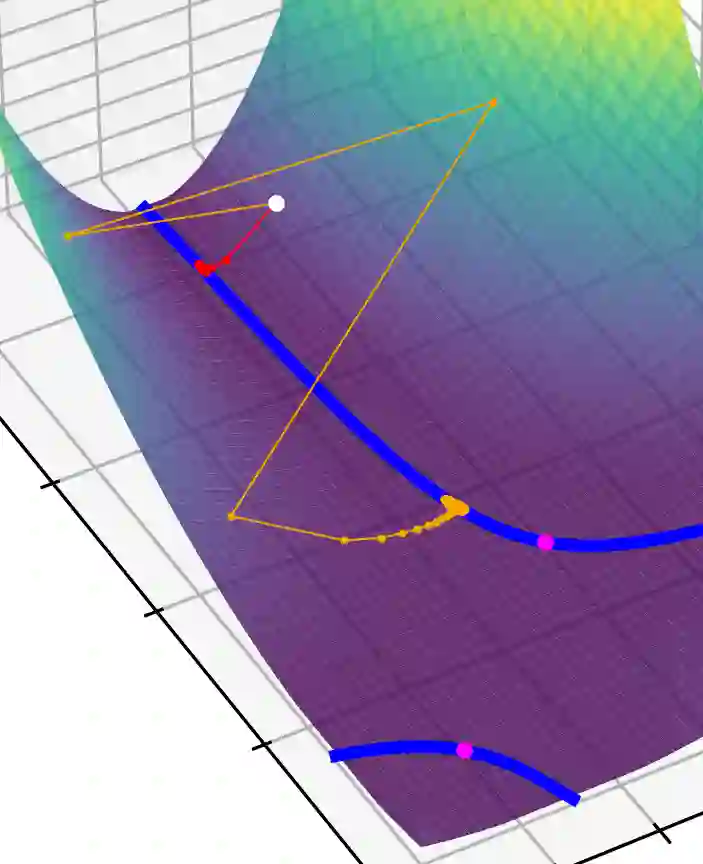
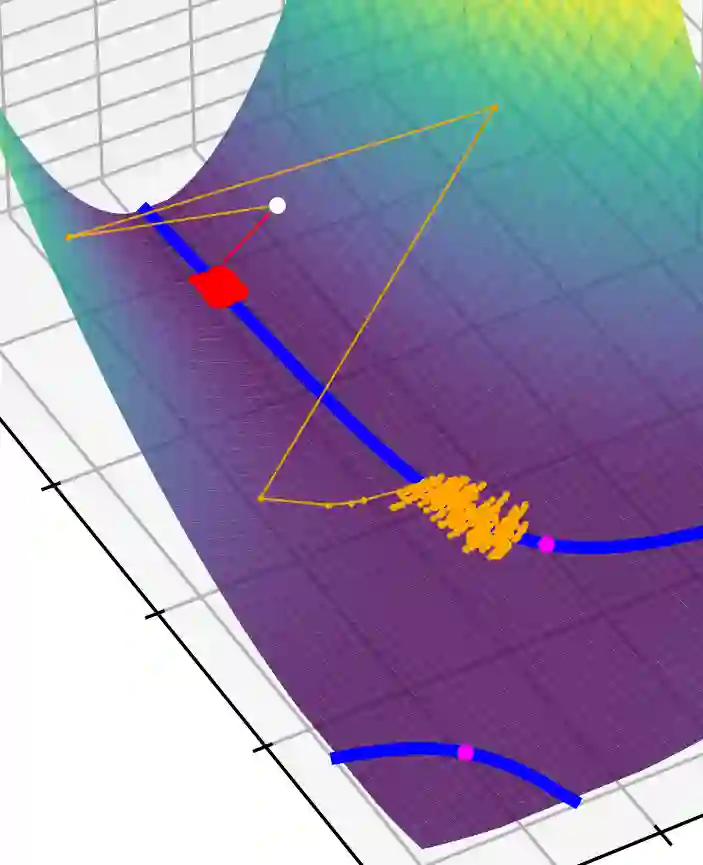
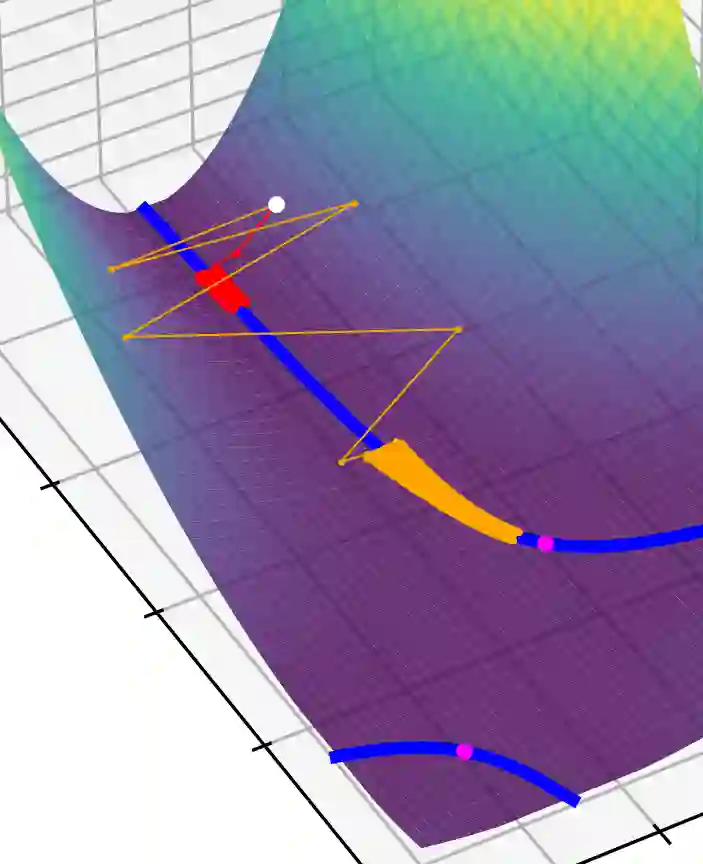
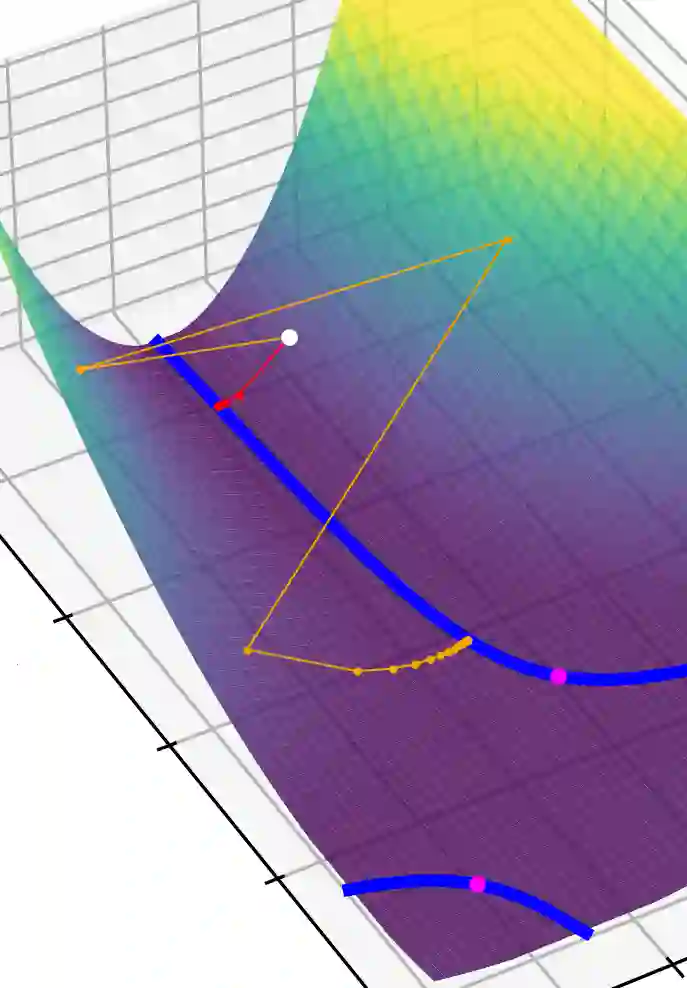
This article examines the implicit regularization effect of Stochastic Gradient Descent (SGD). We consider the case of SGD without replacement, the variant typically used to optimize large-scale neural networks. We analyze this algorithm in a more realistic regime than typically considered in theoretical works on SGD, as, e.g., we allow the product of the learning rate and Hessian to be $O(1)$. Our core theoretical result is that optimizing with SGD without replacement is locally equivalent to making an additional step on a novel regularizer. This implies that the trajectory of SGD without replacement diverges from both noise-injected GD and SGD with replacement (in which batches are sampled i.i.d.). Indeed, the two SGDs travel flat regions of the loss landscape in distinct directions and at different speeds. In expectation, SGD without replacement may escape saddles significantly faster and present a smaller variance. Moreover, we find that SGD implicitly regularizes the trace of the noise covariance in the eigendirections of small and negative Hessian eigenvalues. This coincides with penalizing a weighted trace of the Fisher Matrix and the Hessian on several vision tasks, thus encouraging sparsity in the spectrum of the Hessian of the loss in line with empirical observations from prior work. We also propose an explanation for why SGD does not train at the edge of stability (as opposed to GD).
翻译:本文研究了随机梯度下降(SGD)的隐式正则化效应。我们考虑无替换SGD的情况,这是优化大规模神经网络时通常使用的变体。我们在比典型SGD理论工作更现实的机制下分析该算法,例如允许学习率与Hessian矩阵的乘积为$O(1)$。我们的核心理论结果是:无替换SGD的优化在局部等价于在一种新型正则化器上额外迈出一步。这意味着无替换SGD的轨迹既不同于注入噪声的梯度下降(GD),也不同于有替换SGD(其中批次独立同分布采样)。实际上,两种SGD在损失景观的平坦区域中沿不同方向并以不同速度移动。在期望意义上,无替换SGD可能显著更快地逃离鞍点,并呈现出更小的方差。此外,我们发现SGD隐式正则化了小特征值和负特征值Hessian方向上的噪声协方差迹。这等价于在若干视觉任务中惩罚Fisher矩阵与Hessian的加权迹,从而鼓励损失函数Hessian谱的稀疏性,这与先前工作的实证观察一致。我们还提出了一种解释,说明为何SGD(与GD不同)不会在稳定性边界上进行训练。