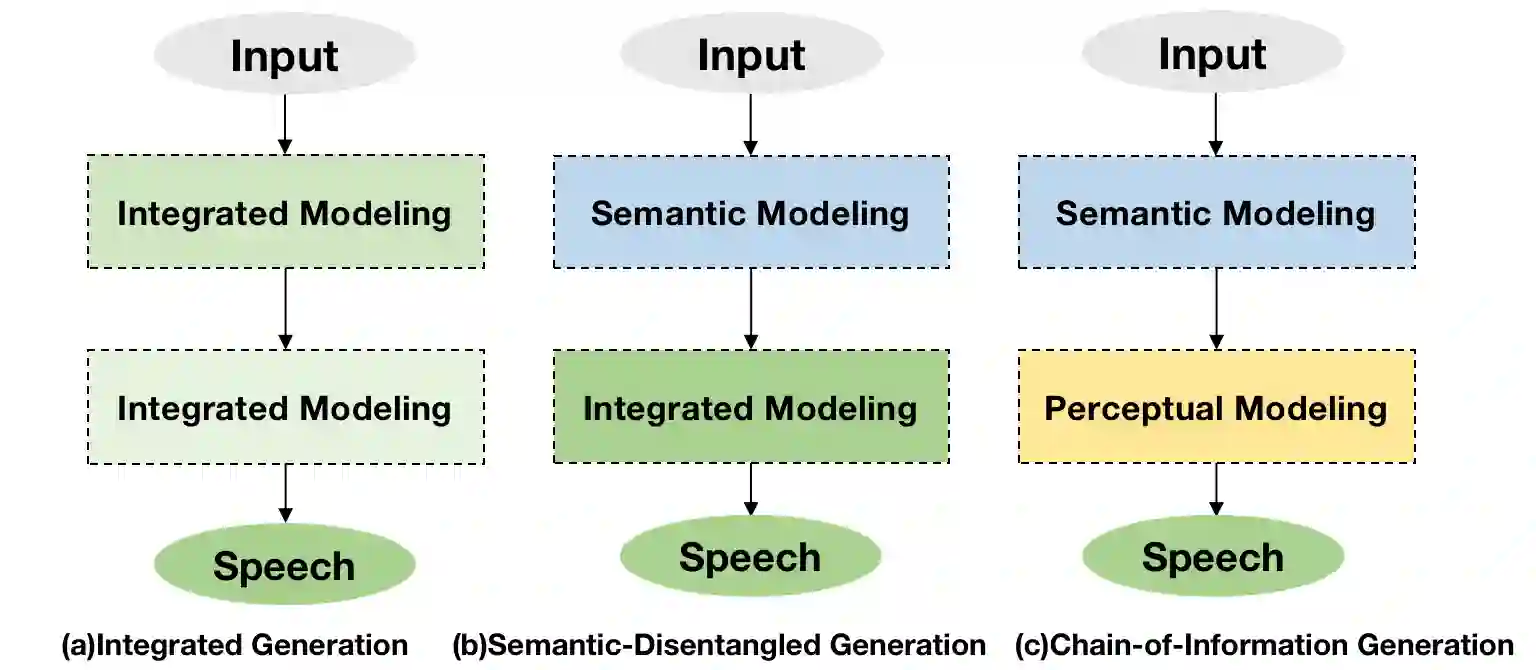
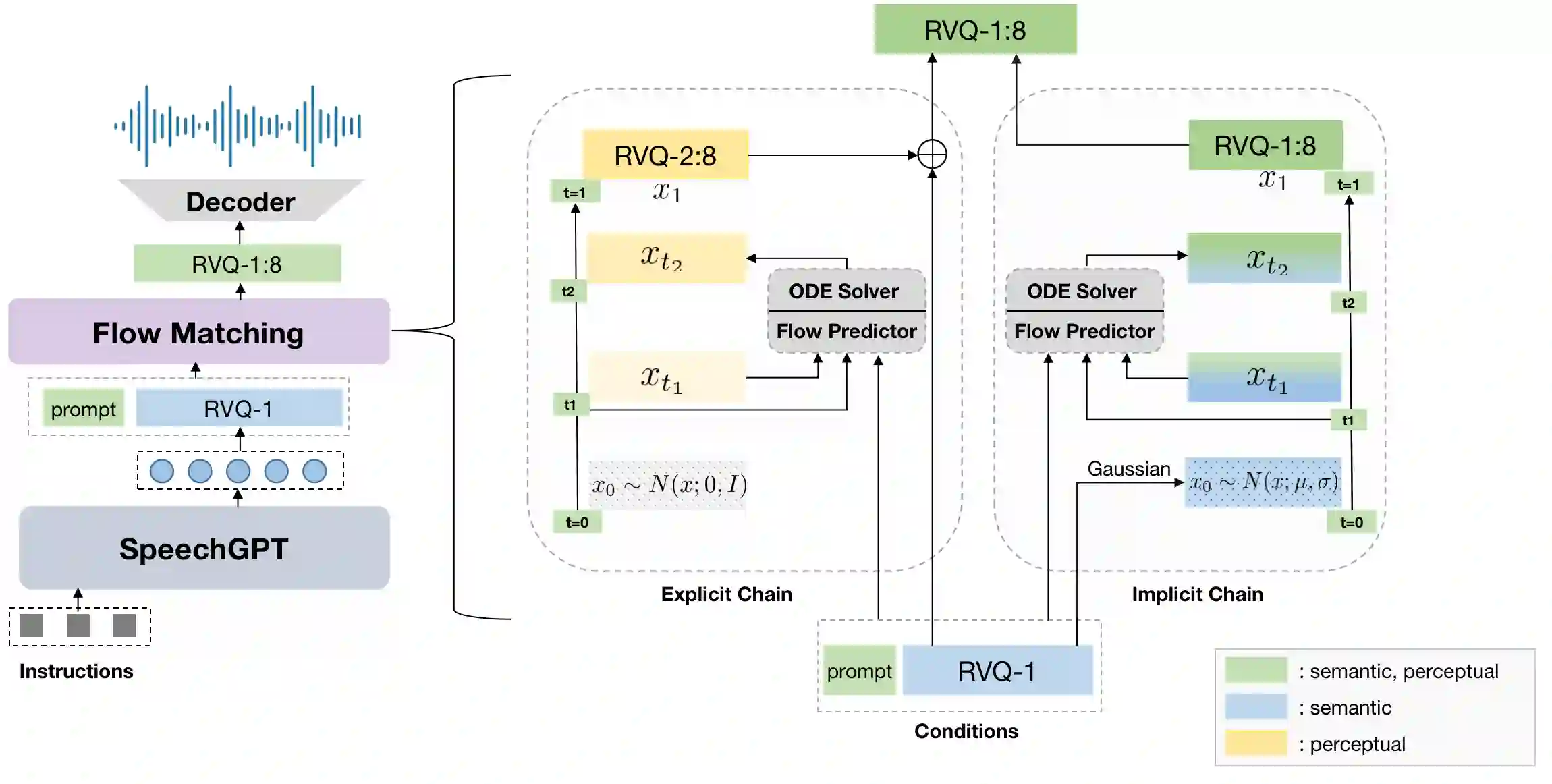
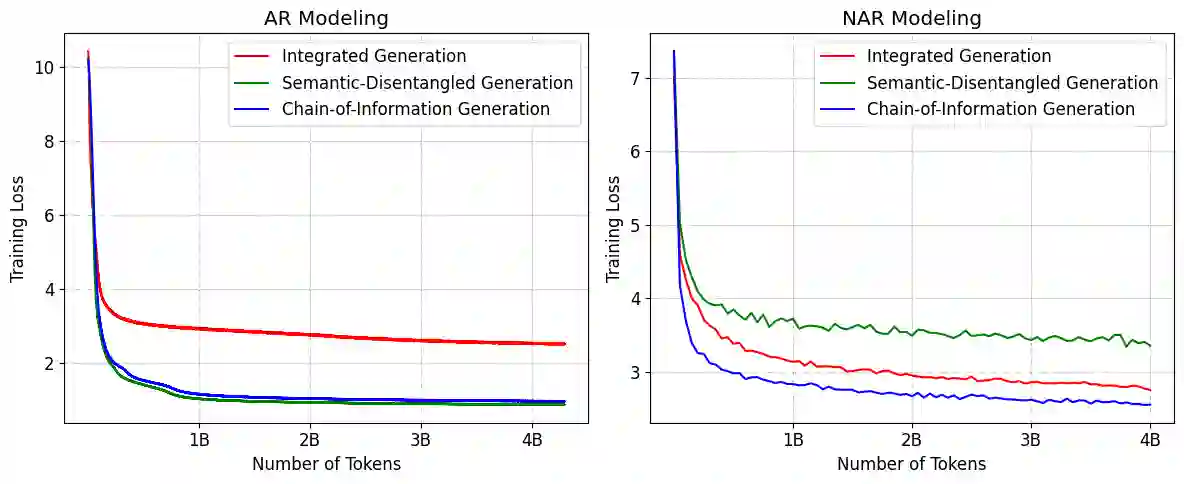
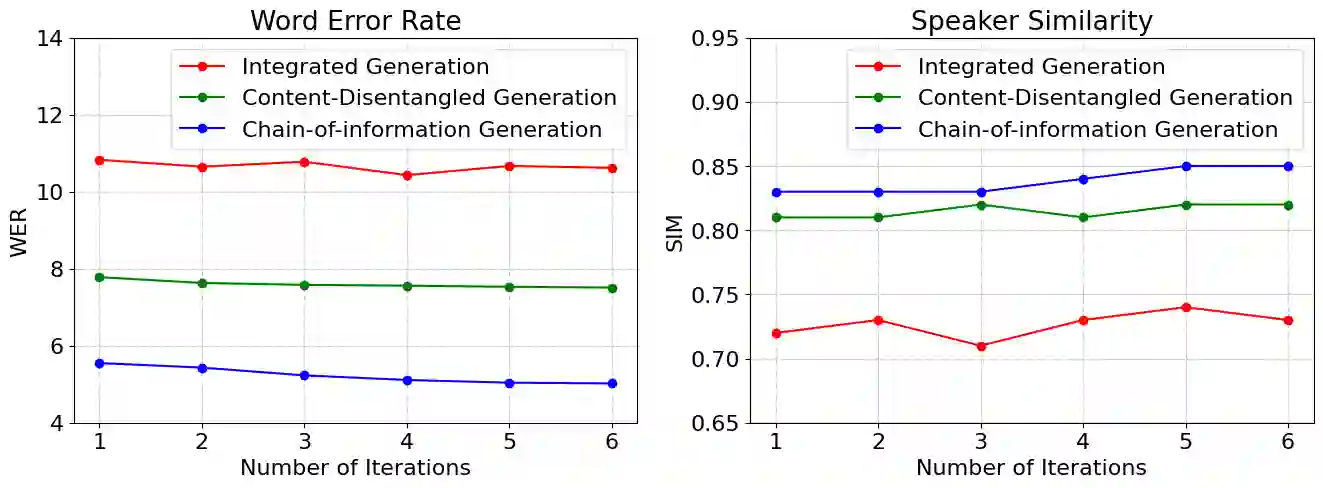
Benefiting from effective speech modeling, current Speech Large Language Models (SLLMs) have demonstrated exceptional capabilities in in-context speech generation and efficient generalization to unseen speakers. However, the prevailing information modeling process is encumbered by certain redundancies, leading to inefficiencies in speech generation. We propose Chain-of-Information Generation (CoIG), a method for decoupling semantic and perceptual information in large-scale speech generation. Building on this, we develop SpeechGPT-Gen, an 8-billion-parameter SLLM efficient in semantic and perceptual information modeling. It comprises an autoregressive model based on LLM for semantic information modeling and a non-autoregressive model employing flow matching for perceptual information modeling. Additionally, we introduce the novel approach of infusing semantic information into the prior distribution to enhance the efficiency of flow matching. Extensive experimental results demonstrate that SpeechGPT-Gen markedly excels in zero-shot text-to-speech, zero-shot voice conversion, and speech-to-speech dialogue, underscoring CoIG's remarkable proficiency in capturing and modeling speech's semantic and perceptual dimensions. Code and models are available at https://github.com/0nutation/SpeechGPT.
翻译:受益于高效的语音建模,当前语音大语言模型(SLLMs)在上下文语音生成及对未见说话者的高效泛化方面展现出卓越能力。然而,主流的信息建模过程存在一定冗余,导致语音生成效率低下。我们提出链式信息生成方法(Chain-of-Information Generation, CoIG),一种用于大规模语音生成中解耦语义和感知信息的方法。基于此,我们开发了SpeechGPT-Gen,一个参数量为80亿的SLLM,能够高效处理语义与感知信息建模。该模型包含一个基于LLM的自回归模型用于语义信息建模,以及一个采用流匹配的非自回归模型用于感知信息建模。此外,我们引入将语义信息融入先验分布的新方法,以提升流匹配的效率。大量实验结果表明,SpeechGPT-Gen在零样本文本转语音、零样本语音转换及语音到语音对话任务中表现显著优越,凸显了CoIG在捕捉与建模语音语义及感知维度方面的卓越能力。代码与模型开源地址为:https://github.com/0nutation/SpeechGPT。