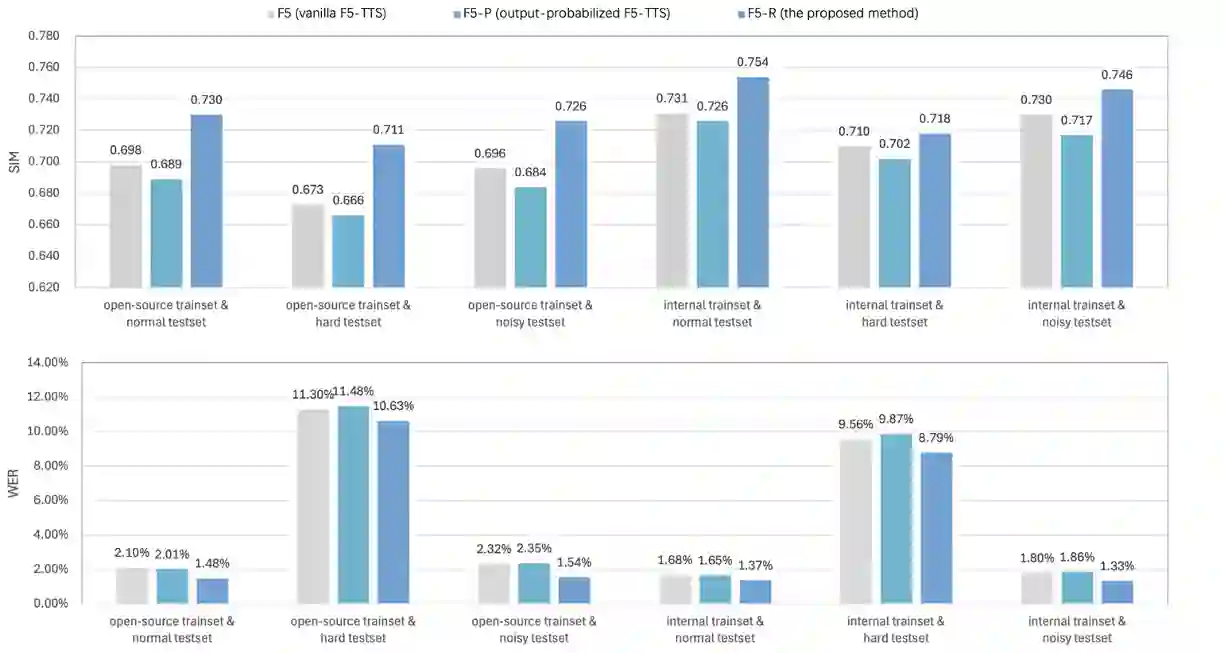
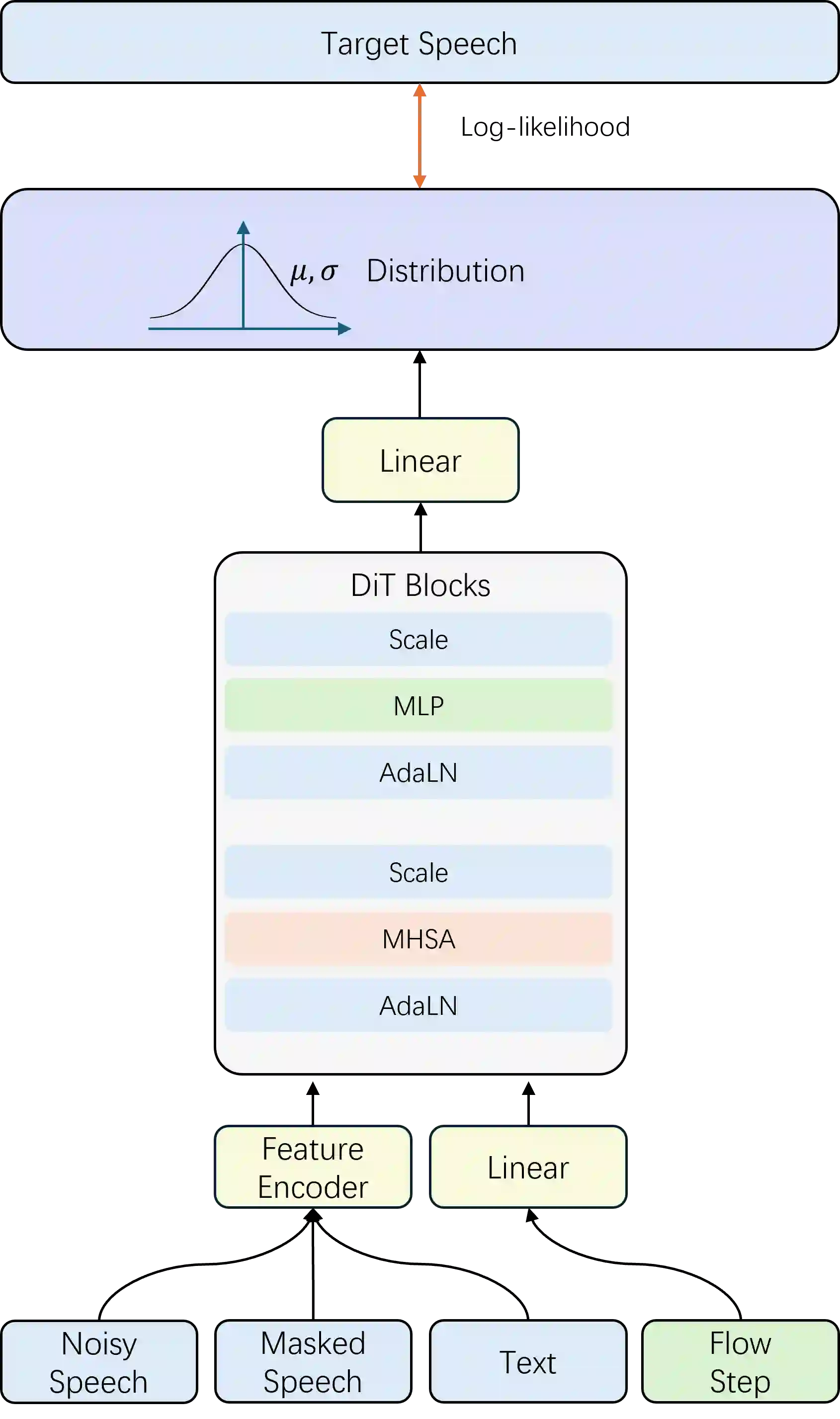
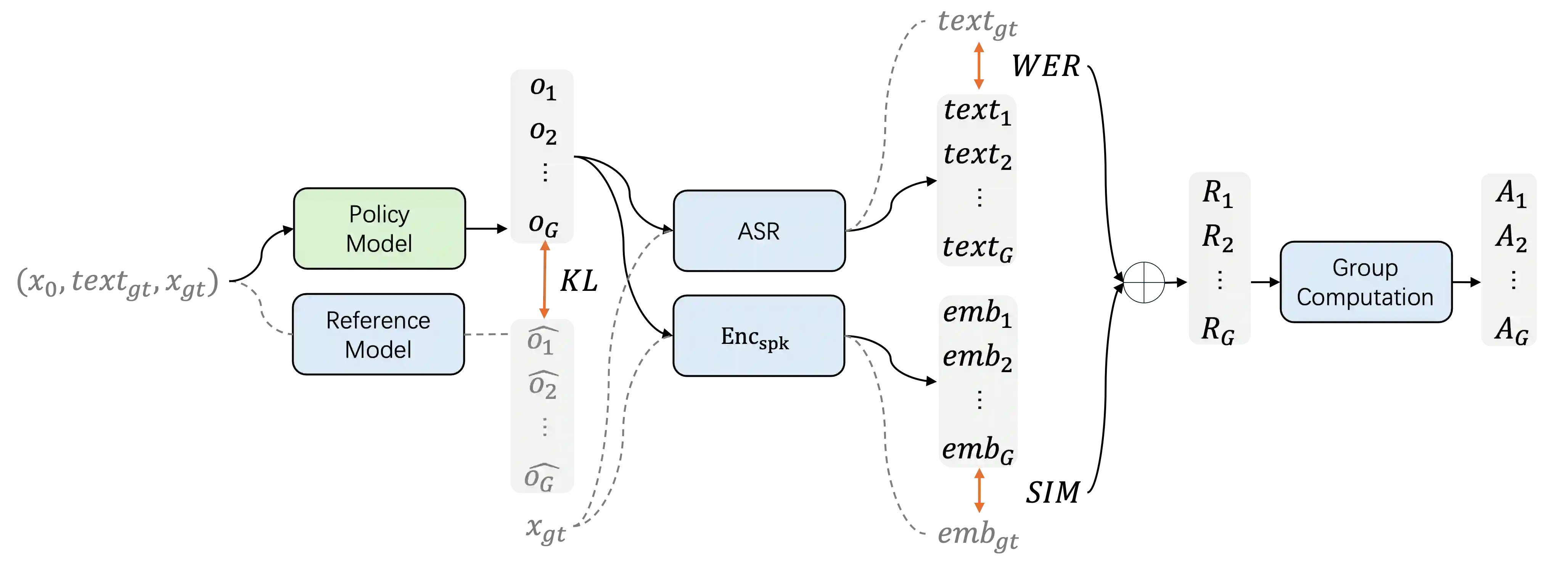
We present F5R-TTS, a novel text-to-speech (TTS) system that integrates Gradient Reward Policy Optimization (GRPO) into a flow-matching based architecture. By reformulating the deterministic outputs of flow-matching TTS into probabilistic Gaussian distributions, our approach enables seamless integration of reinforcement learning algorithms. During pretraining, we train a probabilistically reformulated flow-matching based model which is derived from F5-TTS with an open-source dataset. In the subsequent reinforcement learning (RL) phase, we employ a GRPO-driven enhancement stage that leverages dual reward metrics: word error rate (WER) computed via automatic speech recognition and speaker similarity (SIM) assessed by verification models. Experimental results on zero-shot voice cloning demonstrate that F5R-TTS achieves significant improvements in both speech intelligibility (relatively 29.5\% WER reduction) and speaker similarity (relatively 4.6\% SIM score increase) compared to conventional flow-matching based TTS systems. Audio samples are available at https://frontierlabs.github.io/F5R.
翻译:我们提出了F5R-TTS,一种新颖的文本转语音系统,它将梯度奖励策略优化集成到基于流匹配的架构中。通过将流匹配TTS的确定性输出重新表述为概率性高斯分布,我们的方法实现了与强化学习算法的无缝集成。在预训练阶段,我们使用开源数据集训练了一个基于概率化重述的流匹配模型,该模型源自F5-TTS。在随后的强化学习阶段,我们采用了一个由GRPO驱动的增强阶段,该阶段利用了双重奖励指标:通过自动语音识别计算出的词错误率以及通过验证模型评估的说话人相似度。在零样本语音克隆上的实验结果表明,与传统的基于流匹配的TTS系统相比,F5R-TTS在语音清晰度和说话人相似度上均取得了显著提升。音频样本可在 https://frontierlabs.github.io/F5R 获取。