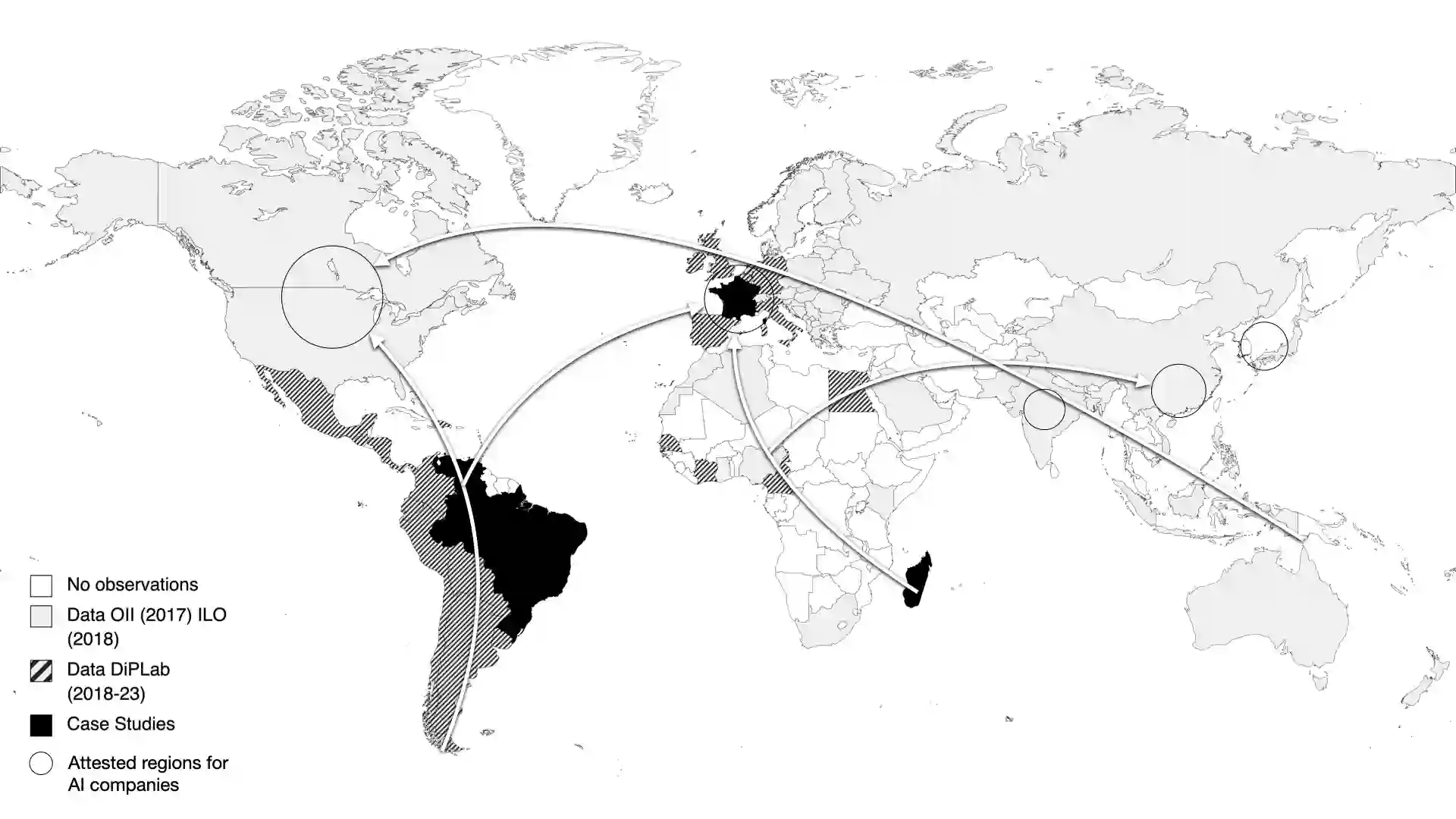
Labor plays a major, albeit largely unrecognized role in the development of artificial intelligence. Machine learning algorithms are predicated on data-intensive processes that rely on humans to execute repetitive and difficult-to-automate, but no less essential, tasks such as labeling images, sorting items in lists, recording voice samples, and transcribing audio files. Online platforms and networks of subcontractors recruit data workers to execute such tasks in the shadow of AI production, often in lower-income countries with long-standing traditions of informality and lessregulated labor markets. This study unveils the resulting complexities by comparing the working conditions and the profiles of data workers in Venezuela, Brazil, Madagascar, and as an example of a richer country, France. By leveraging original data collected over the years 2018-2023 via a mixed-method design, we highlight how the cross-country supply chains that link data workers to core AI production sites are reminiscent of colonial relationships, maintain historical economic dependencies, and generate inequalities that compound with those inherited from the past. The results also point to the importance of less-researched, non-English speaking countries to understand key features of the production of AI solutions at planetary scale.
翻译:劳动力在人工智能发展中扮演着重要但很大程度上未被充分认识的角色。机器学习算法依赖于数据密集型流程,这些流程需要人类执行重复且难以自动化但同样关键的任务,如图像标注、列表项目分类、语音样本录制和音频文件转录。在线平台和分包商网络在人工智能生产的幕后招募数据工作者执行此类任务,这些工作者通常来自低收入国家,这些国家长期存在非正规经济传统且劳动力市场监管较弱。本研究通过比较委内瑞拉、巴西、马达加斯加以及作为富裕国家案例的法国数据工作者的工作条件和人员构成,揭示了由此产生的复杂性。通过利用2018-2023年间采用混合方法设计收集的原始数据,我们强调连接数据工作者与核心人工智能生产地的跨国供应链如何令人联想到殖民关系,维持历史经济依赖,并产生与过去遗留问题相互叠加的不平等。研究结果还指出,关注研究不足的非英语国家对于理解行星尺度人工智能解决方案生产的关键特征具有重要意义。