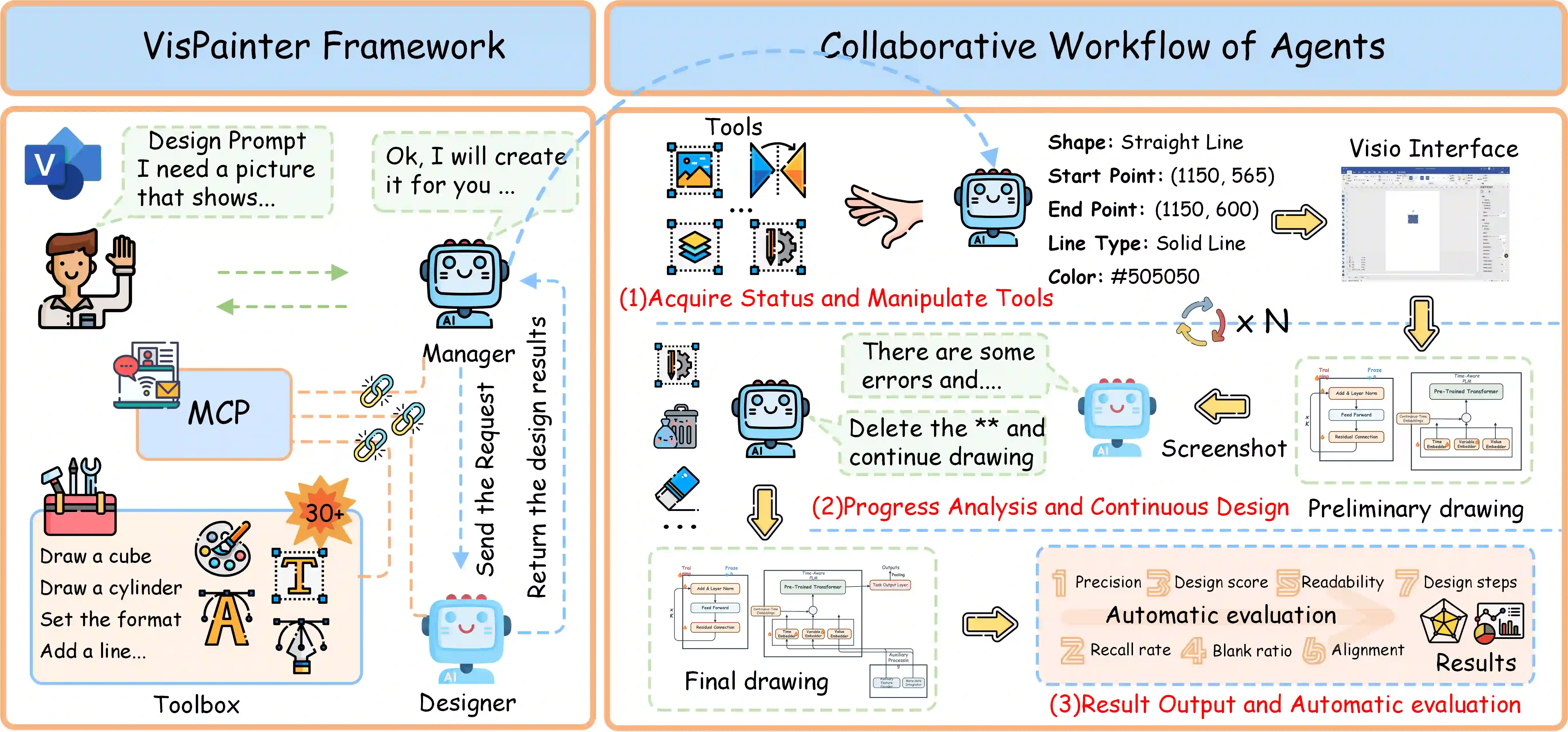
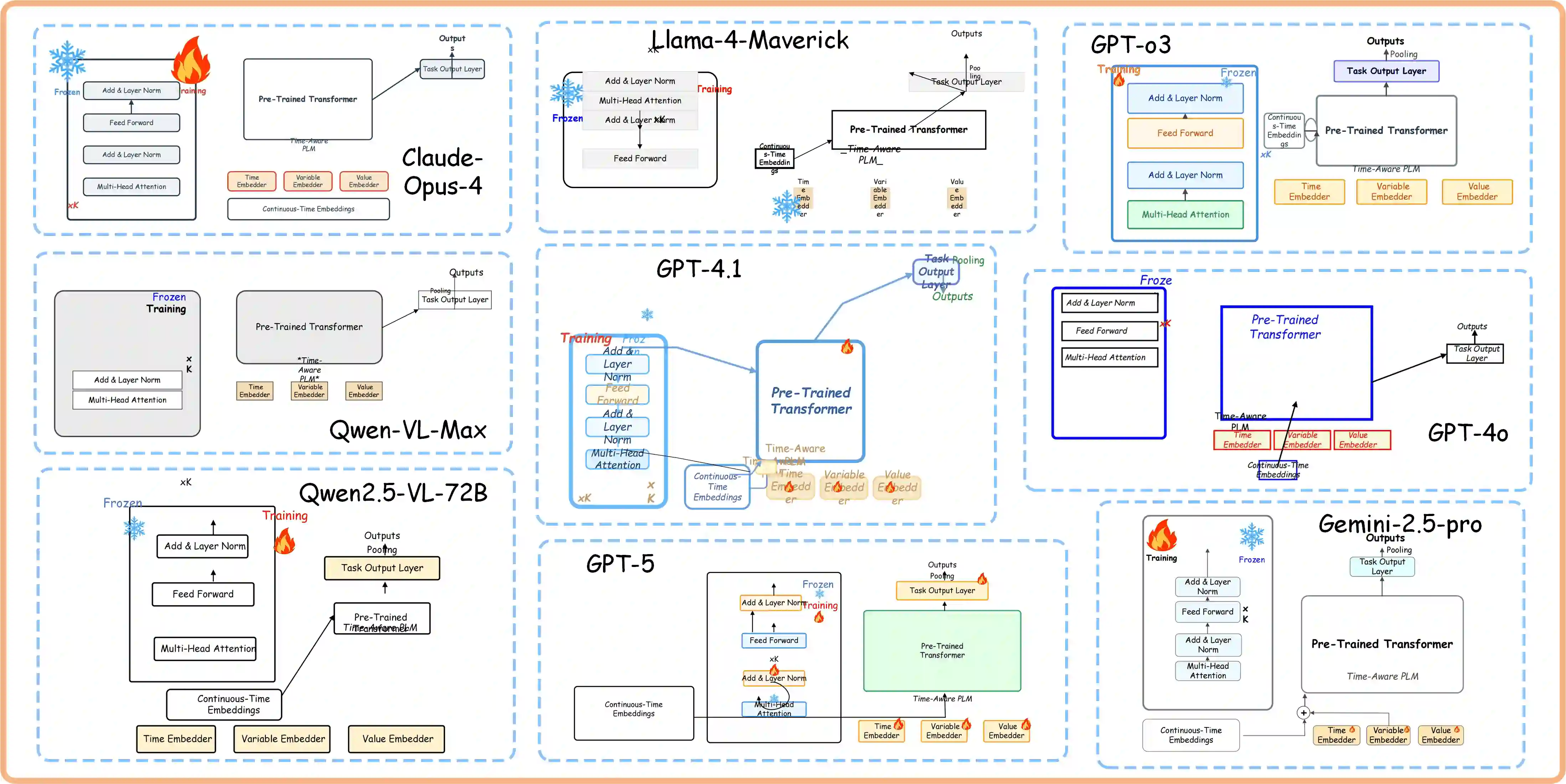
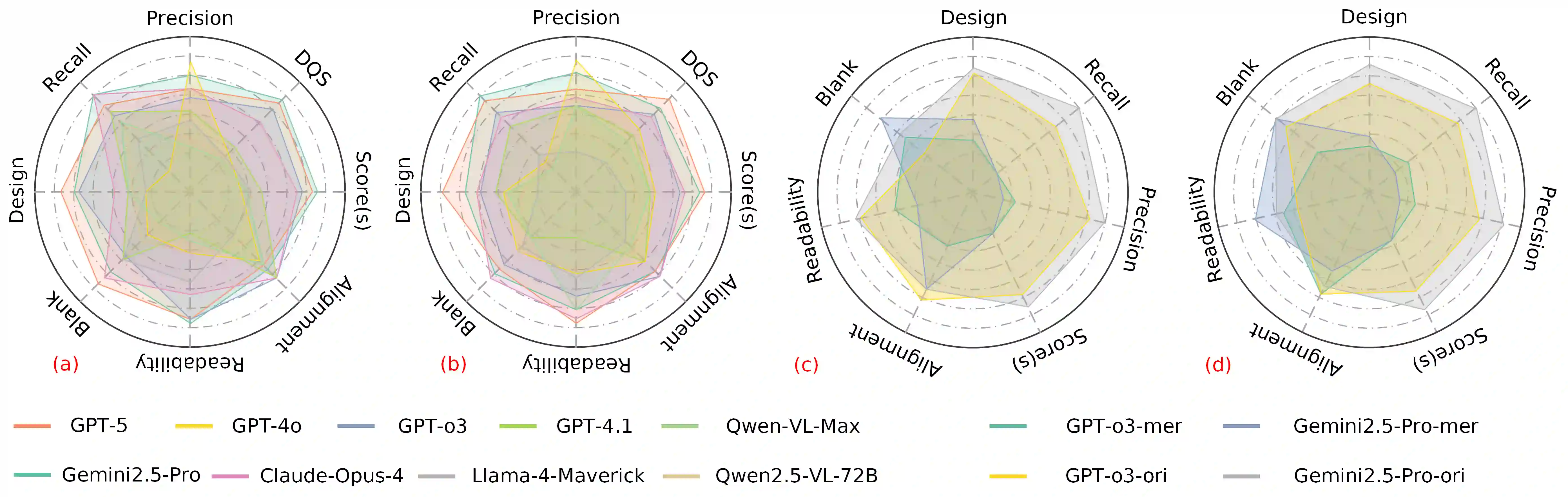
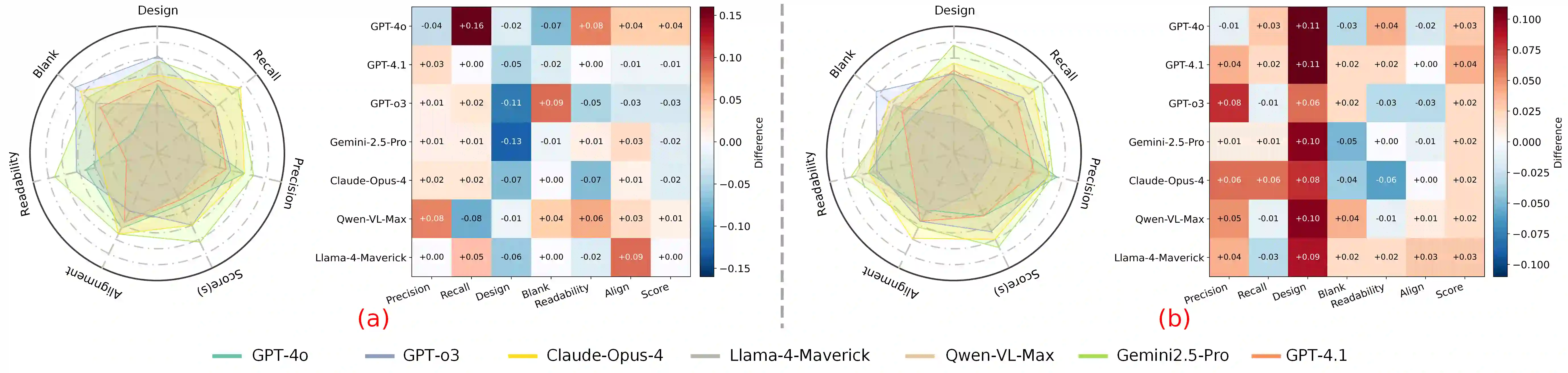
Scientific illustrations demand both high information density and post-editability. However, current generative models have two major limitations: Frist, image generation models output rasterized images lacking semantic structure, making it impossible to access, edit, or rearrange independent visual components in the images. Second, code-based generation methods (TikZ or SVG), although providing element-level control, force users into the cumbersome cycle of "writing-compiling-reviewing" and lack the intuitiveness of manipulation. Neither of these two approaches can well meet the needs for efficiency, intuitiveness, and iterative modification in scientific creation. To bridge this gap, we introduce VisPainter, a multi-agent framework for scientific illustration built upon the model context protocol. VisPainter orchestrates three specialized modules-a Manager, a Designer, and a Toolbox-to collaboratively produce diagrams compatible with standard vector graphics software. This modular, role-based design allows each element to be explicitly represented and manipulated, enabling true element-level control and any element can be added and modified later. To systematically evaluate the quality of scientific illustrations, we introduce VisBench, a benchmark with seven-dimensional evaluation metrics. It assesses high-information-density scientific illustrations from four aspects: content, layout, visual perception, and interaction cost. To this end, we conducted extensive ablation experiments to verify the rationality of our architecture and the reliability of our evaluation methods. Finally, we evaluated various vision-language models, presenting fair and credible model rankings along with detailed comparisons of their respective capabilities. Additionally, we isolated and quantified the impacts of role division, step control,and description on the quality of illustrations.
翻译:科学插图要求同时具备高信息密度和后期可编辑性。然而,当前生成模型存在两大局限:首先,图像生成模型输出的是缺乏语义结构的栅格化图像,使得无法访问、编辑或重新排列图像中的独立视觉组件。其次,基于代码的生成方法(如TikZ或SVG)虽能提供元素级控制,却迫使用户陷入“编写-编译-审查”的繁琐循环,且缺乏直观的操作性。这两种方法均无法很好地满足科学创作中对效率、直观性和迭代修改的需求。为弥合这一差距,我们提出了VisPainter,一个基于模型上下文协议构建的科学插图多智能体框架。VisPainter协调三个专用模块——管理器、设计器和工具箱——协同生成与标准矢量图形软件兼容的图表。这种模块化、基于角色的设计使得每个元素都能被显式表示和操作,实现真正的元素级控制,且任何元素均可后续添加和修改。为系统评估科学插图的质量,我们引入了VisBench基准,该基准包含七个维度的评估指标,从内容、布局、视觉感知和交互成本四个方面评估高信息密度的科学插图。为此,我们进行了广泛的消融实验,以验证我们架构的合理性及评估方法的可靠性。最后,我们评估了多种视觉-语言模型,提供了公平可信的模型排名及其各自能力的详细比较。此外,我们分离并量化了角色划分、步骤控制和描述对插图质量的影响。