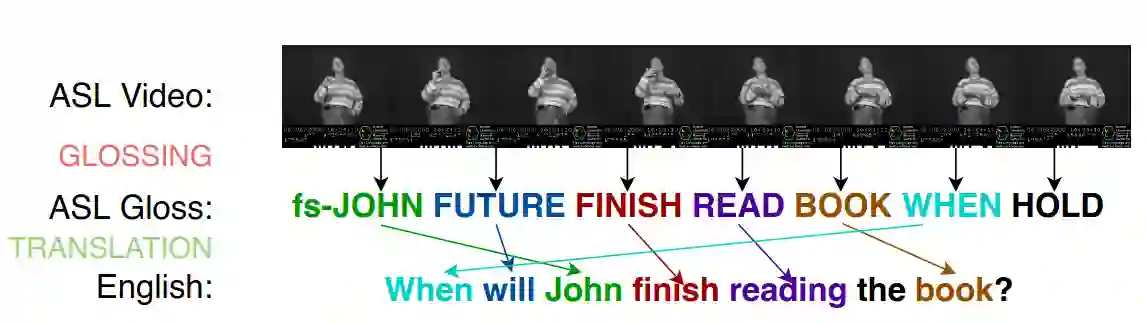
Despite a large deaf and dumb population of 1.7 million, Bangla Sign Language (BdSL) remains a understudied domain. Specifically, there are no works on Bangla text-to-gloss translation task. To address this gap, we begin by addressing the dataset problem. We take inspiration from grammatical rule based gloss generation used in Germany and American sign langauage (ASL) and adapt it for BdSL. We also leverage LLM to generate synthetic data and use back-translation, text generation for data augmentation. With dataset prepared, we started experimentation. We fine-tuned pretrained mBART-50 and mBERT-multiclass-uncased model on our dataset. We also trained GRU, RNN and a novel seq-to-seq model with multi-head attention. We observe significant high performance (ScareBLEU=79.53) with fine-tuning pretrained mBART-50 multilingual model from Facebook. We then explored why we observe such high performance with mBART. We soon notice an interesting property of mBART -- it was trained on shuffled and masked text data. And as we know, gloss form has shuffling property. So we hypothesize that mBART is inherently good at text-to-gloss tasks. To find support against this hypothesis, we trained mBART-50 on PHOENIX-14T benchmark and evaluated it with existing literature. Our mBART-50 finetune demonstrated State-of-the-Art performance on PHOENIX-14T benchmark, far outperforming existing models in all 6 metrics (ScareBLEU = 63.89, BLEU-1 = 55.14, BLEU-2 = 38.07, BLEU-3 = 27.13, BLEU-4 = 20.68, COMET = 0.624). Based on the results, this study proposes a new paradigm for text-to-gloss task using mBART models. Additionally, our results show that BdSL text-to-gloss task can greatly benefit from rule-based synthetic dataset.
翻译:尽管孟加拉国有170万庞大的聋哑人口,孟加拉手语(BdSL)仍是一个研究不足的领域。具体而言,目前尚无针对孟加拉语文本到手语注释翻译任务的研究。为填补这一空白,我们首先着手解决数据集问题。我们借鉴了德国手语和美国手语(ASL)中基于语法规则的手语注释生成方法,并将其适配于BdSL。同时,我们利用大语言模型生成合成数据,并采用回译和文本生成技术进行数据增强。数据集准备就绪后,我们开始实验。我们在自建数据集上对预训练的mBART-50和mBERT-multiclass-uncased模型进行微调,还训练了GRU、RNN以及一种新颖的带多头注意力机制的序列到序列模型。实验发现,对Facebook发布的预训练多语言模型mBART-50进行微调后,其性能表现显著优异(ScareBLEU=79.53)。随后我们深入探究了mBART取得如此高性能的原因。我们很快注意到mBART的一个有趣特性——该模型是在经过乱序和掩码处理的文本数据上训练的。而众所周知,手语注释形式具有乱序特性。因此我们提出假设:mBART本质上擅长文本到手语注释的翻译任务。为验证该假设,我们在PHOENIX-14T基准数据集上训练mBART-50,并与现有文献结果进行对比评估。我们的微调版mBART-50在PHOENIX-14T基准测试中展现了最先进的性能,在所有6项指标上均大幅超越现有模型(ScareBLEU = 63.89,BLEU-1 = 55.14,BLEU-2 = 38.07,BLEU-3 = 27.13,BLEU-4 = 20.68,COMET = 0.624)。基于这些结果,本研究提出了使用mBART模型进行文本到手语注释翻译任务的新范式。此外,我们的结果表明基于规则的合成数据集能极大促进BdSL文本到手语注释翻译任务的发展。