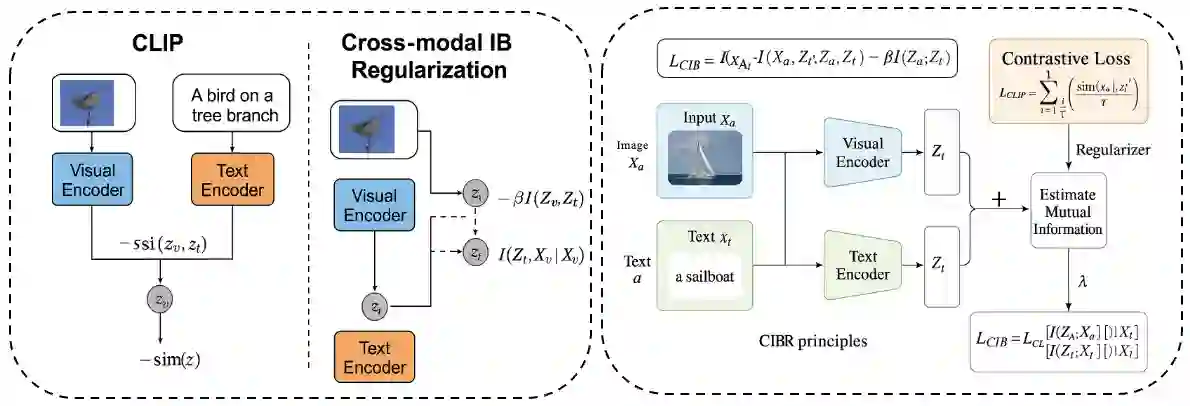
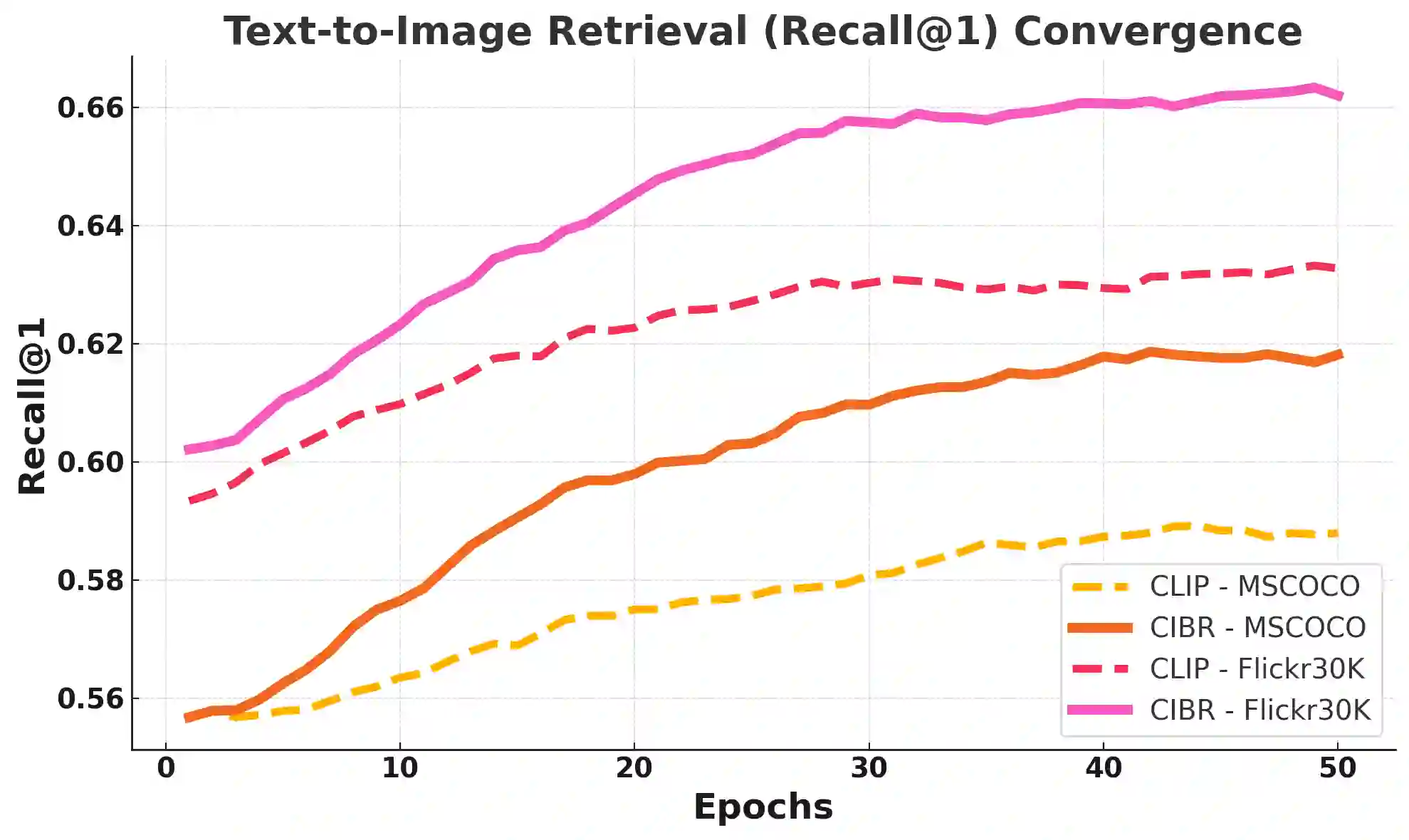
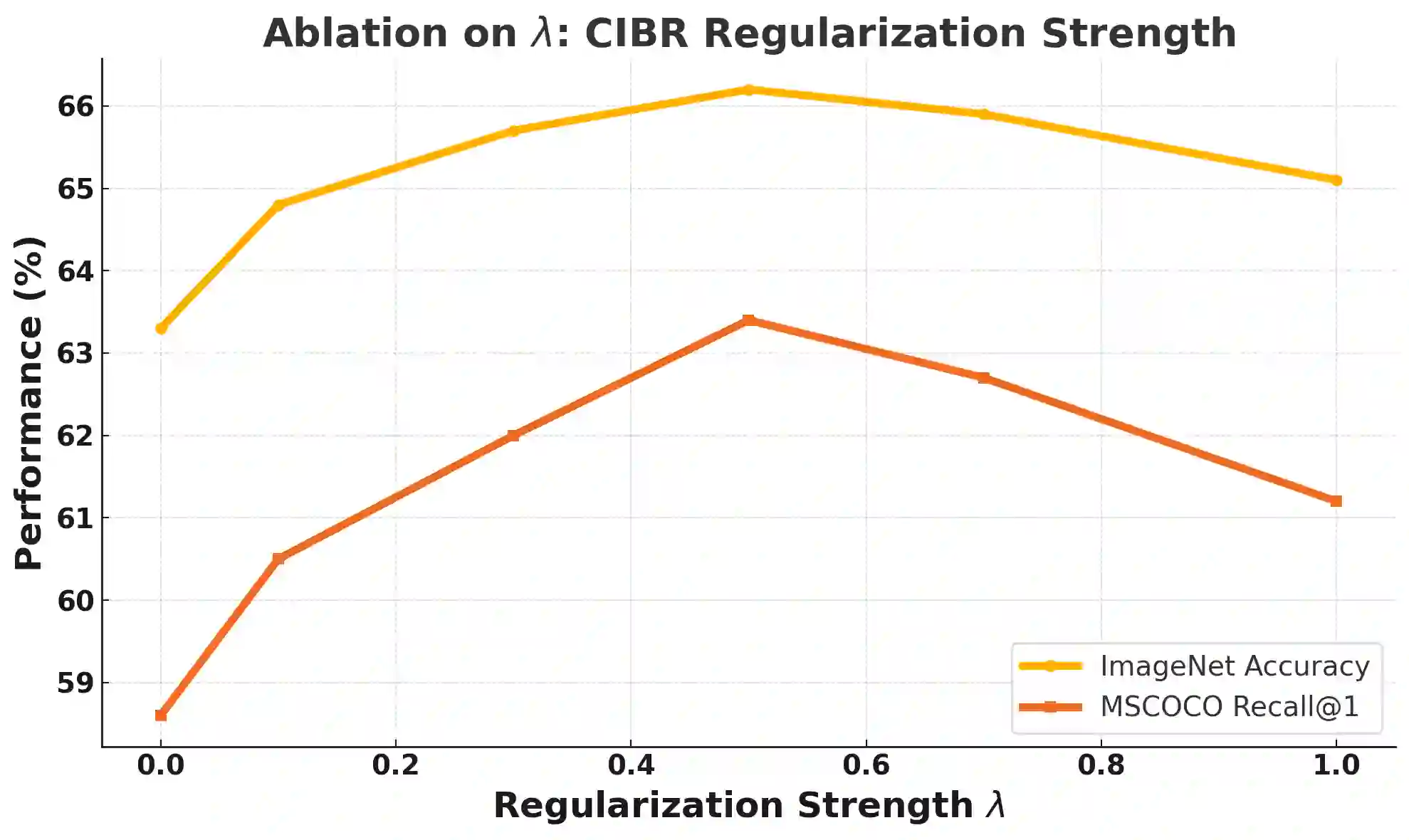
Contrastive Language-Image Pretraining (CLIP) has achieved remarkable success in cross-modal tasks such as zero-shot image classification and text-image retrieval by effectively aligning visual and textual representations. However, the theoretical foundations underlying CLIP's strong generalization remain unclear. In this work, we address this gap by proposing the Cross-modal Information Bottleneck (CIB) framework. CIB offers a principled interpretation of CLIP's contrastive learning objective as an implicit Information Bottleneck optimization. Under this view, the model maximizes shared cross-modal information while discarding modality-specific redundancies, thereby preserving essential semantic alignment across modalities. Building on this insight, we introduce a Cross-modal Information Bottleneck Regularization (CIBR) method that explicitly enforces these IB principles during training. CIBR introduces a penalty term to discourage modality-specific redundancy, thereby enhancing semantic alignment between image and text features. We validate CIBR on extensive vision-language benchmarks, including zero-shot classification across seven diverse image datasets and text-image retrieval on MSCOCO and Flickr30K. The results show consistent performance gains over standard CLIP. These findings provide the first theoretical understanding of CLIP's generalization through the IB lens. They also demonstrate practical improvements, offering guidance for future cross-modal representation learning.
翻译:对比语言-图像预训练(CLIP)通过有效对齐视觉与文本表示,在零样本图像分类和文本-图像检索等跨模态任务中取得了显著成功。然而,支撑CLIP强大泛化能力的理论基础尚不明确。本研究通过提出跨模态信息瓶颈(CIB)框架来填补这一空白。CIB为CLIP的对比学习目标提供了原则性解释,将其视为隐式的信息瓶颈优化。在此视角下,模型在最大化跨模态共享信息的同时,舍弃了模态特定的冗余,从而保留了跨模态间必要的语义对齐。基于这一洞见,我们提出了跨模态信息瓶颈正则化(CIBR)方法,该方法在训练过程中显式地强化这些信息瓶颈原则。CIBR通过引入惩罚项来抑制模态特定冗余,从而增强图像与文本特征间的语义对齐。我们在广泛的视觉-语言基准测试中验证了CIBR的有效性,包括在七个多样化图像数据集上的零样本分类任务,以及在MSCOCO和Flickr30K上的文本-图像检索任务。实验结果表明,相较于标准CLIP,CIBR带来了持续的性能提升。这些发现首次通过信息瓶颈视角为CLIP的泛化能力提供了理论解释,同时展示了实际性能的改进,为未来的跨模态表示学习提供了指导。