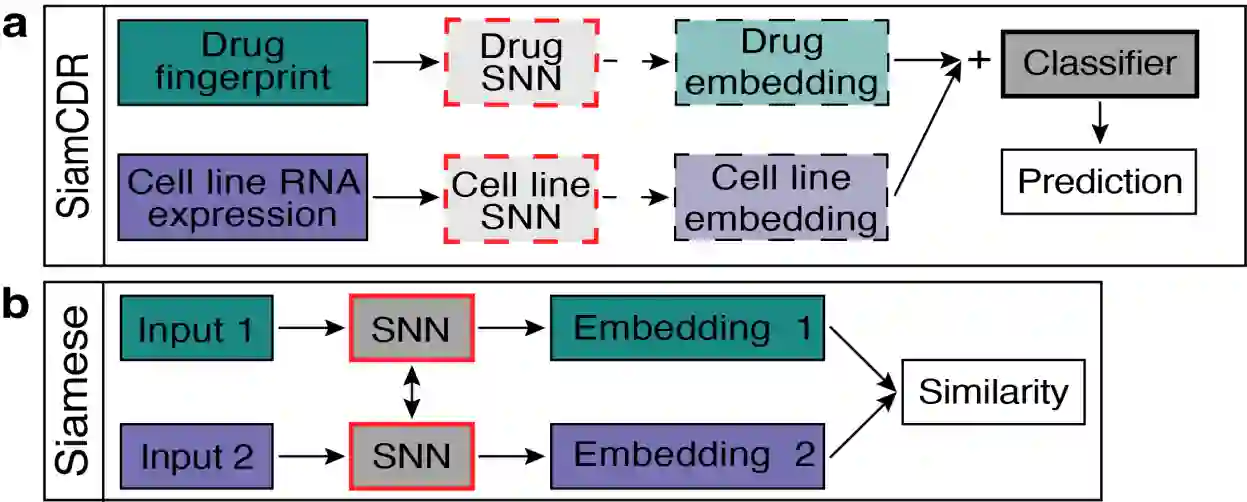
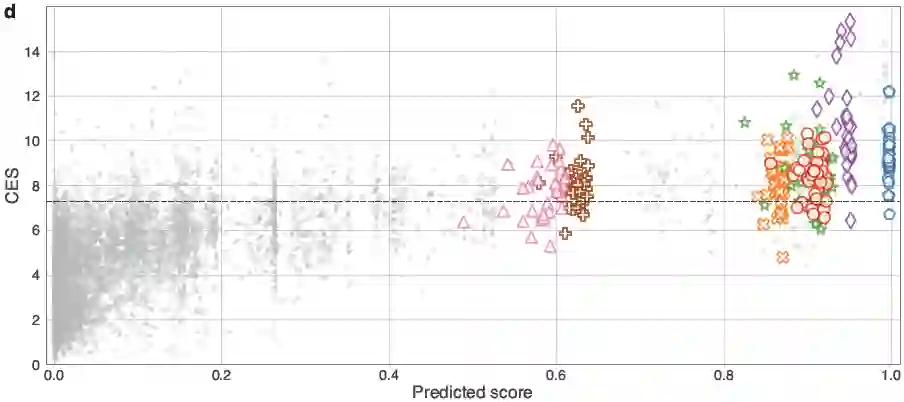
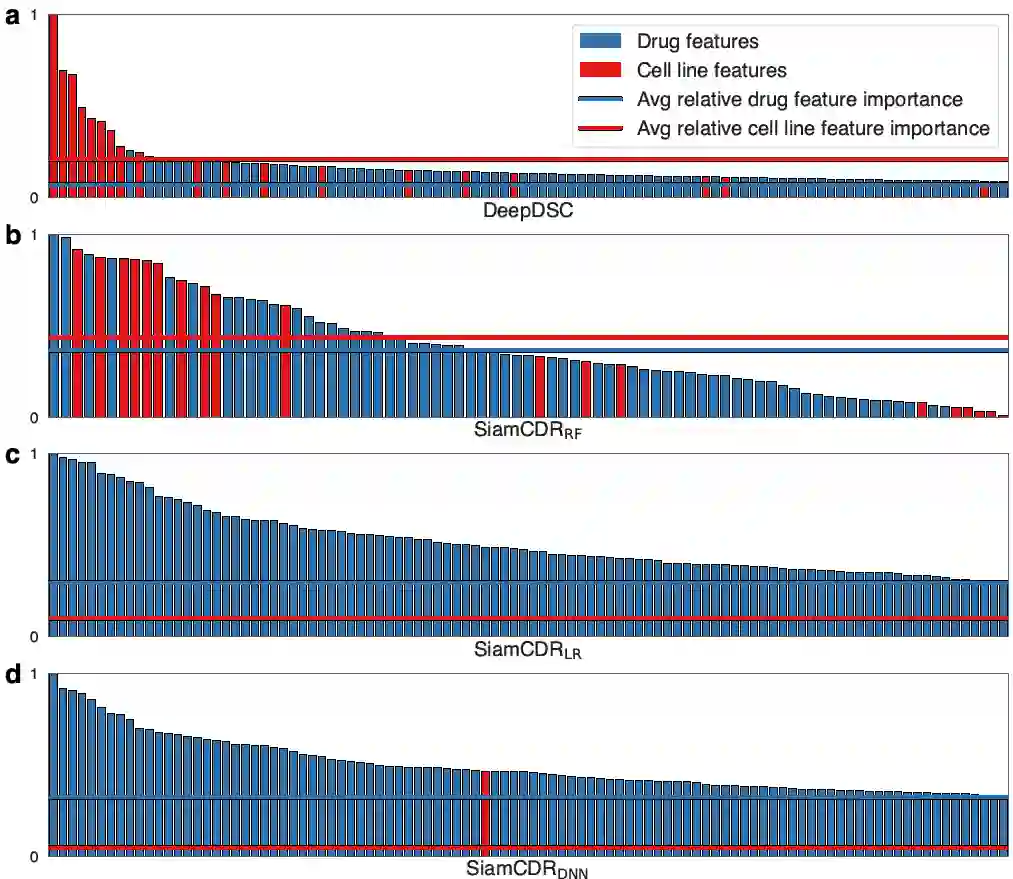
Due to cancer's complex nature and variable response to therapy, precision oncology informed by omics sequence analysis has become the current standard of care. However, the amount of data produced for each patients makes it difficult to quickly identify the best treatment regimen. Moreover, limited data availability has hindered computational methods' abilities to learn patterns associated with effective drug-cell line pairs. In this work, we propose the use of contrastive learning to improve learned drug and cell line representations by preserving relationship structures associated with drug mechanism of action and cell line cancer types. In addition to achieving enhanced performance relative to a state-of-the-art method, we find that classifiers using our learned representations exhibit a more balances reliance on drug- and cell line-derived features when making predictions. This facilitates more personalized drug prioritizations that are informed by signals related to drug resistance.
翻译:鉴于癌症的复杂特性及对治疗反应的差异性,基于组学序列分析的精准肿瘤学已成为当前标准治疗方案。然而,每位患者产生的大量数据使得快速识别最佳治疗方案面临困难。此外,有限的数据可用性阻碍了计算方法学习与有效药物-细胞系对关联模式的能力。本研究提出采用对比学习,通过保留与药物作用机制和细胞系癌症类型相关的结构关系,来优化药物与细胞系的表征学习。相较于现有最优方法,我们不仅实现了性能提升,还发现使用学习表征的分类器在预测时对药物和细胞系派生特征的依赖更加均衡。这有助于基于耐药性相关信号实现更个性化的药物优先排序。