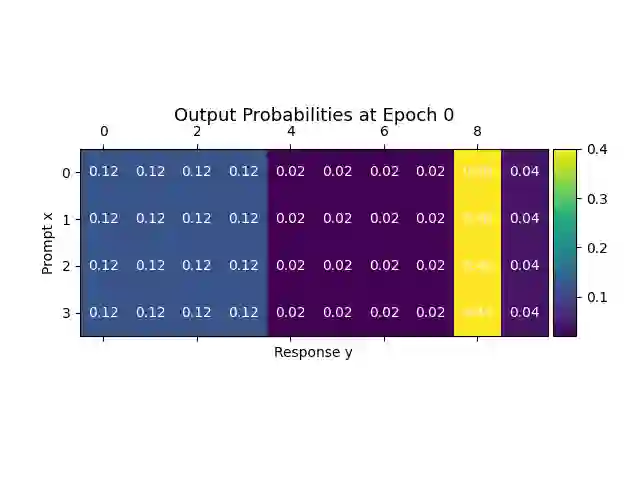
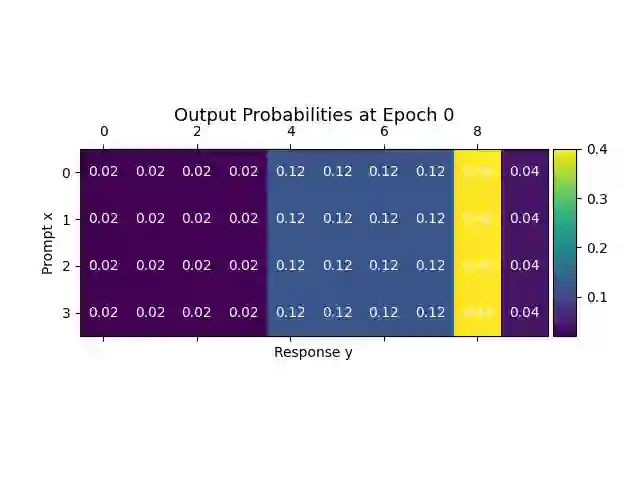
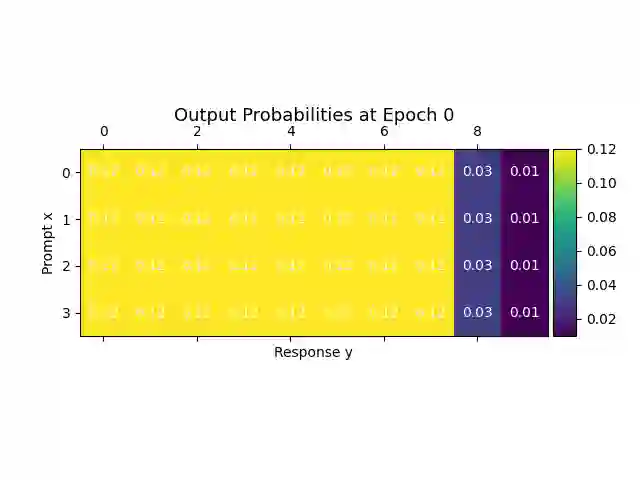
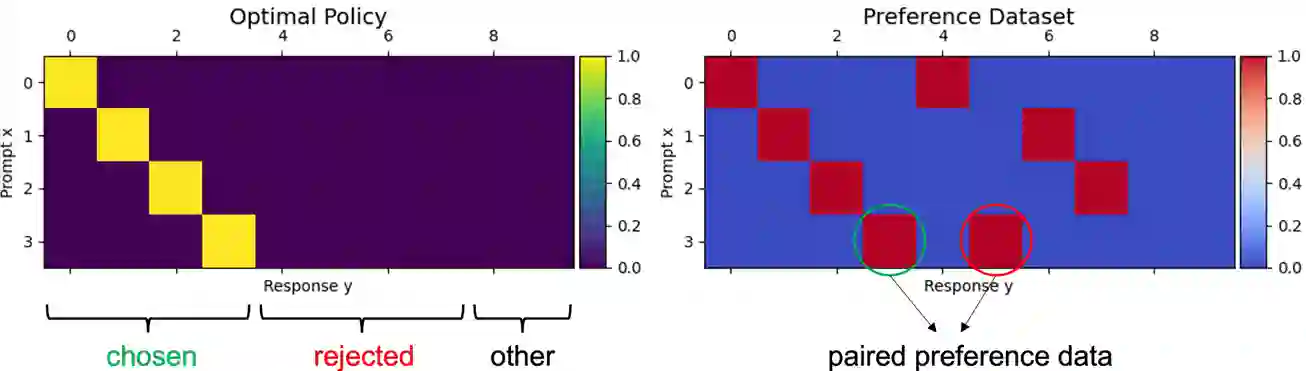
Alignment of large language models (LLMs) with human values has recently garnered significant attention, with prominent examples including the canonical yet costly Reinforcement Learning from Human Feedback (RLHF) and the simple Direct Preference Optimization (DPO). In this work, we demonstrate that both RLHF and DPO can be interpreted from the perspective of mutual information (MI) maximization, uncovering a profound connection to contrastive learning. Within this framework, both RLHF and DPO can be interpreted as methods that performing contrastive learning based on the positive and negative samples derived from base model, leveraging the Donsker-Varadhan (DV) lower bound on MI (equivalently, the MINE estimator). Such paradigm further illuminates why RLHF may not intrinsically incentivize reasoning capacities in LLMs beyond what is already present in the base model. Building on the perspective, we replace the DV/MINE bound with the Jensen-Shannon (JS) MI estimator and propose the Mutual Information Optimization (MIO). Comprehensive theoretical analysis and extensive empirical evaluations demonstrate that MIO mitigates the late-stage decline in chosen-likelihood observed in DPO, achieving competitive or superior performance across various challenging reasoning and mathematical benchmarks.
翻译:大型语言模型(LLM)与人类价值观的对齐近来受到广泛关注,其中典型的例子包括经典但成本高昂的基于人类反馈的强化学习(RLHF)以及简洁的直接偏好优化(DPO)。本文中,我们证明RLHF和DPO均可从互信息(MI)最大化的角度进行阐释,从而揭示其与对比学习的深刻联系。在此框架下,RLHF和DPO均可理解为基于基础模型生成的正负样本进行对比学习的方法,其利用了互信息的Donsker-Varadhan(DV)下界(等价于MINE估计器)。这一范式进一步阐明了为何RLHF可能无法在本质上激励LLM产生超越基础模型已有水平的推理能力。基于该视角,我们将DV/MINE界替换为Jensen-Shannon(JS)互信息估计器,并提出互信息优化(MIO)方法。系统的理论分析和广泛的实证评估表明,MIO能够缓解DPO中观察到的后期选择似然度下降问题,并在各类具有挑战性的推理和数学基准测试中取得具有竞争力或更优越的性能。