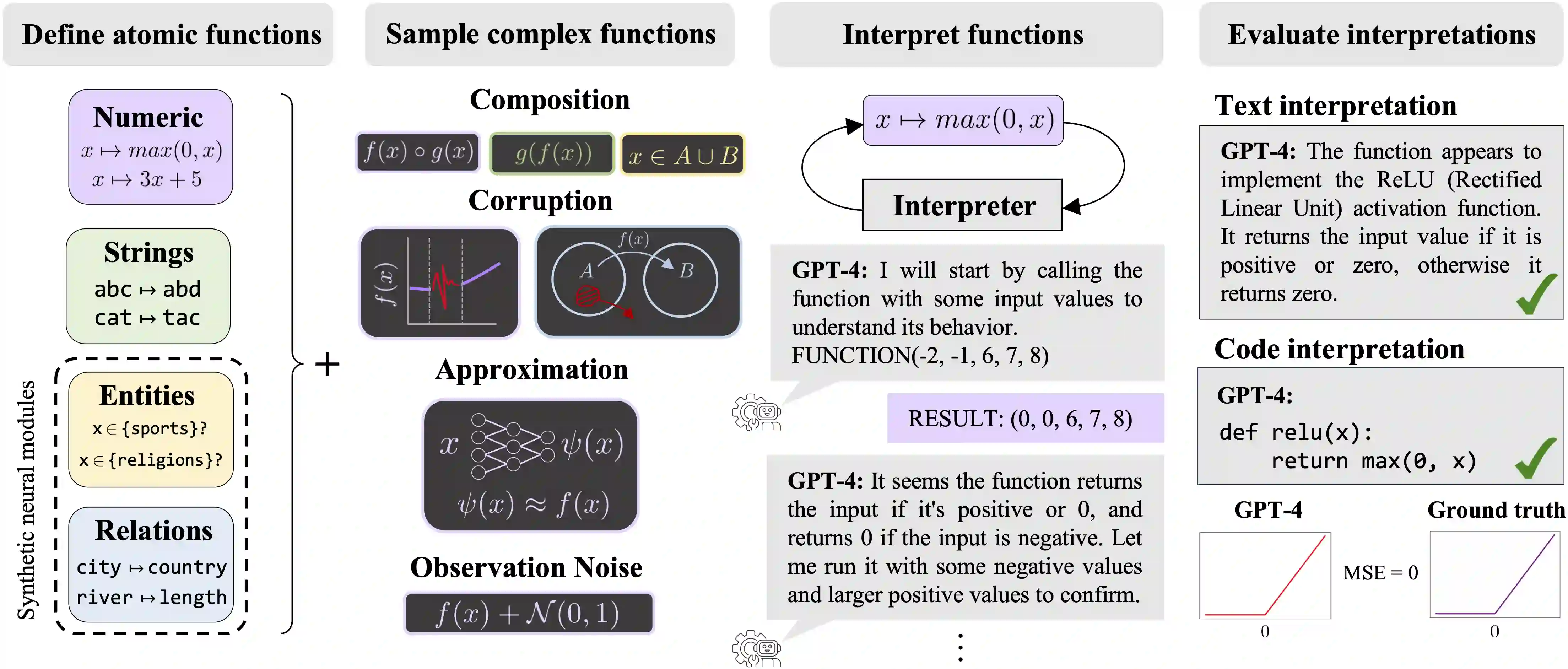
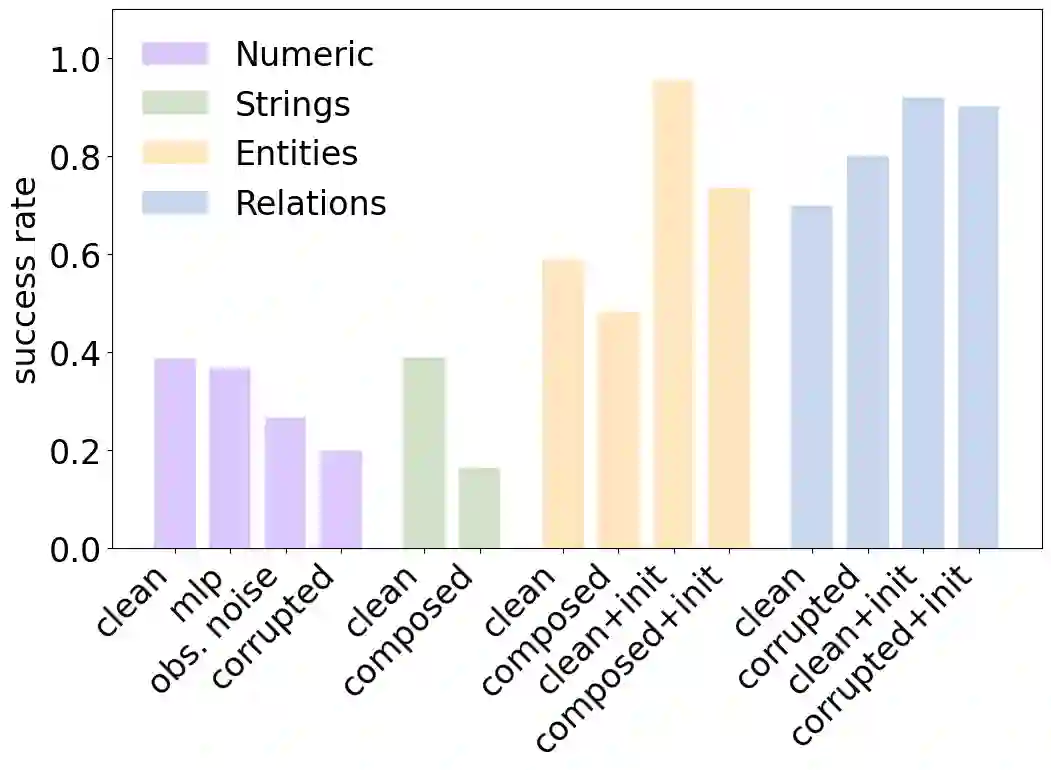
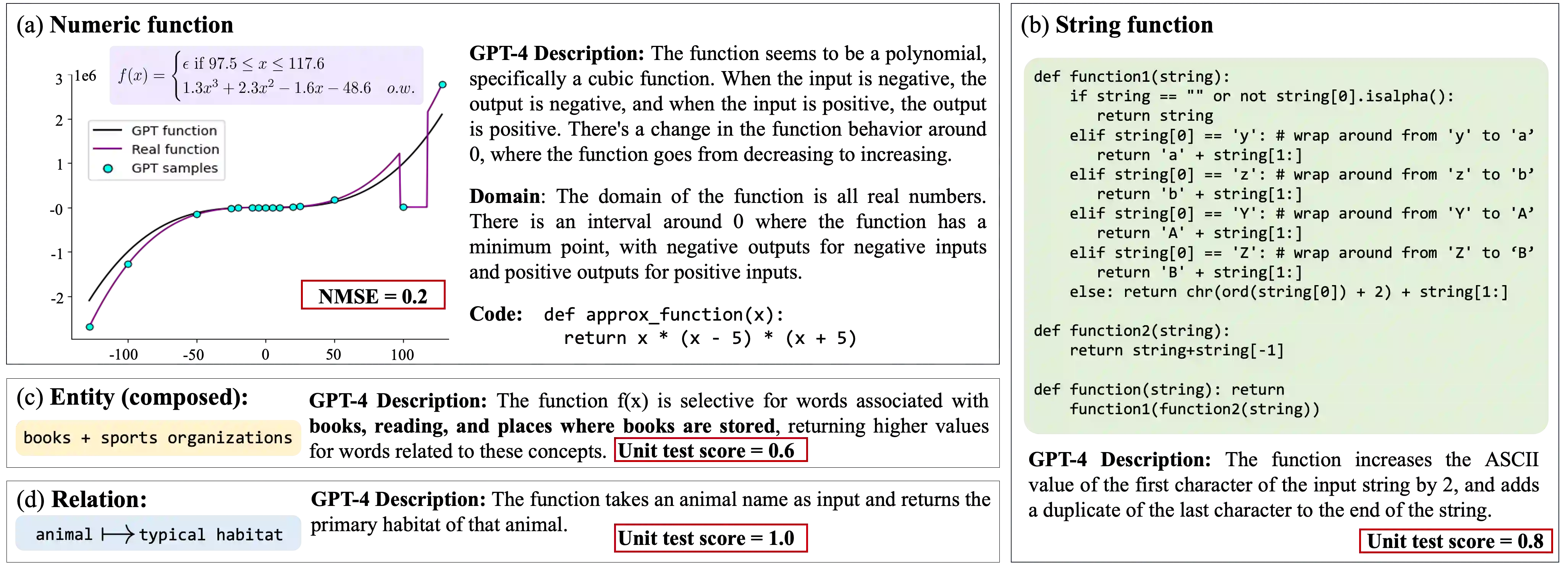
Labeling neural network submodules with human-legible descriptions is useful for many downstream tasks: such descriptions can surface failures, guide interventions, and perhaps even explain important model behaviors. To date, most mechanistic descriptions of trained networks have involved small models, narrowly delimited phenomena, and large amounts of human labor. Labeling all human-interpretable sub-computations in models of increasing size and complexity will almost certainly require tools that can generate and validate descriptions automatically. Recently, techniques that use learned models in-the-loop for labeling have begun to gain traction, but methods for evaluating their efficacy are limited and ad-hoc. How should we validate and compare open-ended labeling tools? This paper introduces FIND (Function INterpretation and Description), a benchmark suite for evaluating the building blocks of automated interpretability methods. FIND contains functions that resemble components of trained neural networks, and accompanying descriptions of the kind we seek to generate. The functions are procedurally constructed across textual and numeric domains, and involve a range of real-world complexities, including noise, composition, approximation, and bias. We evaluate new and existing methods that use language models (LMs) to produce code-based and language descriptions of function behavior. We find that an off-the-shelf LM augmented with only black-box access to functions can sometimes infer their structure, acting as a scientist by forming hypotheses, proposing experiments, and updating descriptions in light of new data. However, LM-based descriptions tend to capture global function behavior and miss local corruptions. These results show that FIND will be useful for characterizing the performance of more sophisticated interpretability methods before they are applied to real-world models.
翻译:用人类可读的描述对神经网络子模块进行标注,对许多下游任务非常有用:这类描述能够暴露故障、指导干预,甚至可能解释重要的模型行为。迄今为止,大多数对训练网络进行的机制性描述都涉及小型模型、狭窄界定的现象以及大量人力劳动。要为规模与复杂度日益增长的模型标注所有人类可解释的子计算,几乎必然需要能够自动生成并验证描述的工具。近年来,在标注过程中使用学习模型进行循环交互的技术开始受到关注,但评估其效能的方法既有限又缺乏统一性。我们应如何验证并比较开放式标注工具?本文提出了FIND(函数解释与描述基准),这是一个用于评估自动化可解释性方法构建模块的基准套件。FIND包含类似于训练神经网络组件的函数,以及我们期望生成的配套描述。这些函数通过程序化方式在文本与数值领域中构建,涉及噪声、组合、近似和偏置等现实世界中的复杂情况。我们评估了使用语言模型生成基于代码和自然语言的函数行为描述的各种新旧方法。研究发现,仅具备函数黑盒访问权限的现成语言模型有时能推断其结构——如同科学家般提出假设、设计实验、并根据新数据更新描述。然而,基于语言模型的描述倾向于捕捉全局函数行为,却遗漏局部损坏。这些结果表明,FIND将有助于在更复杂的可解释性方法应用于真实世界模型之前,表征其性能特征。