
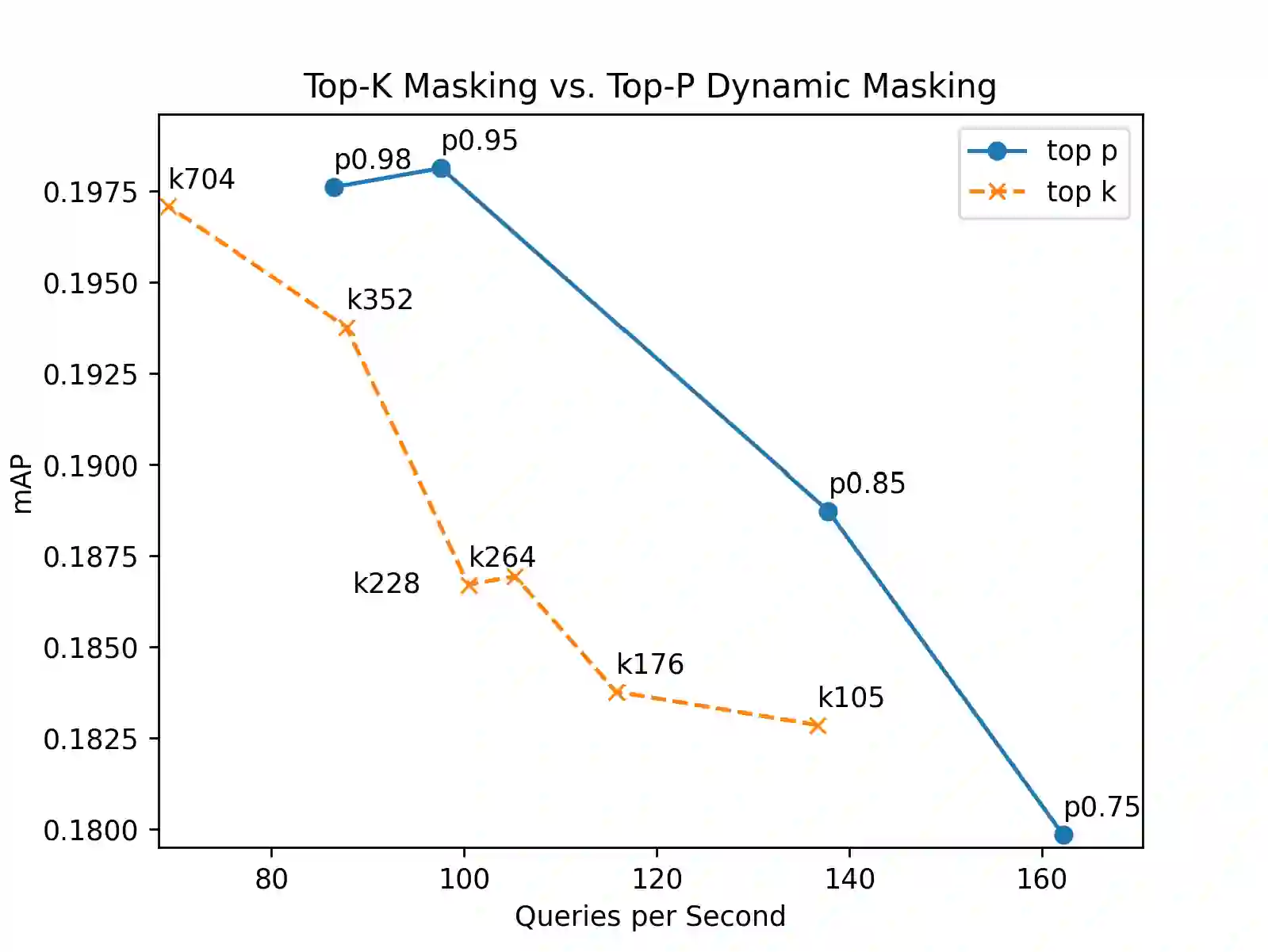
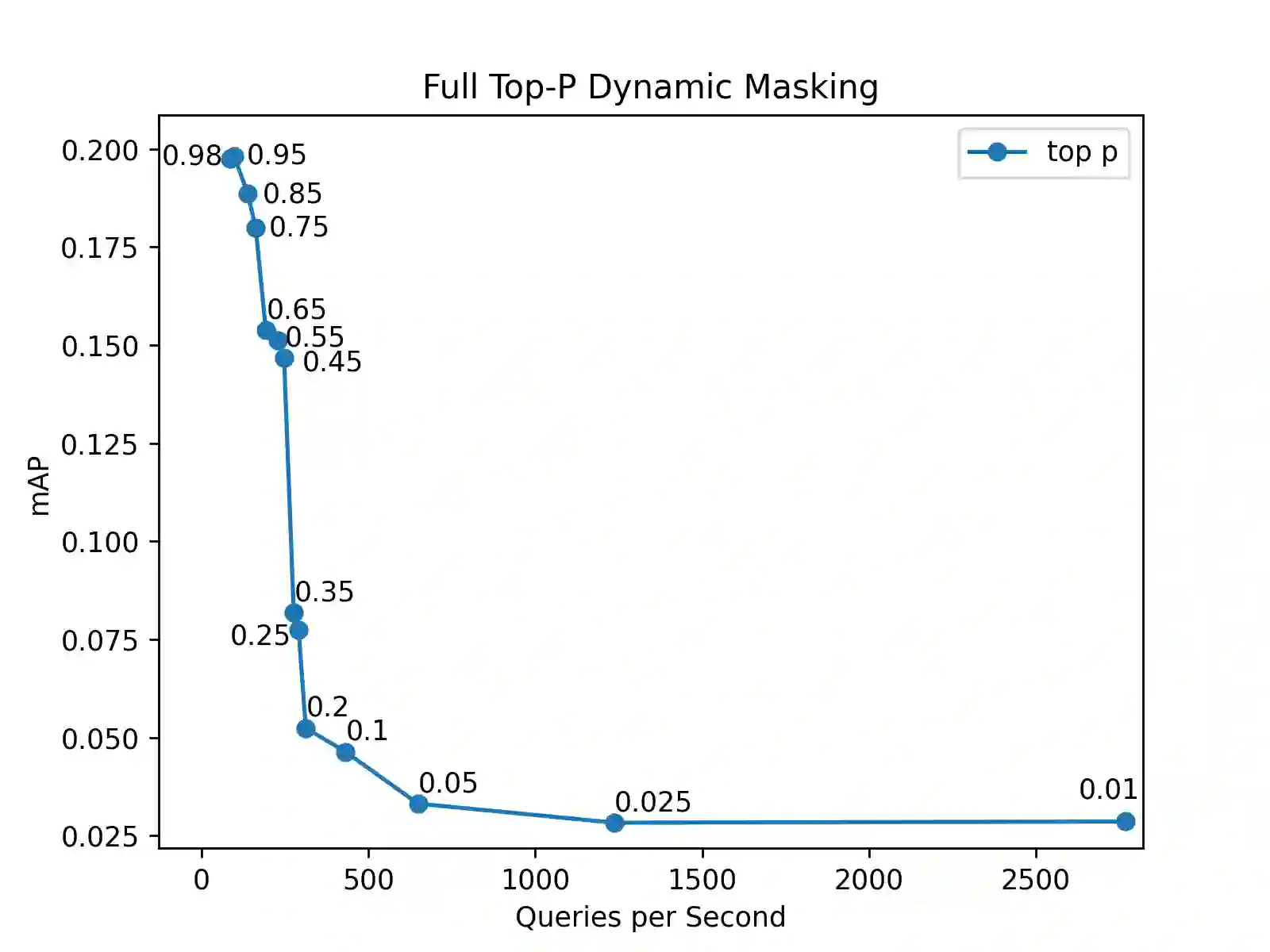
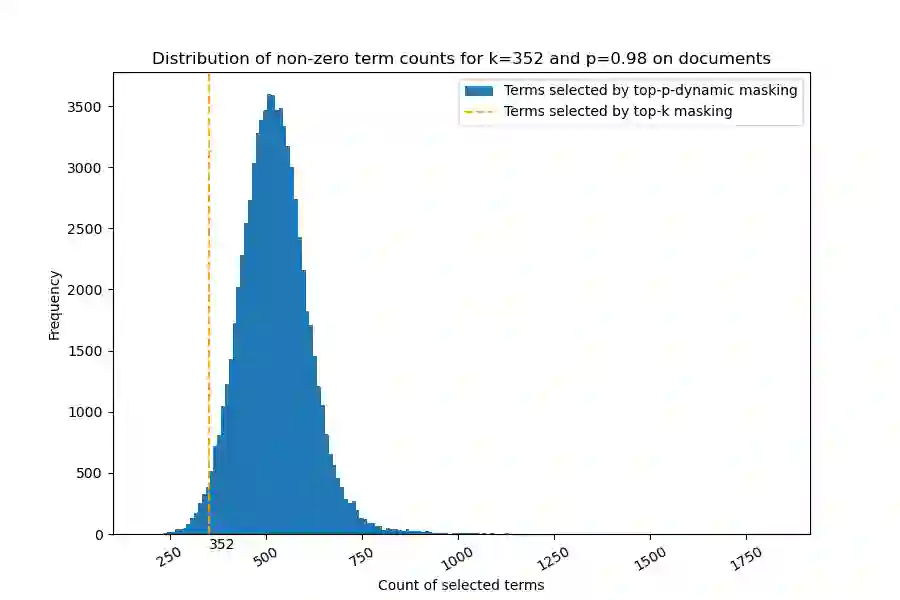
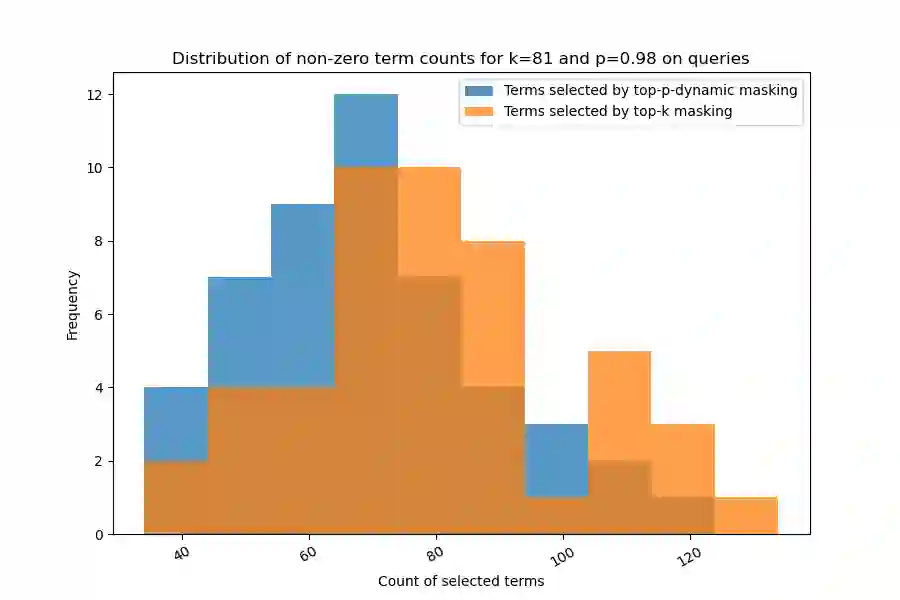
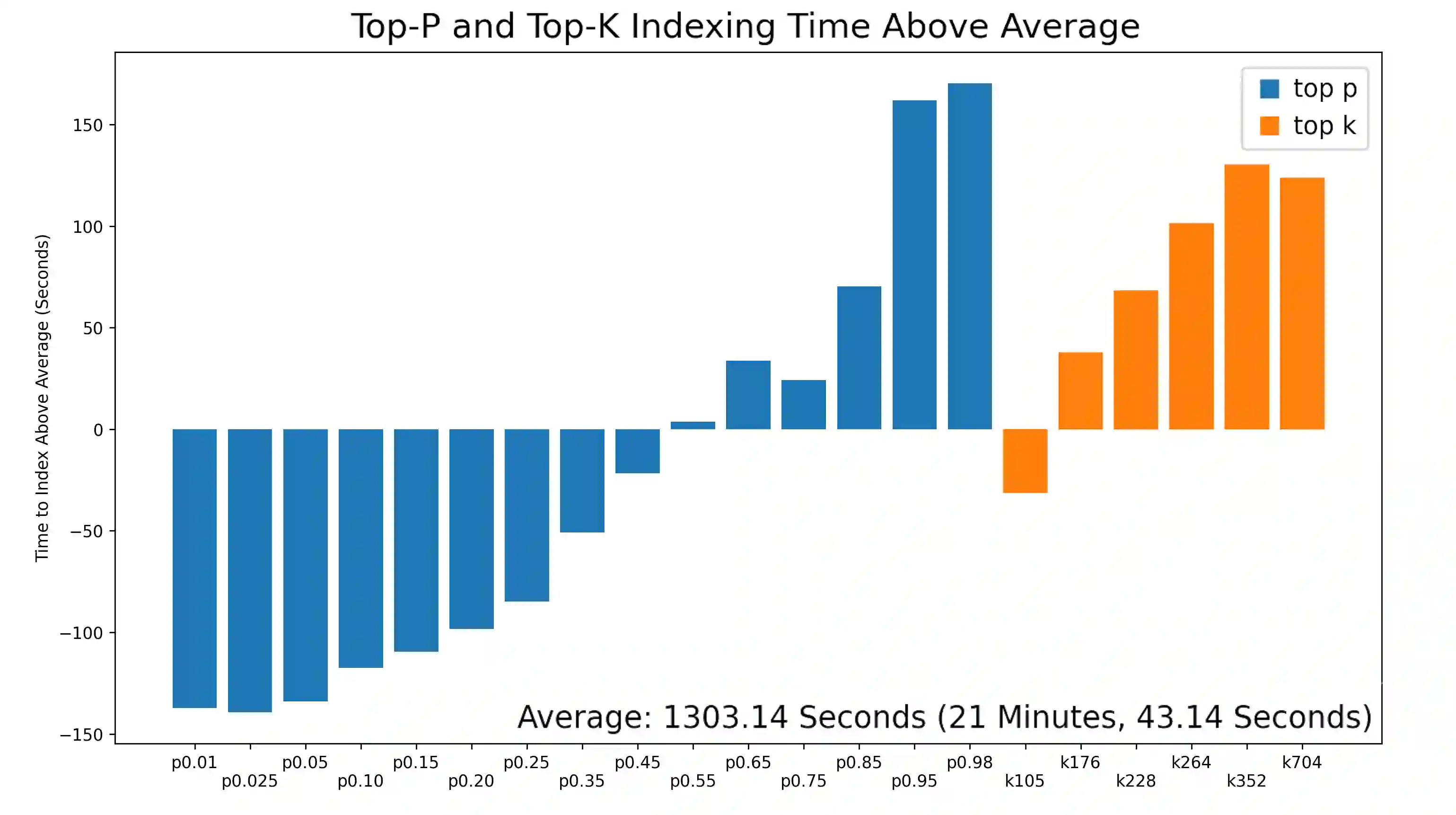
Top-K masking schemes have been proposed as a method to promote sparse representations in Information Retrieval (IR) tasks, as a simple alternative to Floating Point Operations per Second (FLOPS) regularization. Algorithms such as Bilingual Lexical and Document Expansion Model (BLADE), adopt this approach as a post-processing stage. We propose using Top-P Dynamic Masking similar to Nucleus Sampling in Large Language Models, and demonstrate better performance than Top-K masking. Specifically, we evaluate our methods in the domain of Cross Language Information Retrieval (CLIR)
翻译:Top-K掩码方案已被提出作为信息检索任务中促进稀疏表示的一种方法,是替代每秒浮点运算正则化的简单方案。诸如双语词汇与文档扩展模型等算法采用此方案作为后处理阶段。我们提出使用类似于大语言模型中核采样的Top-P动态掩码方法,并证明其性能优于Top-K掩码。具体而言,我们在跨语言信息检索领域评估了所提方法。
相关内容

专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
Arxiv
10+阅读 · 2021年2月22日



最新内容
相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯
相关论文
Arxiv
10+阅读 · 2021年2月22日