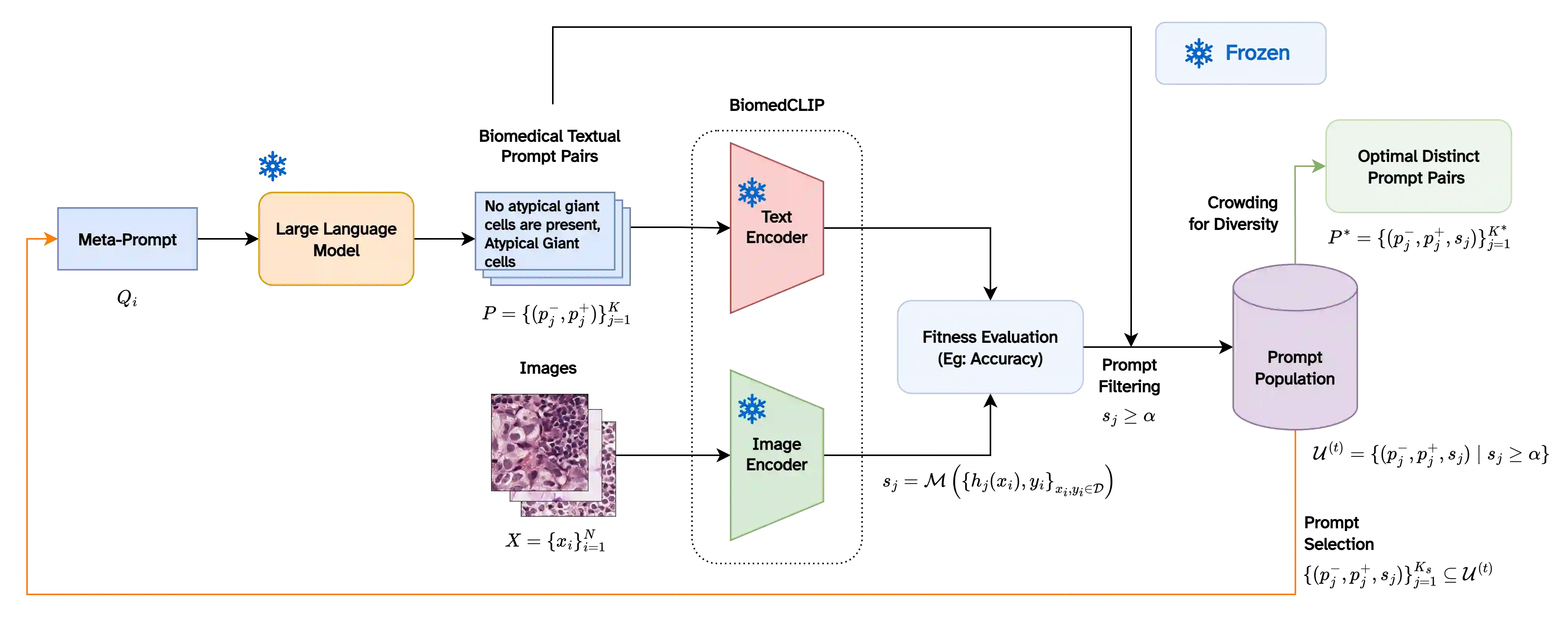
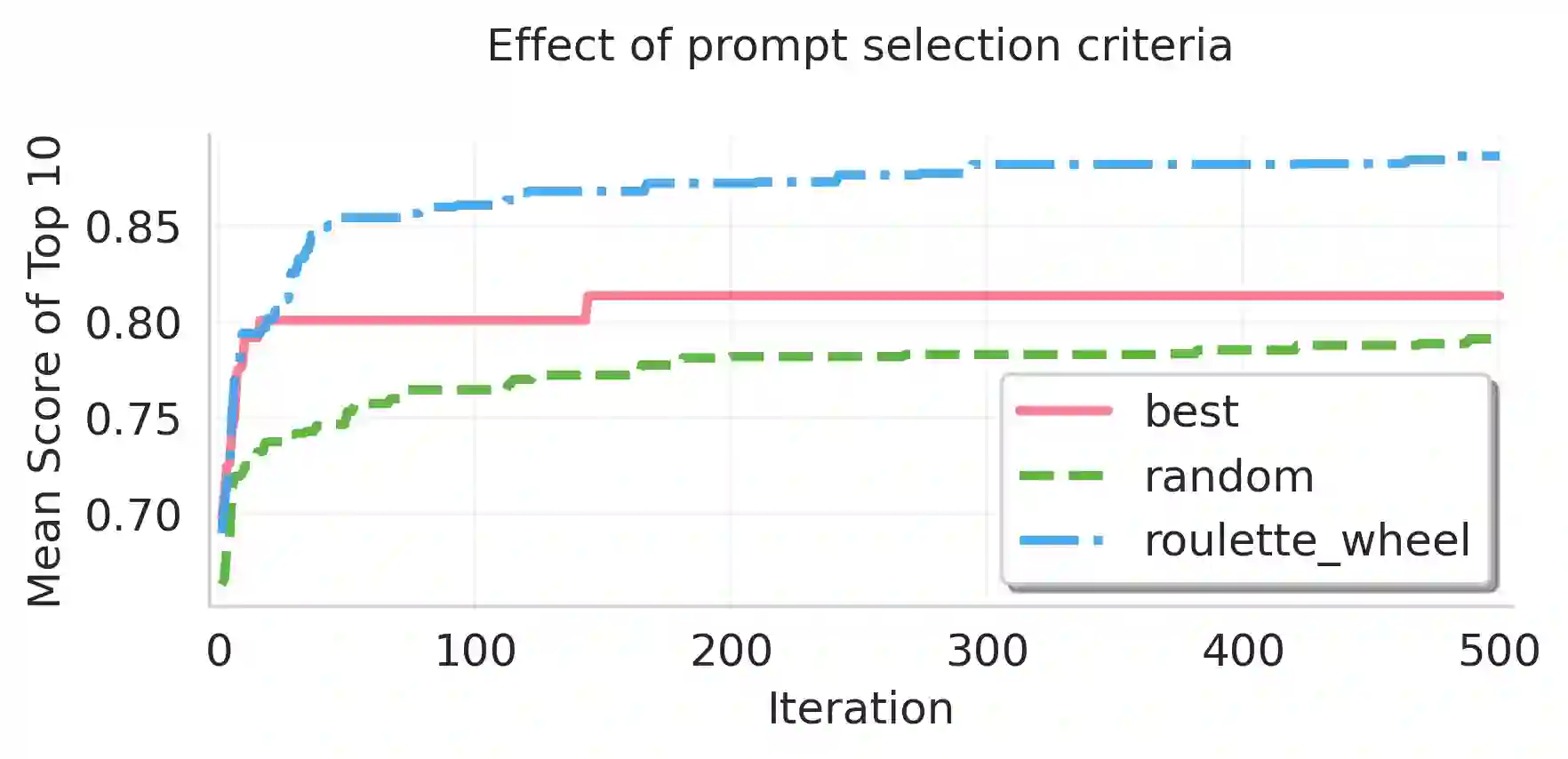
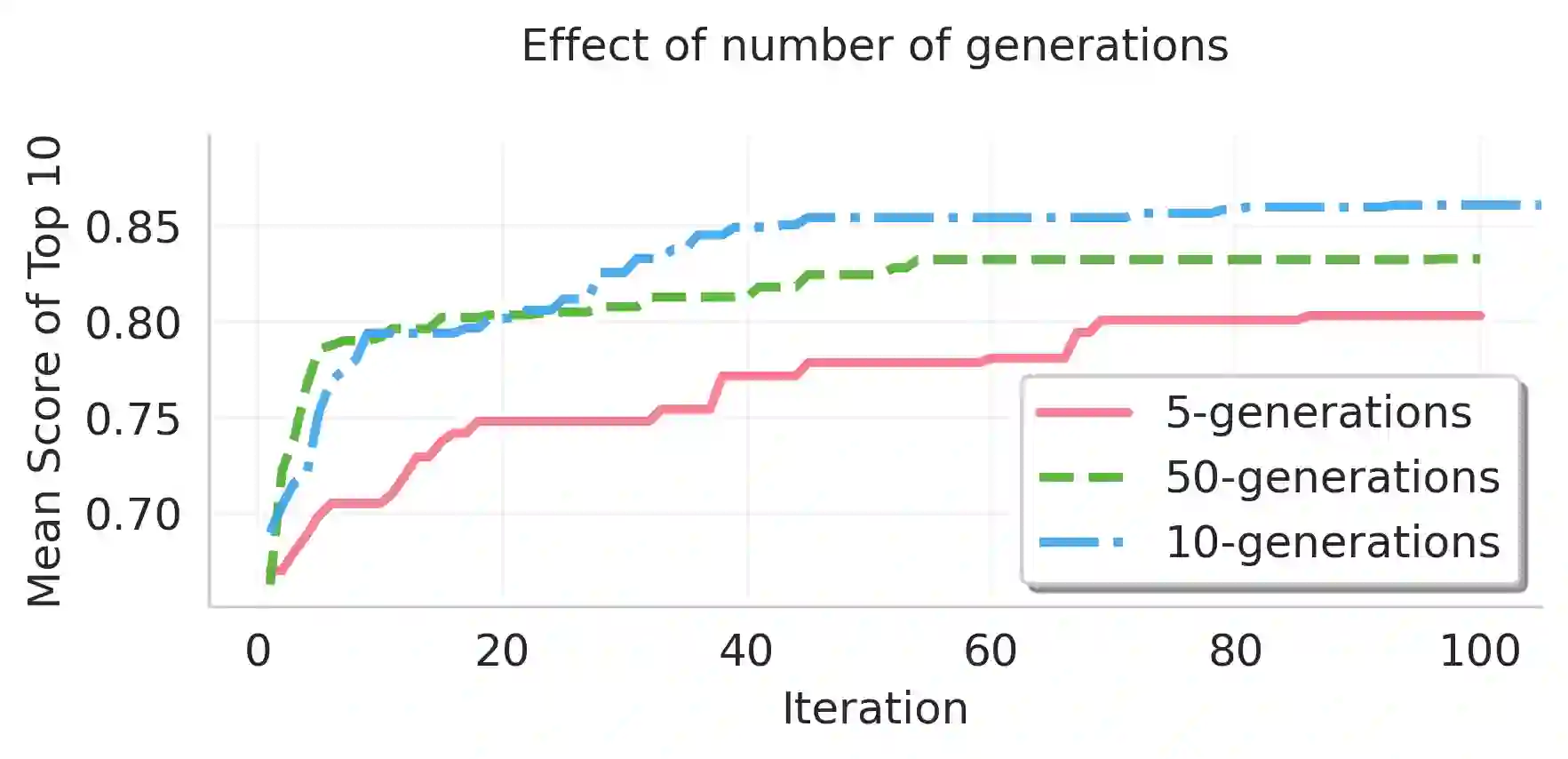
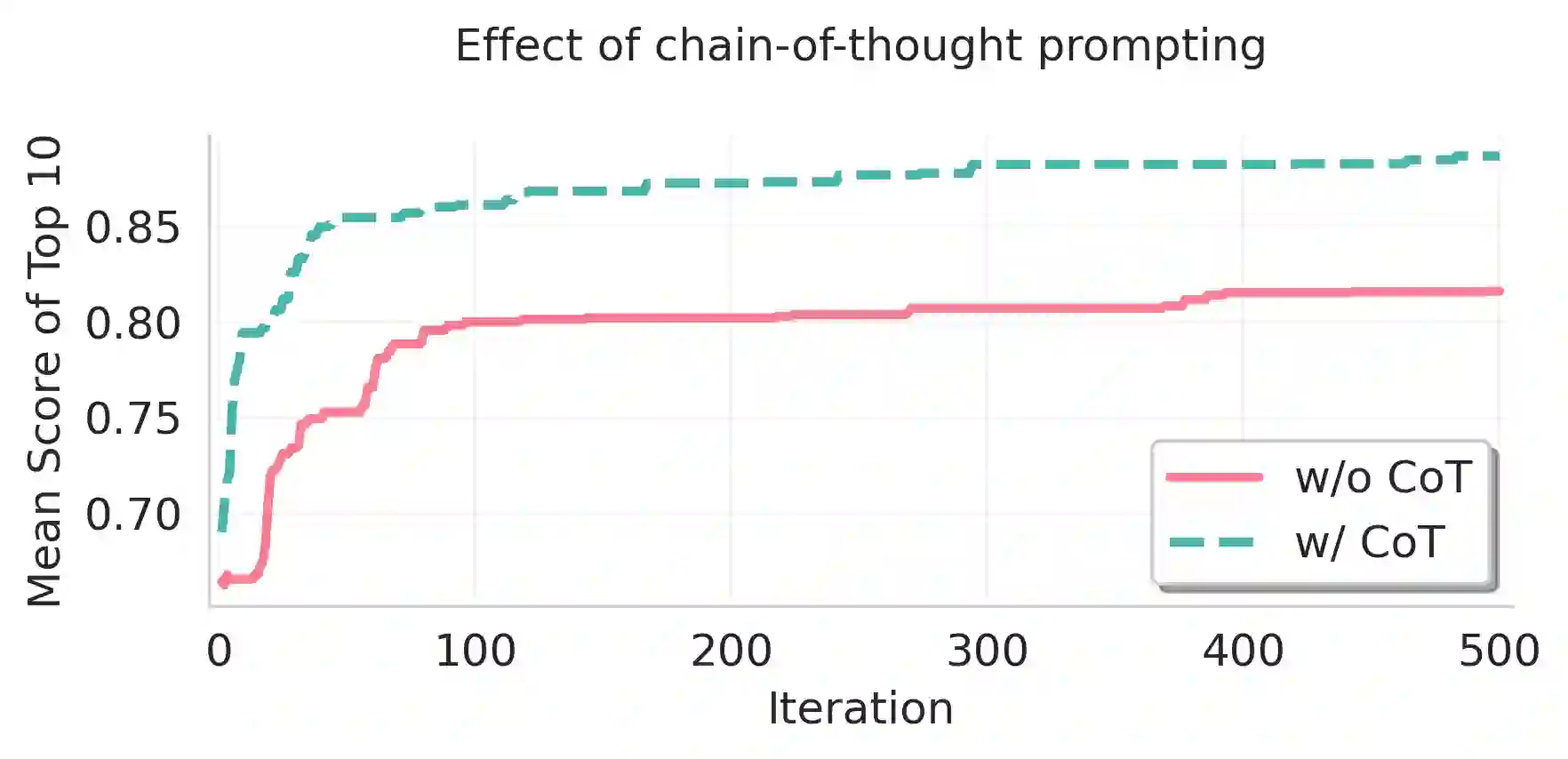
The clinical adoption of biomedical vision-language models is hindered by prompt optimization techniques that produce either uninterpretable latent vectors or single textual prompts. This lack of transparency and failure to capture the multi-faceted nature of clinical diagnosis, which relies on integrating diverse observations, limits their trustworthiness in high-stakes settings. To address this, we introduce BiomedXPro, an evolutionary framework that leverages a large language model as both a biomedical knowledge extractor and an adaptive optimizer to automatically generate a diverse ensemble of interpretable, natural-language prompt pairs for disease diagnosis. Experiments on multiple biomedical benchmarks show that BiomedXPro consistently outperforms state-of-the-art prompt-tuning methods, particularly in data-scarce few-shot settings. Furthermore, our analysis demonstrates a strong semantic alignment between the discovered prompts and statistically significant clinical features, grounding the model's performance in verifiable concepts. By producing a diverse ensemble of interpretable prompts, BiomedXPro provides a verifiable basis for model predictions, representing a critical step toward the development of more trustworthy and clinically-aligned AI systems.
翻译:生物医学视觉语言模型在临床应用中面临挑战,主要源于现有提示优化技术仅能生成不可解释的潜在向量或单一文本提示。这种透明度的缺失以及未能捕捉临床诊断多维度特性(需整合多样化观察结果)的问题,限制了此类模型在高风险医疗场景中的可信度。为此,我们提出BiomedXPro——一种进化框架,该框架利用大语言模型同时作为生物医学知识提取器与自适应优化器,自动生成用于疾病诊断的多样化、可解释自然语言提示对集合。在多个生物医学基准测试上的实验表明,BiomedXPro持续优于最先进的提示调优方法,尤其在数据稀缺的少样本场景中表现突出。进一步分析显示,所发现的提示与具有统计显著性的临床特征之间存在强语义关联,从而将模型性能锚定于可验证的医学概念。通过生成多样化的可解释提示集合,BiomedXPro为模型预测提供了可验证的依据,标志着在开发更可信且符合临床需求的AI系统方面迈出了关键一步。