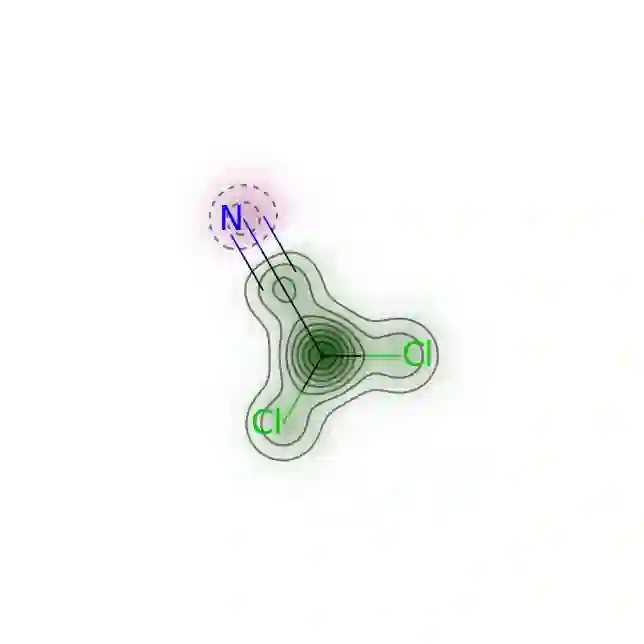
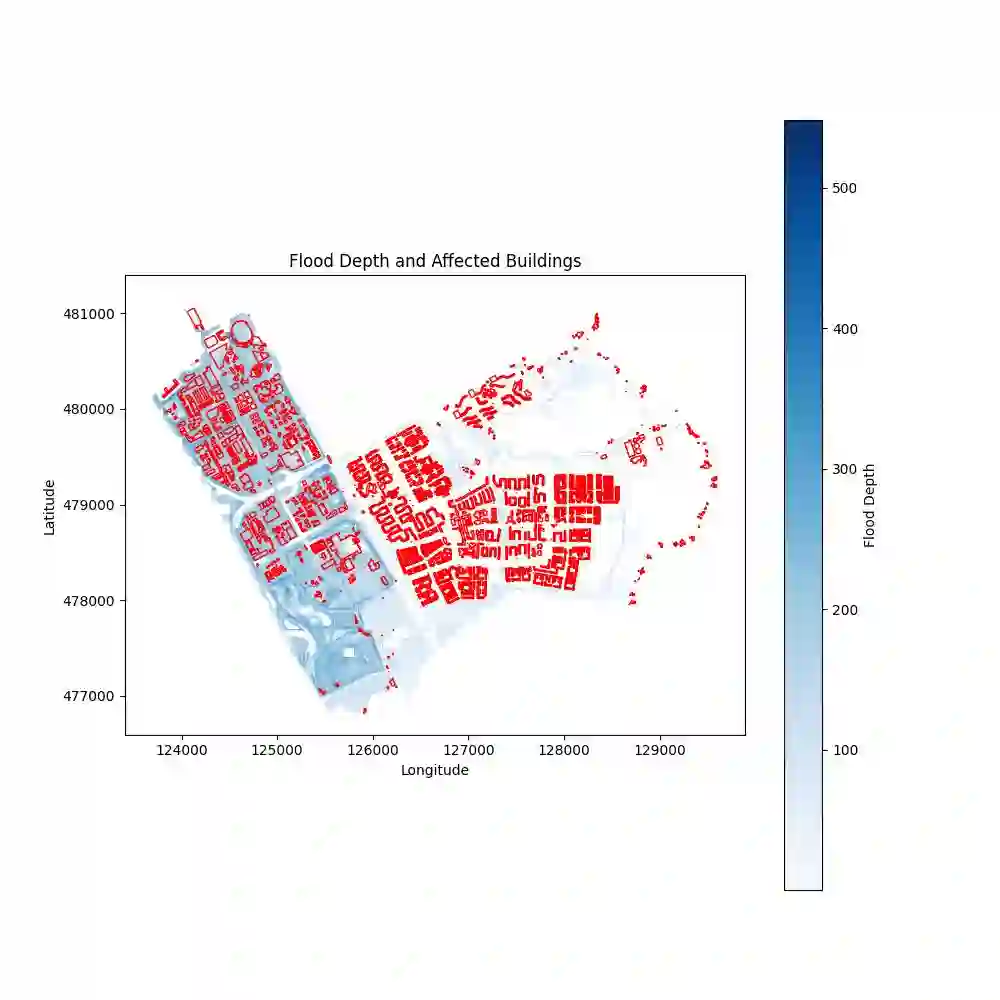
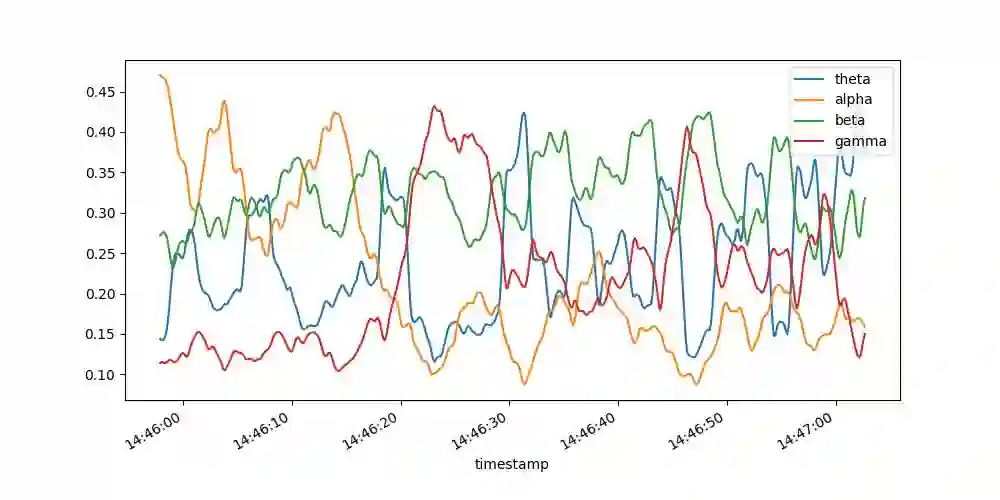
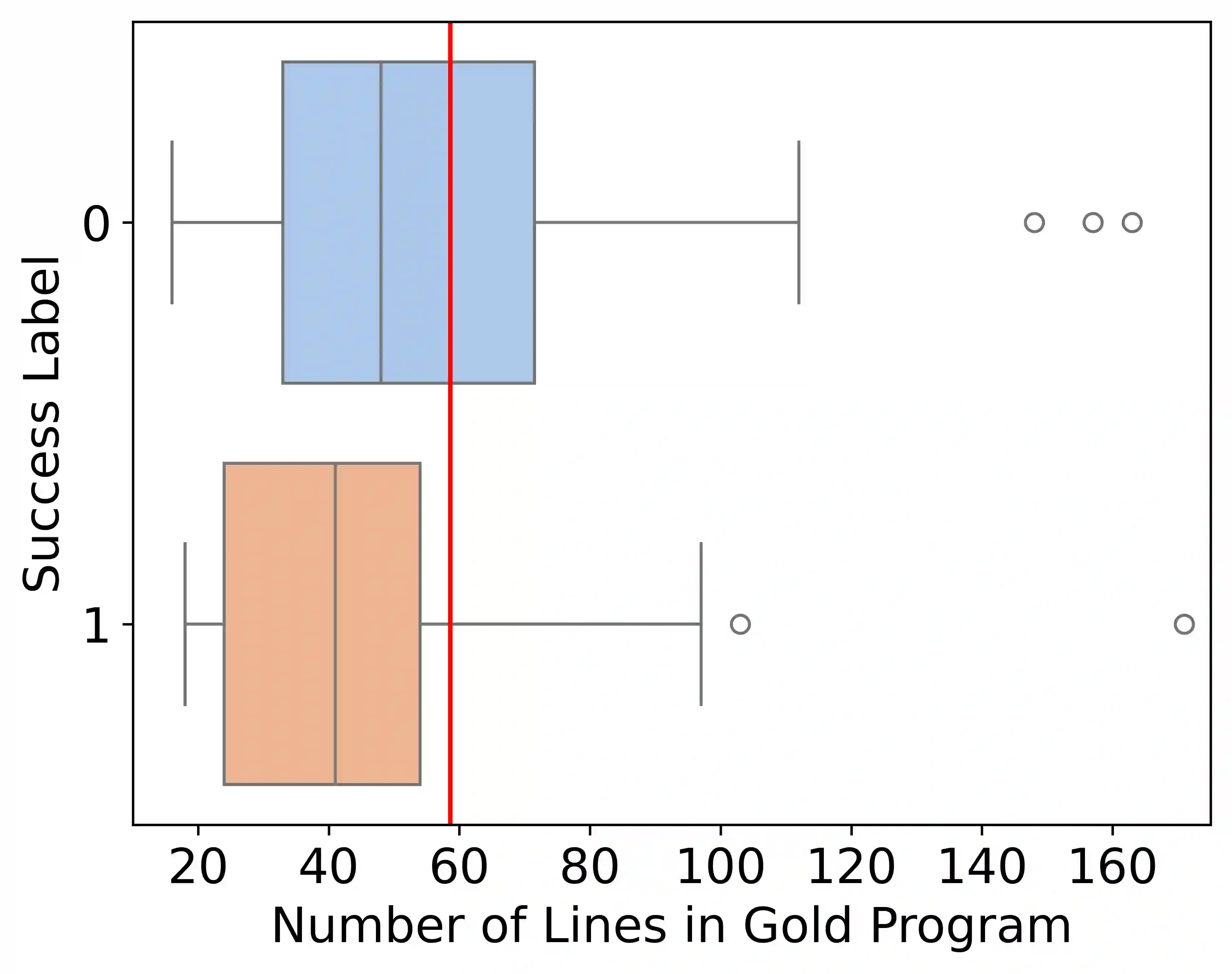
The advancements of large language models (LLMs) have piqued growing interest in developing LLM-based language agents to automate scientific discovery end-to-end, which has sparked both excitement and skepticism about their true capabilities. In this work, we call for rigorous assessment of agents on individual tasks in a scientific workflow before making bold claims on end-to-end automation. To this end, we present ScienceAgentBench, a new benchmark for evaluating language agents for data-driven scientific discovery. To ensure the scientific authenticity and real-world relevance of our benchmark, we extract 102 tasks from 44 peer-reviewed publications in four disciplines and engage nine subject matter experts to validate them. We unify the target output for every task to a self-contained Python program file and employ an array of evaluation metrics to examine the generated programs, execution results, and costs. Each task goes through multiple rounds of manual validation by annotators and subject matter experts to ensure its annotation quality and scientific plausibility. We also propose two effective strategies to mitigate data contamination concerns. Using ScienceAgentBench, we evaluate five open-weight and proprietary LLMs, each with three frameworks: direct prompting, OpenHands CodeAct, and self-debug. Given three attempts for each task, the best-performing agent can only solve 32.4% of the tasks independently and 34.3% with expert-provided knowledge. In addition, we evaluate OpenAI o1-preview with direct prompting and self-debug, which can boost the performance to 42.2%, demonstrating the effectiveness of increasing inference-time compute but with more than 10 times the cost of other LLMs. Still, our results underscore the limitations of current language agents in generating code for data-driven discovery, let alone end-to-end automation for scientific research.
翻译:大型语言模型(LLM)的进展激发了人们日益增长的兴趣,即开发基于LLM的语言智能体以实现端到端的自动化科学发现,这既引发了对其真实能力的兴奋,也带来了质疑。在本工作中,我们呼吁在对端到端自动化做出大胆断言之前,先对智能体在科学工作流中的各项具体任务进行严谨评估。为此,我们提出了ScienceAgentBench,一个用于评估数据驱动科学发现语言智能体的新基准。为确保基准的科学真实性与现实相关性,我们从四个学科的44篇同行评审出版物中提取了102项任务,并邀请九位领域专家对其进行验证。我们将每项任务的目标输出统一为自包含的Python程序文件,并采用一系列评估指标来检查生成的程序、执行结果与成本。每项任务均经过标注者与领域专家的多轮人工验证,以确保其标注质量与科学合理性。我们还提出了两种有效策略以缓解数据污染问题。利用ScienceAgentBench,我们评估了五个开源与闭源LLM,每个模型采用三种框架:直接提示、OpenHands CodeAct以及自我调试。在每项任务允许三次尝试的条件下,表现最佳的智能体仅能独立解决32.4%的任务,在专家提供知识的情况下可解决34.3%。此外,我们评估了OpenAI o1-preview的直接提示与自我调试模式,其性能可提升至42.2%,这证明了增加推理时计算的有效性,但其成本是其他LLM的十倍以上。尽管如此,我们的结果凸显了当前语言智能体在生成数据驱动发现代码方面的局限性,更不用说实现科学研究的端到端自动化。