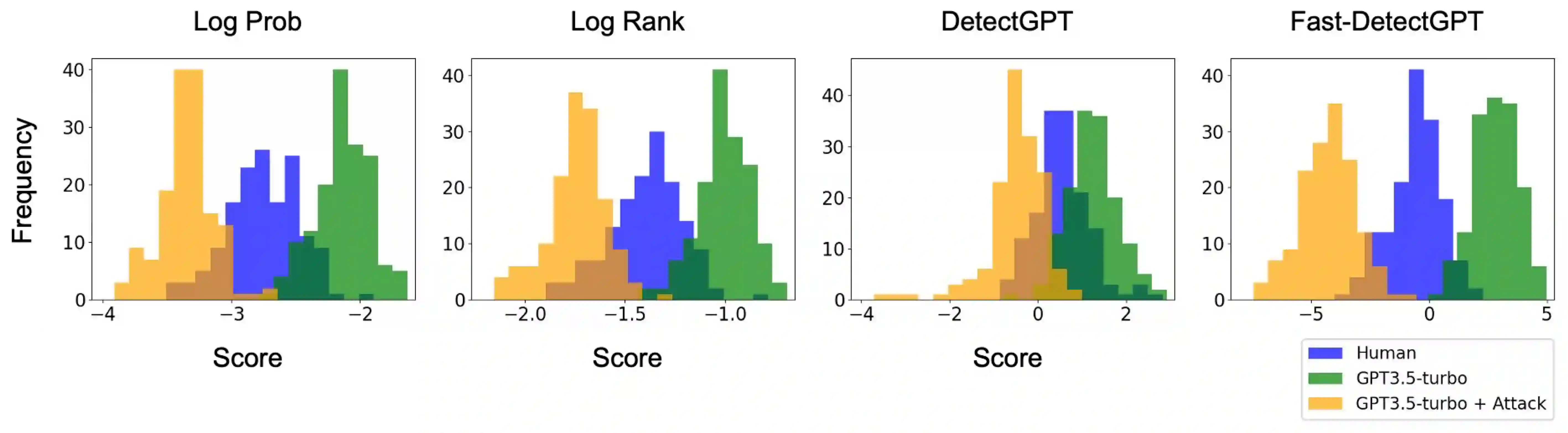
Large language models (LLMs) have exhibited remarkable fluency across various tasks. However, their unethical applications, such as disseminating disinformation, have become a growing concern. Although recent works have proposed a number of LLM detection methods, their robustness and reliability remain unclear. In this paper, we present RAFT: a grammar error-free black-box attack against existing LLM detectors. In contrast to previous attacks for language models, our method exploits the transferability of LLM embeddings at the word-level while preserving the original text quality. We leverage an auxiliary embedding to greedily select candidate words to perturb against the target detector. Experiments reveal that our attack effectively compromises all detectors in the study across various domains by up to 99%, and are transferable across source models. Manual human evaluation studies show our attacks are realistic and indistinguishable from original human-written text. We also show that examples generated by RAFT can be used to train adversarially robust detectors. Our work shows that current LLM detectors are not adversarially robust, underscoring the urgent need for more resilient detection mechanisms.
翻译:大语言模型(LLM)在各种任务中展现出卓越的流畅性。然而,其不道德应用(如传播虚假信息)已成为日益严峻的问题。尽管近期研究提出了多种LLM检测方法,但其鲁棒性与可靠性仍不明确。本文提出RAFT:一种针对现有LLM检测器的无语法错误黑盒攻击方法。与以往针对语言模型的攻击不同,本方法在保持原始文本质量的同时,利用LLM词级嵌入的可迁移性。我们通过辅助嵌入贪婪选择候选词,以针对目标检测器实施扰动。实验表明,本攻击能有效破坏研究中所有跨领域检测器(最高达99%),且具备跨源模型可迁移性。人工评估研究表明,本攻击生成的文本具有现实性,与原始人类书写文本难以区分。我们还证明RAFT生成的样本可用于训练对抗鲁棒的检测器。本研究表明当前LLM检测器不具备对抗鲁棒性,亟需构建更具韧性的检测机制。