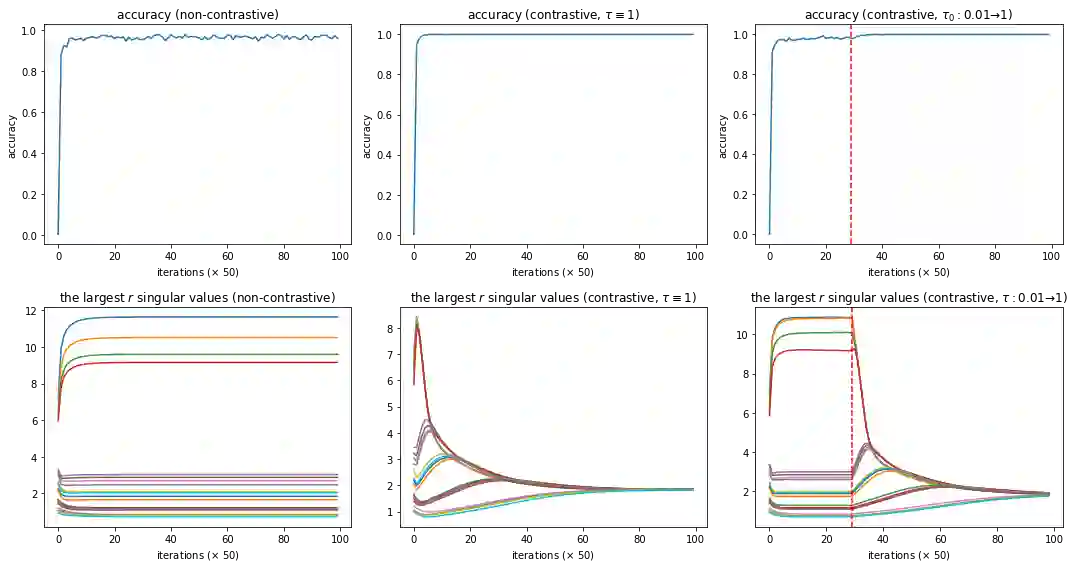
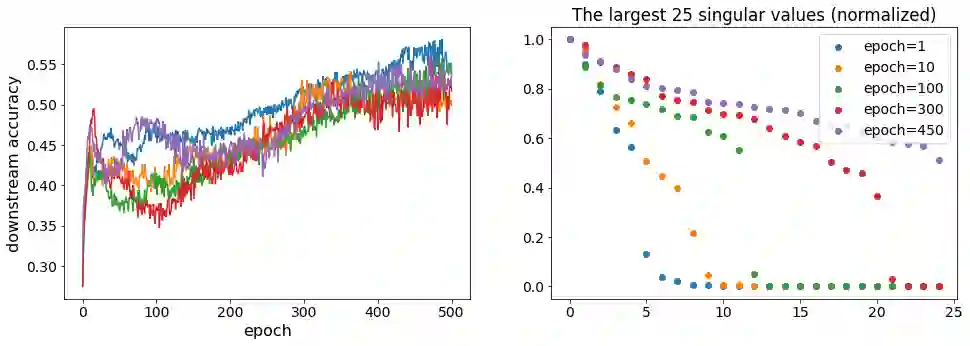
Recently, contrastive learning approaches (e.g., CLIP (Radford et al., 2021)) have received huge success in multimodal learning, where the model tries to minimize the distance between the representations of different views (e.g., image and its caption) of the same data point while keeping the representations of different data points away from each other. However, from a theoretical perspective, it is unclear how contrastive learning can learn the representations from different views efficiently, especially when the data is not isotropic. In this work, we analyze the training dynamics of a simple multimodal contrastive learning model and show that contrastive pairs are important for the model to efficiently balance the learned representations. In particular, we show that the positive pairs will drive the model to align the representations at the cost of increasing the condition number, while the negative pairs will reduce the condition number, keeping the learned representations balanced.
翻译:近期,对比学习方法(如CLIP (Radford et al., 2021))在多模态学习中取得了巨大成功,该模型试图最小化同一数据点不同视图(例如图像及其描述)表征之间的距离,同时保持不同数据点的表征彼此远离。然而,从理论角度来看,对比学习如何高效地从不同视图中学习表征尚不明确,尤其是在数据非各向同性的情况下。在本工作中,我们分析了一个简单多模态对比学习模型的训练动态,并表明对比对对于模型高效平衡所学表征至关重要。具体而言,我们证明正对会驱使模型以增加条件数为代价对齐表征,而负对则会降低条件数,从而保持所学表征的平衡。