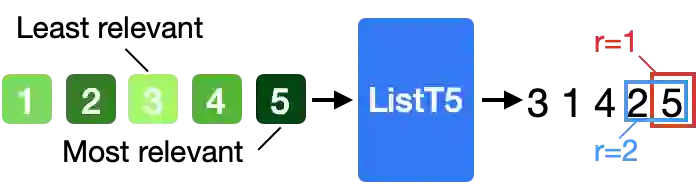
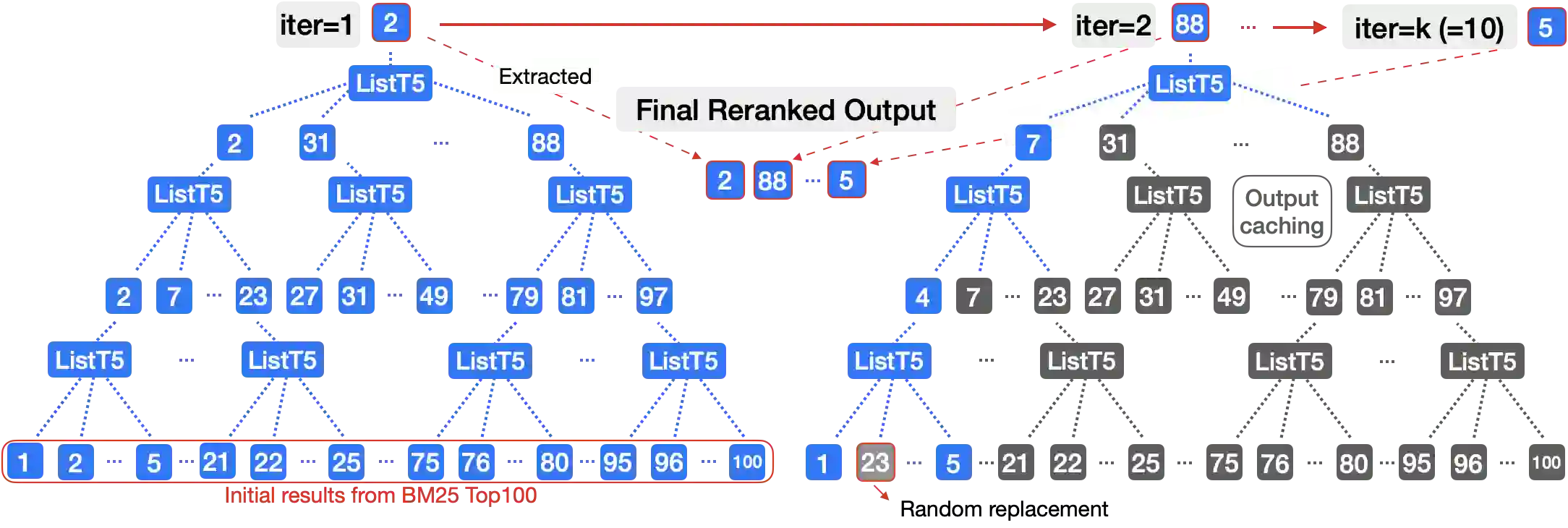
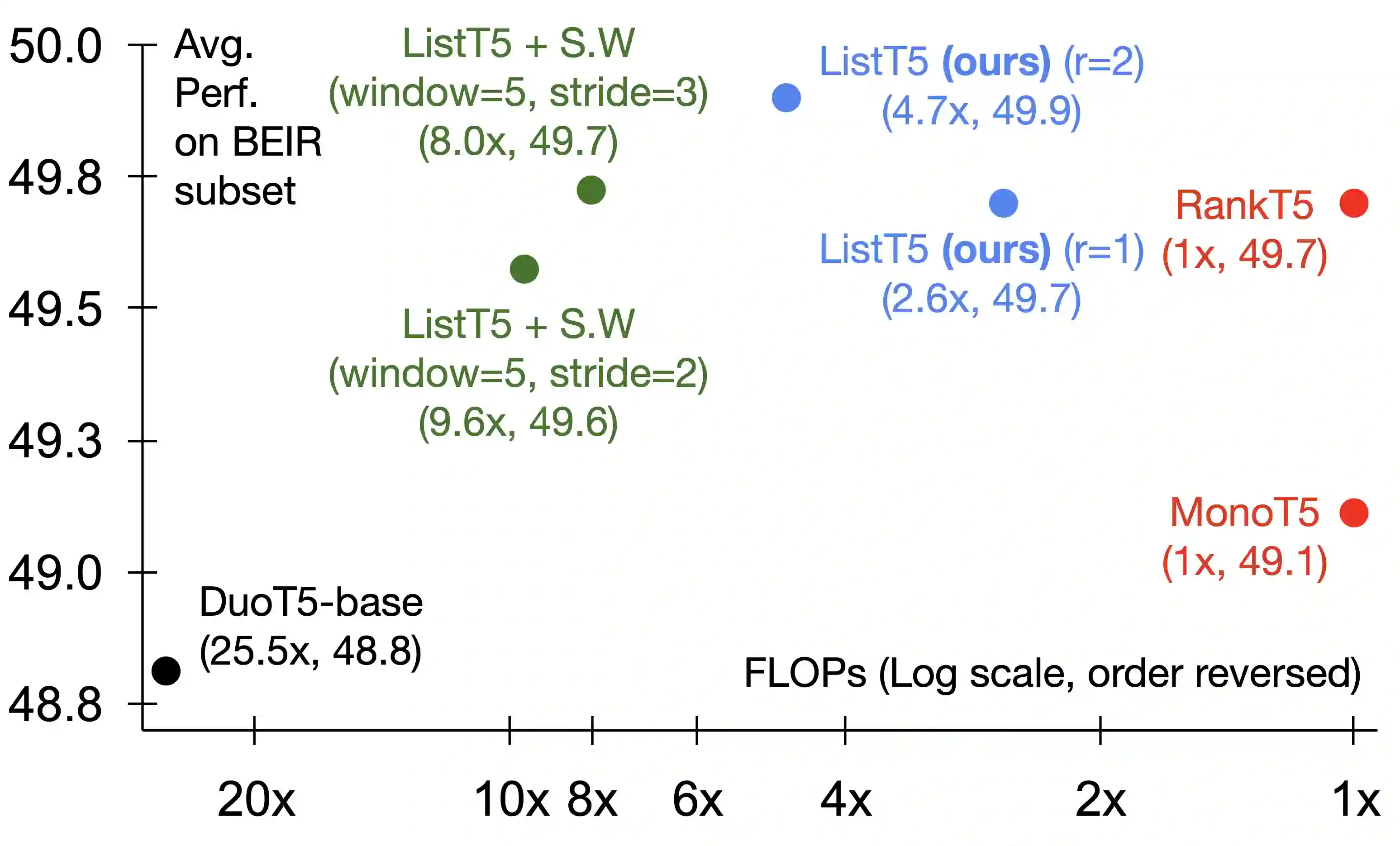
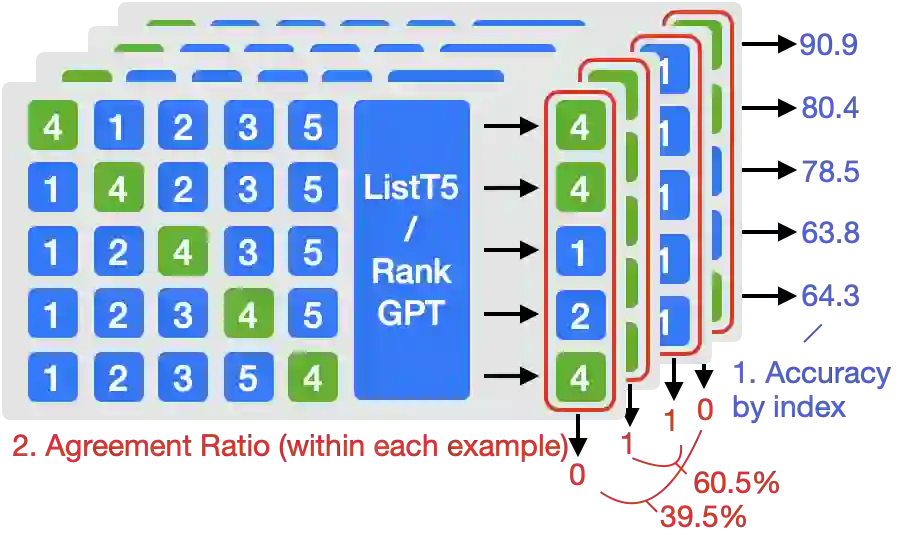
We propose ListT5, a novel reranking approach based on Fusion-in-Decoder (FiD) that handles multiple candidate passages at both train and inference time. We also introduce an efficient inference framework for listwise ranking based on m-ary tournament sort with output caching. We evaluate and compare our model on the BEIR benchmark for zero-shot retrieval task, demonstrating that ListT5 (1) outperforms the state-of-the-art RankT5 baseline with a notable +1.3 gain in the average NDCG@10 score, (2) has an efficiency comparable to pointwise ranking models and surpasses the efficiency of previous listwise ranking models, and (3) overcomes the lost-in-the-middle problem of previous listwise rerankers. Our code, model checkpoints, and the evaluation framework are fully open-sourced at \url{https://github.com/soyoung97/ListT5}.
翻译:我们提出ListT5,一种基于Fusion-in-Decoder(FiD)的新型重排序方法,能够在训练和推理阶段同时处理多个候选段落。我们还引入了一种基于m元锦标赛排序及输出缓存的列表式排序高效推理框架。我们在BEIR基准上对零样本检索任务进行了评估与对比,结果表明ListT5:(1)在平均NDCG@10分数上以+1.3的显著优势超越当前最优的RankT5基线模型;(2)在效率上与逐点排序模型相当,并超越以往列表式排序模型的效率;(3)克服了过往列表式重排序中的"中间信息丢失"问题。我们的代码、模型检查点及评估框架已在\url{https://github.com/soyoung97/ListT5}完全开源。