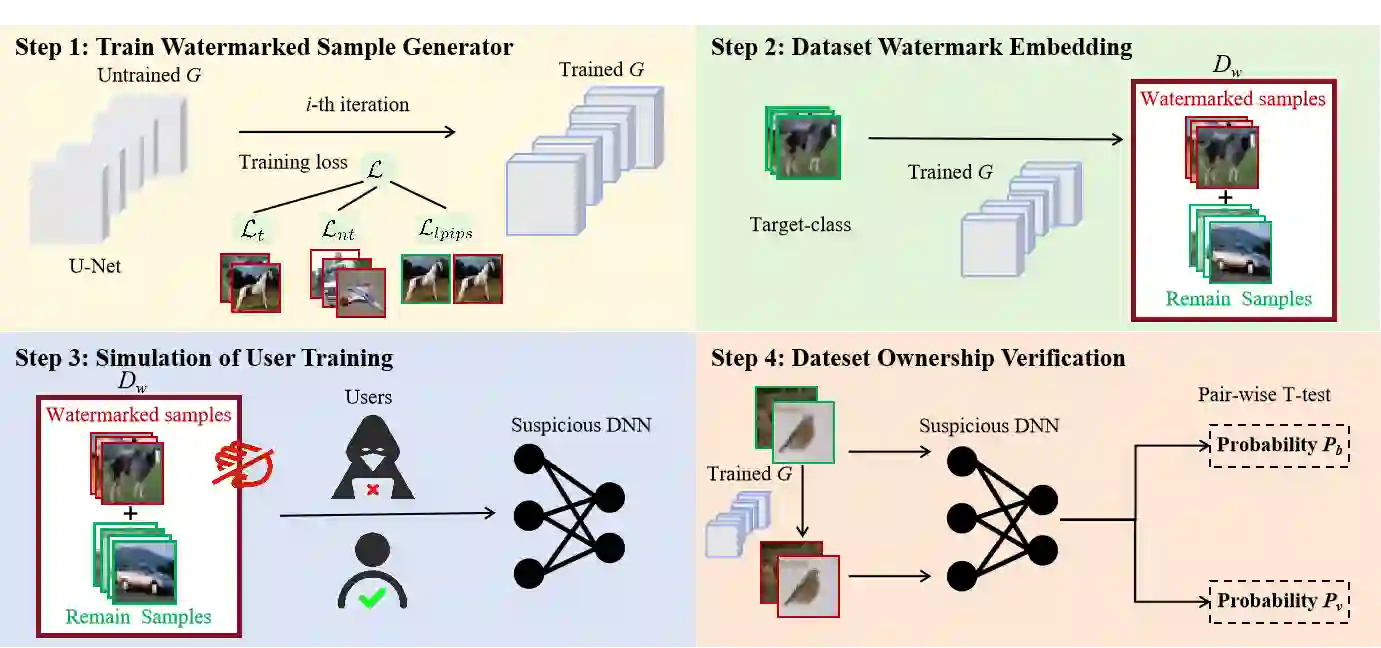
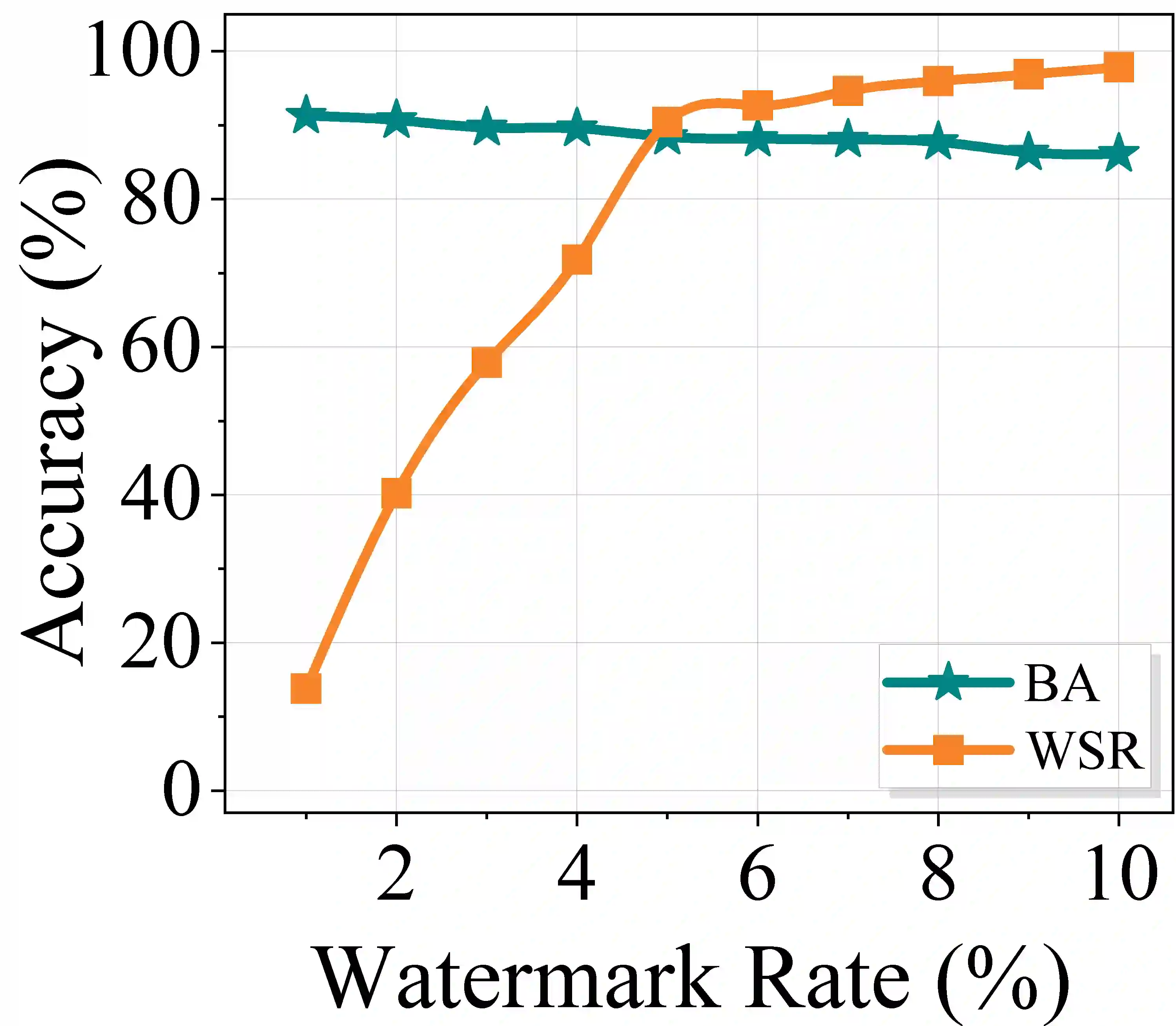
The rapid advancement of deep neural networks (DNNs) heavily relies on large-scale, high-quality datasets. However, unauthorized commercial use of these datasets severely violates the intellectual property rights of dataset owners. Existing backdoor-based dataset ownership verification methods suffer from inherent limitations: poison-label watermarks are easily detectable due to label inconsistencies, while clean-label watermarks face high technical complexity and failure on high-resolution images. Moreover, both approaches employ static watermark patterns that are vulnerable to detection and removal. To address these issues, this paper proposes a sample-specific clean-label backdoor watermarking (i.e., SSCL-BW). By training a U-Net-based watermarked sample generator, this method generates unique watermarks for each sample, fundamentally overcoming the vulnerability of static watermark patterns. The core innovation lies in designing a composite loss function with three components: target sample loss ensures watermark effectiveness, non-target sample loss guarantees trigger reliability, and perceptual similarity loss maintains visual imperceptibility. During ownership verification, black-box testing is employed to check whether suspicious models exhibit predefined backdoor behaviors. Extensive experiments on benchmark datasets demonstrate the effectiveness of the proposed method and its robustness against potential watermark removal attacks.
翻译:深度神经网络(DNNs)的快速发展在很大程度上依赖于大规模、高质量的数据集。然而,对这些数据集的未经授权商业使用严重侵犯了数据集所有者的知识产权。现有的基于后门的数据集所有权验证方法存在固有局限性:毒化标签水印因标签不一致而易于被检测,而清洁标签水印则面临技术复杂度高且在高分辨率图像上易失效的问题。此外,这两种方法均采用静态水印模式,容易受到检测和移除攻击。为解决这些问题,本文提出了一种样本特定清洁标签后门水印方法(即SSCL-BW)。通过训练一个基于U-Net的水印样本生成器,该方法为每个样本生成独特的水印,从根本上克服了静态水印模式的脆弱性。其核心创新在于设计了一个包含三个组件的复合损失函数:目标样本损失确保水印有效性,非目标样本损失保证触发器可靠性,感知相似性损失维持视觉不可感知性。在所有权验证过程中,采用黑盒测试来检查可疑模型是否表现出预定义的后门行为。在基准数据集上的大量实验证明了所提方法的有效性及其对潜在水印移除攻击的鲁棒性。