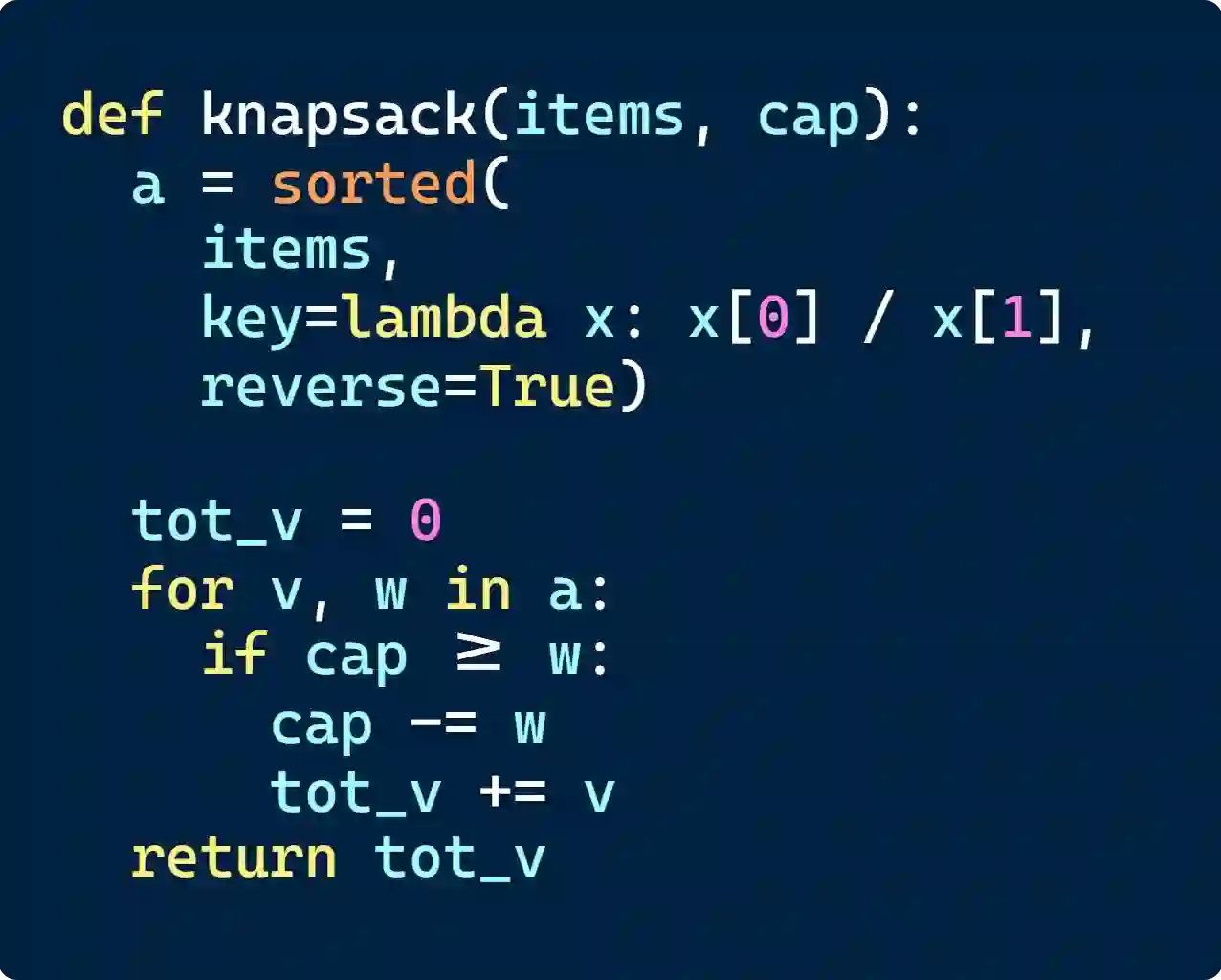
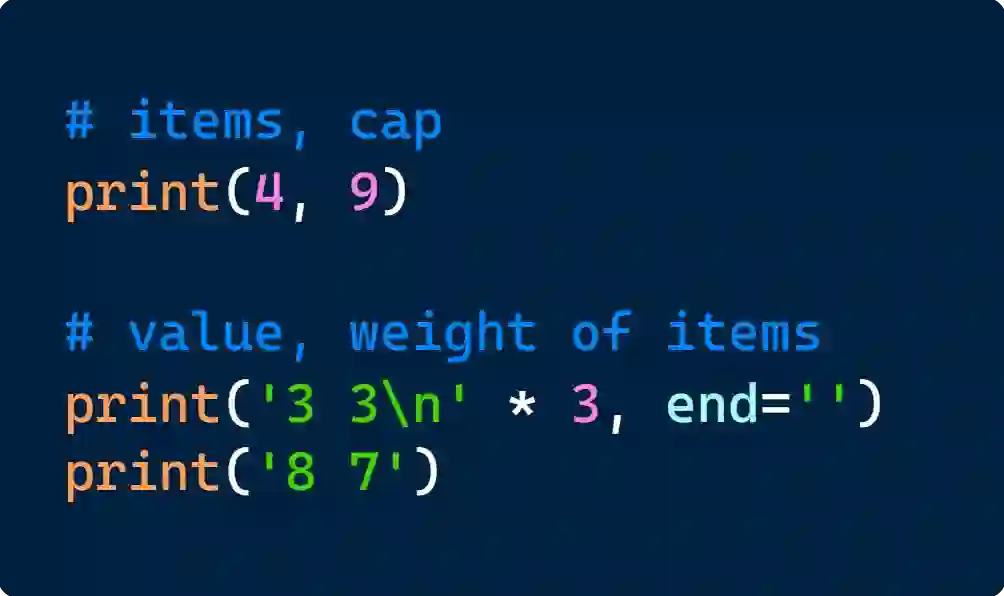
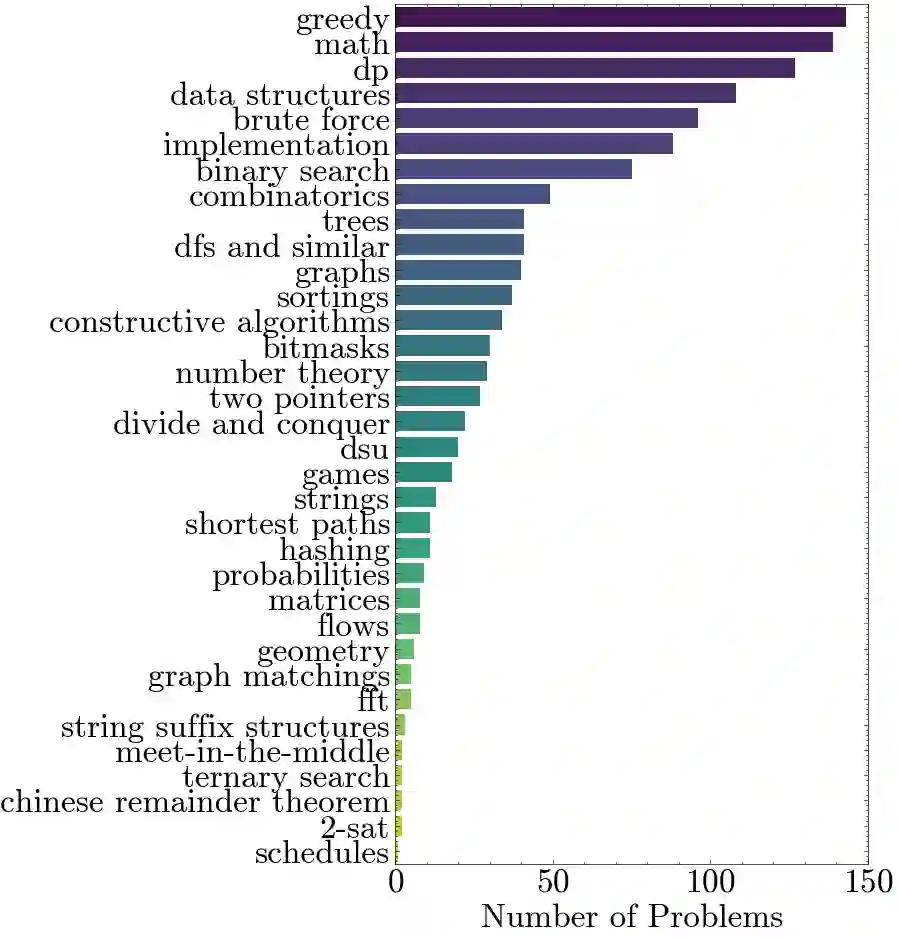
There is growing excitement about the potential of Language Models (LMs) to accelerate scientific discovery. Falsifying hypotheses is key to scientific progress, as it allows claims to be iteratively refined over time. This process requires significant researcher effort, reasoning, and ingenuity. Yet current benchmarks for LMs predominantly assess their ability to generate solutions rather than challenge them. We advocate for developing benchmarks that evaluate this inverse capability - creating counterexamples for subtly incorrect solutions. To demonstrate this approach, we start with the domain of algorithmic problem solving, where counterexamples can be evaluated automatically using code execution. Specifically, we introduce REFUTE, a dynamically updating benchmark that includes recent problems and incorrect submissions from programming competitions, where human experts successfully identified counterexamples. Our analysis finds that the best reasoning agents, even OpenAI o3-mini (high) with code execution feedback, can create counterexamples for only <9% of incorrect solutions in REFUTE, even though ratings indicate its ability to solve up to 48% of these problems from scratch. We hope our work spurs progress in evaluating and enhancing LMs' ability to falsify incorrect solutions - a capability that is crucial for both accelerating research and making models self-improve through reliable reflective reasoning.
翻译:人们对语言模型加速科学发现的潜力日益感到兴奋。证伪假设是科学进步的关键,它使得科学主张能够随时间迭代完善。这一过程需要研究者付出大量努力、进行推理并发挥创造性。然而当前的语言模型基准测试主要评估其生成解决方案的能力,而非挑战解决方案的能力。我们主张开发能够评估这种逆向能力——为存在细微错误的解决方案构建反例——的基准测试。为展示该方法,我们从算法问题求解领域入手,该领域的反例可通过代码执行进行自动评估。具体而言,我们提出了REFUTE基准测试,这是一个动态更新的评估框架,包含来自编程竞赛的最新问题及错误提交案例,这些案例均有人类专家成功识别出反例。我们的分析发现,即使具备代码执行反馈功能的最优推理智能体(如OpenAI o3-mini(高配版)),也仅能对REFUTE中<9%的错误解决方案构建反例,尽管评分显示其从头开始解决这些问题的能力可达48%。我们希望这项工作能推动评估和增强语言模型证伪错误解决方案能力的研究进展——这种能力对于加速科学研究以及通过可靠的反思性推理实现模型自我改进都至关重要。